A few weeks ago, we conducted hour-long conversations with 10 of our users to dig deep into how you manage your preferences and configurations in Thunderbird desktop. While this specific research cycle focused on the desktop experience, our ultimate goal is a holistic strategy that ensures our mobile settings feel like a natural extension of your workspace.
Here is a quick look at what we discovered, what you valued, and how your feedback is actively shaping our design roadmap.
What you told us
You are incredibly passionate about customization, and appreciate Thunderbird’s robust functionality. Overall, a common thread that stood out was that most of you want to set up your space once and then make small tweaks to your preferences, you want it to look modern, and navigate effortlessly without running into issues with technical jargon.
Here are the key themes that emerged from our conversations:
Ecosystem trust: Your commitment to Thunderbird is rooted in a deep trust for open-source software, the Mozilla brand, absolute transparency, and reliability.
Set and forget: You customize extensively during your initial setup, followed only by minor tweaks to get your workspace just right.
Clutter & noise: There is a strong desire to reduce workspace clutter and the cognitive “noise” within dense configuration menus.
Search to navigate: While deep navigation menus can feel hard to find your way through, an in-app search function is your go-to for finding what you need quickly.
The “inbox as a to-do list” workflow: Many of you don’t just read mail, you actively treat your unread inbox as a task list or interactive to-do queue.
Terminology barriers: Even for advanced users, many settings feel overly technical, which causes hesitation when you’re trying to explore your options.
Improvements we want to make
We don’t want to just make minor fixes, we want to design a better workflow. Based on your feedback, here are the core design actions that will be driving our next phase focusing on general and account settings:
Demystify the language: We are planning to replace confusing technical terminology with plain, clear language, so you always know exactly what each function does.
Streamline information architecture: We are regrouping settings into logical, task-oriented categories to make manual navigation smooth and intuitive.
Bring context to privacy & security: Instead of a flat list of checkboxes, we want to add clear explanations around data security and defaults so you can make confident, informed decisions.
Functionality meets modern UI: Thunderbird’s robust functionality is its superpower, but a dated interface shouldn’t be a barrier to entry for newer users.
Accessibility update: Based on a community member’s recent audit, we are also taking this opportunity to improve the overall accessibility of the settings experience.
What’s next?
We are hitting the ground running with these insights. Right now, our team is actively:
Finalizing our project scope to directly incorporate these research findings.
Mapping out and proposing a streamlined information architecture for settings.
Designing this layout holistically so that desktop preferences and mobile configurations
A massive thank you to everyone who offered their time and feedback for this study! We look forward to sharing more with you soon.
Each year, Mozilla welcomes interns who work alongside our engineering teams on projects that ship to production and improve the experience for contributors around the world. This year, Ayush joined the Firefox Localization team to work on Pontoon, Mozilla’s open source localization platform, where he already tackled several user-facing improvements while learning how large-scale open source software is built.
In this post, Ayush shares the story behind one of his first projects: giving Pontoon’s translation editor its own appearance settings. From understanding long-standing design decisions to balancing accessibility with user expectations, he walks through both the technical implementation and the product thinking that shaped the feature.
You can follow Ayush’s work on GitHub and connect with him on LinkedIn.
I joined Mozilla’s Firefox Localization (l10n) team as part of Mozilla Corporation’s Firefox Desktop Engineering Team, based in Downtown Toronto. I officially began my internship on Friday, May 1, 2026, but I unofficially began in mid February. Since my team’s flagship product’s (Pontoon) codebase is entirely open source, I talked to both my manager and Pontoon owner right after signing my offer and got early access to our weekly meetings and some confidential data. I then started to learn as much as I possibly could.
Even before I started learning the codebase, just looking at the Pontoon’s default translation UI was rather interesting because of our editor pane’s glaring white color in dark mode/theme.
Even though I saw the issue (#4001) filed for working on that, I thought that the stark contrast was a stylistic choice because an average user would spend most of their time on said pane editing strings anyway, so I just went on with it.
However, once I officially started to work, I got my onboarding document and saw my starting set of issues. That’s where I came across the very same issue (#4001) on my todo batch, which made me very happy since I could address it and I’d already looked at the surrounding context before working with it.
The Original Experience
At first, the user could only change Pontoon’s appearance from their `profile menu` or Pontoon’s `/settings` page. This is where they have the ability to change their appearance to `dark mode`, `light mode`, or keep the `system theme` that matches their device’s preferences.
This is the view from Pontoon’s Settings page.
This is the view from Pontoon’s Profile menu.
Ironically, the dark appearance warrants a light themed `editor pane`.
There is also no option to change the `editor pane` appearance from the `editor menu`.
Design Considerations
In general, when a product has a large, established user base that has grown accustomed to a particular interface, it’s important to approach visual changes with care. Even if a redesign is arguably more visually appealing and offers clear accessibility benefits, changing familiar workflows and appearance can still disrupt the user experience.
In fact, according to this Mozilla Research article I read, which explored browser choice design interventions, “It is important that the organizations tasked with designing and regulating current and future interventions (including browser choice screens) are mindful of the design principles we have articulated with this research.”
Even though the relevance of said research is for the browser use-case, the impacts are for a user interface design like in this blog, as the article also mentions “The inertia is a strong force to overcome”, and Pontoon’s inertia dates back over a decade.
This meant that if we were to change the editor pane color, we would have to allow the user to have things as they currently are.
The New Experience
In the update Appearance section of the Settings page, users have the ability to change the main interface as before, but now have the ability to update editor to `dark mode`, `light mode`, or match their `main interface theme` to automatically sync the colors.
The editor theme remains light by default, regardless of the main interface theme.
This is the view from Pontoon’s Settings page.
Editor appearance can also be quickly changed from the editor menu.
This UI now matches the dark theme, either by explicitly selecting it or matching the main interface theme.
Since the issue was with `dark interface mode` having a `light editor`, setting the default `editor` to `light` neatly agreed with how the UI looked before the changes were brought in.
Looking Ahead
These changes neatly allow the user to modify their theme keeping their general preferences in mind. The change is also remembered by Pontoon and stays consistent at every instance the user logs back in.
Furthermore, we now track if the user has interacted with the `editor theme` which gives us knowledge on if we want to eventually change the default editor theme, addressing the concerns of `UI inertia` brought up in Mozilla’s research.
Hi Mozillians, welcome to another Mozilla community roundup!
This month, we’re taking a look at what’s next for Firefox. From an upcoming visual refresh and a peek behind the new design system to hidden features you may never have used before. We’re also highlighting a recent Reddit AMA on the new Firefox product Roadmap and celebrating community contribution that’s making collaboration in Pontoon even better.
Let’s dive in!
✨ Firefox gets a fresh new look. Soon!
Firefox is evolving with a refreshed design that makes the browser feel more modern, approachable, and consistent across desktop and mobile. The refresh also extends to Firefox’s voice and writing style, making product experience feel more human, direct, and unmistakably Firefox. If you’re excited about these changes, make sure to keep an eye out for an upcoming foxfooding opportunity later this month!
Sreenath from It’s FOSS rounded up 21 Firefox features that many users never discover. From the built-in Eyedropper tool and Picture-in-Picture to vertical tabs and other productivity features, there’s plenty to explore. See how many you’ve already used! We could even turn it into a fun bingo at our next community event.
Firefox leaders recently joined r/firefox for a live AMA to answer questions about the newly launched Firefox Product Roadmap. Community members asked about everything from Android improvements and Containers to Project Nova, PWAs, performance, and future browser development. The conversation generated a wide range of discussions and provided valuable insight into what Firefox users are most excited, and concerned, about.
Collaboration in Pontoon just got a little easier. Thanks to volunteer contributor Serah Nderi, users can now edit and delete their own comments, while project managers can remove comments for moderation purposes. This long-requested feature helps reduce clutter, improve discussions, and makes collaboration smoother for localization teams.
During London Tech Week, Mozilla hosted the first UK edition of Mozilla Mornings, our breakfast-discussion series on the digital questions of the moment. We brought together technologists, policymakers, industry, civil society and researchers to ask how the UK can drive forward responsible innovation in privacy-enhancing technologies (PETs) in ways that protect people, strengthen trust and keep digital markets open.
The role of PETs in building a better internet
Protecting people’s privacy has always been central to Mozilla’s mission to build a better internet – one where privacy and security are fundamental, people have meaningful control over their data and online lives, and independent actors can compete on a level playing field. Privacy-enhancing technologies (PETs) are an important part of that vision. They help minimise the amount of personal data that needs to be collected and processed while enabling useful functionality. In Firefox, this work includes technologies such as Oblivious HTTP, differential privacy, the Distributed Aggregation Protocol and DNS over HTTPS.
PETs encompass a broad family of technical, architectural and product-design approaches where data analysis, measurement, collaboration, access and computation happen with lower privacy risk.
Advancing both privacy and competition together is key to a healthier internet ecosystem. Advertising illustrates both the challenge and the opportunity. It keeps most of the web free and accessible, but today’s dominant model leans on hidden data collection and opaque systems that work around people rather than with them. Solutions that simply hand more data, more infrastructure or more decision-making power to a handful of large companies do not fix that.
Importantly, PETs should not be viewed as a way to bypass privacy rules. Their value lies in reducing the amount of personal data that needs to be collected, shared or processed in the first place, while preserving useful functionality where appropriate. That is why we have been investing in and building around privacy-preserving advertising, recognising that PETs are not a silver bullet but an important part of a better model.
Responsible deployment of PETs depends not only on the technical design, but also on the governance, assurance, and market context around it. PETs should be grounded in open standards and interoperable architectures. Otherwise, they risk reinforcing walled gardens, limiting choice or creating new dependencies rather than supporting a more open and competitive ecosystem.
The discussion
The event opened with remarks from the Information Commissioner’s Office (ICO). This included the ICO’s work on PETs, online tracking, privacy-preserving attribution and the questions raised under Regulation 6 of the Privacy and Electronic Communications Regulations (PECR). Shortly before the event, the ICO had published advice to the government on possible online advertising exceptions to Regulation 6 PECR. As we set out in our submission to the ICO’s call for views on online advertising, we support reform that incentivises privacy-preserving practices while keeping consent the default for high-risk practices.
Gijs Kruitbosch, Principal Engineer at Mozilla, then gave a technical demonstration of how Mozilla uses PETs and privacy-preserving design in Firefox, including on New Tab, where relevance can be improved through approaches that reduce reliance on user identifiers and server-side user profiles.
The panel, moderated by Mozilla’s Kirsten Nelson-de Búrca, widened the lens well beyond advertising. Speakers from eyeo, OpenMined, the Open Data Institute and the Information Society Law Centre discussed how PETs are governed and used across sectors, and how their deployment could affect competition as well as privacy. The discussion explored public-interest examples, including federated rare-disease and genomic research that lets analysis happen without data leaving an institution or a country, and emerging routes for external researchers to study platform data.
A recurring theme was that successful deployment depends as much on governance and public trust as it does on mathematics. PETs have the potential to reduce the competitive advantages associated with large-scale personal data collection, but they could also entrench incumbents if the relevant infrastructure is closed, proprietary or expensive to audit. The discussion complicated the familiar trade-off between privacy and competition, arguing that it eases when PETs are built in the open, on shared standards, with interoperable and auditable implementations and real routes for smaller players and new entrants to take part.
What comes next
The most important questions were the ones we left without tidy answers. Who gets to set standards, and are they set in the open? How do smaller players actually participate, rather than being told they may? What forms of assurance or audit are needed before policymakers can rely on privacy claims? And how should PETs be built into the next generation of AI, where the most sensitive data and the strongest case for protection often sit together? These are the questions we want to keep working on with those who joined us and the wider community.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at
@thisweekinrust.bsky.social on Bluesky or
@ThisWeekinRust on mastodon.social, or
send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a
call-for-testing label to your RFC along with a comment providing testing instructions and/or
guidance on which aspect(s) of the feature need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
I do rather hope anyone using -Zllvm-target-features or any stabilized form thereof would know that they are getting a conversation with the dragon directly and they should mind their words carefully if they do not wish to be barbecued by it and served over a nice plate of iron filings.
performance.measure() with mark values ‘redirectStart’, ‘redirectEnd’, ‘secureConnectionStart’, and ‘responseEnd’ (@shubhamg13, #44673, #44624, #44850, #44739)
Servo’s JS runtime, SpiderMonkey 140.10.0, had several memory safety bugs that have been fixed in Servo 0.3.0 with the update to SpiderMonkey 140.10.1 (@jschwe, #44755).
For more details, see CVE-2026-7322, CVE-2026-7323, and MFSA 2026-36.
Work in progress
We’re continuing to implement document.execCommand() for rich text editing, under --pref dom_exec_command_enabled (@TimvdLippe, #44735, #44973, #44887).
This release adds support for the ‘backColor’, ‘foreColor’, ‘createLink’, ‘unlink’, ‘superscript’, ‘subscript’, and ‘removeFormat’ commands (@TimvdLippe, #44644, #44682, #44657, #44710, #44677), plus partial support for the ‘insertParagraph’ command (@TimvdLippe, #44909).
We’re also working on the Sanitizer API, under --pref dom_sanitizer_enabled.
With the feature now enabled in servoshell’s experimental mode (@kkoyung, #44701), this release adds support for setComments(), setDataAttributes(), allowProcessingInstruction(), removeProcessingInstruction(), and removeUnsafe() on Sanitizer (@kkoyung, #44734, #44983).
IndexedDB continues to improve, under --pref dom_indexeddb_enabled.
This release brings a more conformant abort() on IDBTransaction (@Taym95, #43950).
All of the features above are enabled in servoshell’s experimental mode.
We’re now working on SharedWorker and ServiceWorker, under --pref dom_sharedworker_enabled and --pref dom_serviceworker_enabled respectively.
This release adds support for new SharedWorker() (@Taym95, #44761), and parts of the ServiceWorker API (@gterzian, @arihant2math, #45082, #44787).
Embedding API
Servo now requires Rust 1.88.0 or newer, up from the old MSRV of 1.86.0 (@sagudev, #44815).
We run compile tests with the MSRV, but most of our testing is now done with Rust 1.95.0 (@simonwuelker, #44632).
SiteDataManager::clear_cookies now takes an additional callback argument, allowing it to be called async – to continue calling it sync, pass None as the callback
SiteDataManager::clear_session_cookies now takes an additional callback argument, allowing it to be called async – to continue calling it sync, pass None as the callback
SiteDataManager::set_cookie_for_url now takes an additional callback argument, allowing it to be called async – to continue calling it sync, pass None as the callback
SiteDataManager::set_cookie_for_url_async has been removed in favour of set_cookie_for_url – to migrate, replace set_cookie_for_url_async(callback) with set_cookie_for_url(Some(Box::new(callback)))
threadpools_image_cache_workers_max, threadpools_indexeddb_workers_max, and threadpools_webstorage_workers_max have been removed in favour of a combined thread_pool_workers_max
Each option is a variant of DiagnosticsLoggingOption, a new type that also has useful methods for exposing these options in embedder UI
(Breaking change)DiagnosticsLogging no longer has pub fields representing each option – to migrate, replace field writes and field reads with toggle_option and is_enabled respectively
(Breaking change)DiagnosticsLogging::extend_from_string no longer accepts a help option – this option only existed to support servoshell’s -Z help / --debug=help option, so the code implementing it has been moved to servoshell
For users and developers
servoshell has two new options:
You can now configure the path to a hosts file with --host-file= (singular), as an alternative to the HOST_FILE (singular) environment variable (@jschwe, #44880).
You can now provide a directory of user scripts to run in every document with --userscripts= (@jdm, #44754).
When using the Debugger tab in the Firefox DevTools:
You can now “blackbox” a script by clicking Ignore source (@freyacodes, #44359).
This prevents breakpoints from being hit inside that script, and it should also allow you to step through execution in the debugger without pausing inside that script.
For developers of Servo itself, please note that per project policy, you must not use the output of large language models or other generative AI tools in your contributions.
To help us enforce that, we now have CI checks that reject AI agents as coauthors (@SimonSapin, @delan, #44723).
Servo now requires fewer OS threads per CPU, after we combined the thread pools for the image cache, web storage, and IndexedDB (@Narfinger, @mrobinson, #44307).
We’ve landed a bunch of layout optimisations:
The fragment tree is now immutable for the most part, with small pockets of interior mutability where mutability is needed.
This means that most fragment tree accesses no longer have to incur the runtime cost of borrowing an AtomicRefCell (@mrobinson, @Loirooriol, #44849).
Two steps in the layout process, calculating containing blocks and building the stacking context tree, require traversing the fragment tree.
This can be expensive, but we’ve now combined them into a single fragment tree traversal in most cases (@SimonSapin, @mrobinson, #44911, #45210).
Another step in the layout process, calculating scrollable overflow, used to require traversing the entire fragment tree.
We’ve effectively eliminated that traversal, by making the calculation both lazy and incremental (@mrobinson, @Loirooriol, #44854).
DOM attributes are much more efficient in this release:
When scripts write attribute values, we avoid serialising them until the attribute is read back by a script (if ever), speeding up frequent writes to inline styles by up to 25% (@mrobinson, #44931).
We’ve eliminated a traversal of the whole DOM tree whenever an <iframe> is attached to the tree, which is especially noticeable when parsing documents with many <iframe> tags (@mrobinson, #45236).
To improve Servo’s build times, we’re moving more code out of our massive script crate (@Narfinger, @jdm, #44598, #44636, #44823), and reduced the size of our dependency tree (@jschwe, #44818).
Interested in helping build a web browser?
Take a look at our curated list of issues that are good for new contributors!
Donations
Thanks again for your generous support!
We are now receiving 7659 USD/month (+4.2% from April) in recurring donations.
This helps us cover the cost of our speedyCIandbenchmarkingservers, one of our latest Outreachy interns, and funding maintainer work that helps more people contribute to Servo.
Servo is also on thanks.dev, and already 35 GitHub users (+2 from April) that depend on Servo are sponsoring us there.
If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
We now have sponsorship tiers that allow you or your organisation to donate to the Servo project with public acknowlegement of your support.
If you’re interested in this kind of sponsorship, please contact us at join@servo.org.
The Rust team has published a new point release of Rust, 1.96.1. Rust is a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, getting Rust 1.96.1 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the appropriate page on our website.
Mozilla remains committed to maintaining a secure, trustworthy, and transparent Web PKI. Today we are announcing the publication of Mozilla Root Store Policy (MRSP) version 3.1, effective July 1, 2026.
While previous policy updates focused heavily on certificate revocation, automation, and operational resilience, MRSP v3.1 focuses on a different challenge: ensuring that Certification Authority (CA) operations are sufficiently transparent, understandable, and auditable.
Trust in the Web PKI depends not only on technical requirements, but also on the ability of Mozilla, auditors, and the broader community to understand how CA systems are designed, operated, and assessed. MRSP v3.1 introduces new requirements intended to improve the quality of CA documentation and strengthen independent assurance of the design and effectiveness of controls that protect CA systems.
Improving CP/CPS Documentation
Certification Practice Statements (CPSes) and combined Certificate Policy / Certification Practice Statement documents (CP/CPSes) are among the most important public documents published by a CA. They describe how a CA conducts its operations and meets industry requirements.
Over the years, we have seen significant variation in the quality, structure, and level of detail provided in CP/CPS documentation. Some documents provide extensive implementation detail, while others rely heavily on incorporation by reference or provide only high-level descriptions of CA practices.
The revised policy will continue to require conformance with RFC 3647, as modified by applicable CA/Browser Forum requirements. Improvements to section 3.3 in the MRSP will establish clearer expectations regarding the content and quality of CP/CPS documentation. The new requirements emphasize that documentation must be explicit, bounded, auditable, and sufficiently detailed to describe the CA operator’s certificate issuance and management activities, while also establishing requirements for version control, accessibility, and ongoing maintenance. The objective is to ensure that a technically competent reviewer will be better-able to determine what commitments the CA has made, how those commitments are implemented, and whether the documented practices support technical, operational, and performance oversight.
Mozilla believes that these new CP/CPS requirements will improve transparency, reduce misunderstandings, support more effective audits, and help reduce the risk of certificate misissuance by ensuring that operational practices are documented accurately, consistently, and in sufficient detail to permit meaningful review.
Introducing Detailed Controls Reports
A second major enhancement in MRSP v3.1 is the introduction of Detailed Controls Reports (DCRs). Traditional WebTrust and ETSI audit reports provide valuable independent assurance regarding compliance with established criteria. However, they generally provide only limited visibility into the specific controls, testing procedures, and operational environments that support those conclusions.
Beginning with audit periods starting on or after July 1, 2027, CA operators with root certificates enabled for TLS website authentication will be required to obtain a DCR. The purpose of the DCR is to provide CA management, auditors, and Mozilla with greater visibility into the controls, testing, and operating effectiveness of CA systems that support compliance with the CA/Browser Forum’s TLS Baseline Requirements and Network and Certificate System Security Requirements. Mozilla generally expects to review DCRs only on an as-needed basis, such as during compliance reviews, incident investigations, root inclusion evaluations, or other oversight activities.
A DCR must include:
The scope and boundaries of the audited CA systems;
Applicable audit criteria;
Controls implemented by the CA;
The auditor’s testing procedures;
Results of control testing; and
Information regarding control exceptions or deficiencies.
Mozilla expects that DCRs will complement existing audit reports and strengthen transparency and assurance by providing additional detail regarding system boundaries, control implementation, testing procedures, and control effectiveness that is not typically available in traditional audit reports. Effective compliance requires more than documented policies and successful audits; it also requires management understanding, oversight, and engagement. By providing greater visibility into CA systems, controls, testing activities, and operational risks, DCRs can help reinforce a strong tone at the top regarding compliance expectations, support informed decision-making and resource allocation, enable earlier identification of weaknesses, and promote a culture of continuous improvement. The intent is not to replace existing audit reports, but to provide additional information that supports effective governance, oversight, and informed trust decisions.
Additional Clarifications and Improvements
MRSP v3.1 also includes several targeted clarifications and refinements:
aligns Mozilla’s mass revocation planning requirements with the corresponding CA/Browser Forum Baseline Requirements, helping ensure consistency across compliance frameworks;
clarifies audit expectations for root inclusion requests, including requirements relating to audit continuity and root key generation ceremonies;
requires root CA key pairs submitted for inclusion to have been generated within the previous five years, helping ensure that newly included roots are based on contemporary cryptographic practices and controls; and
clarifies expectations when ownership or operational control of a CA changes, helping ensure that Mozilla receives timely notice and can evaluate the impact of acquisitions or organizational changes on continued compliance.
Looking Forward
Mozilla recognizes that these changes will require preparation by CA operators, auditors, and other ecosystem participants. To support implementation, Mozilla is publishing accompanying wiki guidance regarding both CP/CPS Documentation and Detailed Controls Reports.
As with previous policy updates, these changes were informed by discussions with CA operators, auditors, and members of the Web PKI community. We appreciate the feedback received during the review process and look forward to continued collaboration as the ecosystem evolves.
Mozilla has a longstanding focus on building confidence in the Web PKI through transparency, accountability, and continuous improvement. By requiring higher-quality CP/CPS documentation and strengthening independent assurance, MRSP v3.1 advances Mozilla’s commitment to protecting its users and maintaining their trust in the systems that help secure the web.
Welcome back from the Thunderbird development team!
The past few months have been exceptionally busy across the project. As we approach the midpoint of the year, we’ve been focused on a mixture of delivering user-facing features, investing in long-term architectural improvements, and preparing for the next ESR cycle.
A significant amount of effort has gone into modernizing Exchange support, where the team is now approaching Graph API feature parity with our existing EWS implementation. At the same time, progress has continued on the Account Hub, the Global Message Database, and improvements to the add-ons ecosystem that will help extension developers transition toward a more secure and sustainable future.
Behind the scenes, we’ve also continued the less visible but equally important work of maintaining a large application: adapting to upstream platform changes, improving test reliability, addressing long-standing bugs, and supporting the growing community of contributors who help move Thunderbird forward every day.
This month we’d especially like to recognize one of those contributors, Maxe, whose sustained efforts tackling decades-old MIME bugs have been making a meaningful impact across the codebase.
Exchange Email Support
One of the largest efforts underway in Thunderbird continues to be our modernization of Exchange support.
Over the past several months, the team has pushed through multiple Graph API implementation phases and is now entering the final stretch toward feature parity with our existing EWS implementation. At the time of writing, only a small number of remaining email features separate the two implementations, with completion expected imminently.
Reaching this point has involved considerably more than simply implementing new API calls. The work required substantial investment in shared understanding, protocol abstractions, automated code generation, testing frameworks, request batching, synchronization mechanisms, and interoperability between legacy and modern components. Many of these improvements will continue to benefit future protocol work long after Graph support itself is complete.
A notable development came from our ongoing engagement with Microsoft, and following discussions around Graph API permissions, Microsoft confirmed that approved mail clients such as Thunderbird will continue to be able to obtain user consent for permissions that were previously unavailable to third-party applications. This removed a significant long-term uncertainty around Graph support and helps to ensure Thunderbird users can continue connecting Exchange accounts without requiring administrator intervention.
With email functionality nearing completion, the team has already begun planning the next stage of Exchange support, including calendar integration work that will build upon the foundation established over the past year.
This month we’d like to highlight Maxe, who has been on an impressive run tackling some of Thunderbird’s oldest and most stubborn MIME issues.
Open source projects often benefit from contributors who quietly and consistently improve areas of the codebase that most people would rather avoid. Over the past several months, Maxe has become one of those contributors for Thunderbird.
What began as a handful of fixes has grown into a sustained effort to tackle some of the oldest MIME-related bugs in our tracker. Many of these issues date back decades, touching parts of the mail stack that have accumulated years of edge cases, historical assumptions, and compatibility quirks.
MIME handling sits at the heart of how Thunderbird interprets messages, attachments, encodings, and content types. While users rarely think about it when everything works correctly, it is often involved when messages display incorrectly, attachments behave unexpectedly, or unusual emails expose long-standing inconsistencies. Fixing these issues requires a deep understanding of both email standards and Thunderbird’s historical behavior.
What has impressed us most is not any single patch, but the consistency. Over the past few months Maxe has continued to identify issues, develop fixes, respond to review feedback, and refine solutions until they work reliably across platforms and message types. Along the way, several fixes have uncovered additional problems and improved behaviour in places that weren’t originally expected.
This kind of work is rarely flashy. It involves patiently navigating decades-old code, reproducing obscure bugs, and developing enough confidence to modify systems that affect virtually every Thunderbird user. Yet these are exactly the sorts of contributions that make open source software better over the long term.
On behalf of the team, thank you Maxe for the energy, persistence, and technical skill you’ve brought to Thunderbird this year. Your work is making a real difference.
Add-ons, Extensions and Ecosystem
The add-ons ecosystem remains an important part of Thunderbird, and over the last few months we’ve continued working toward a safer and more maintainable extension platform.
One significant decision was the postponement of experiment deprecation on the Monthly Release channel for an additional year. Feedback from extension developers made it clear that many maintainers needed more time to migrate away from legacy experiment APIs, and we want to ensure that transition is successful rather than disruptive.
This extra time allows us to focus on expanding official WebExtension APIs, improve migration paths, and work directly with extension developers to understand their priorities. To support this effort, we’re preparing a broader outreach initiative later this year that will gather feedback from experiment maintainers and help guide future API development.
A great deal of this work has been driven by John, who has been balancing ecosystem improvements alongside onboarding new team members and supporting several other strategic projects. Ensuring that extension developers have a sustainable path forward remains a key investment area for Thunderbird.
Authentication and OAuth
Over the past several months we’ve continued modernizing Thunderbird’s authentication experience, with a particular focus on OAuth and account setup.
One of the most visible improvements has been the continued rollout of browser-based OAuth flows. Instead of embedding authentication within Thunderbird itself, users can now complete sign-in using their system browser, providing a more familiar experience while benefiting from the security features and account state already present in their preferred browser.
As we expanded support for these flows, we also uncovered an interesting interoperability challenge. RFC 8252, the standard commonly used by native applications, recommends the use of loopback redirects with dynamically assigned local ports. While most providers support this approach correctly, several major providers have historically handled these redirects differently. As a result, we’ve been working directly with providers including Yahoo!/AOL, Comcast/Xfinity, and Yandex/Mail.ru to improve compatibility and ensure Thunderbird users continue to enjoy a smooth sign-in experience as authentication requirements evolve.
We’ve also been simplifying account setup for users of Thunderbird’s growing ecosystem of services. Recent work allows users to launch authentication for a Thundermail account directly from Thunderbird without first manually entering account details. This significantly streamlines onboarding and lays the groundwork for similar experiences with other major providers in the future.
Another important addition has been the introduction of a Thunderbird-specific protocol handler. This enables web-based account dashboards, management interfaces, and enterprise deployment tools to communicate directly with Thunderbird and complete account configuration automatically. For Thundermail users, this creates a much smoother path from account creation to a fully configured desktop client. Looking ahead, the same technology opens the door to deeper integration opportunities for enterprise deployments and other hosted services.
While much of this work happens behind the scenes, it represents an important investment in making account setup faster, more reliable, and more secure for both individual users and organizations deploying Thunderbird at scale.
Panorama – Global Message Database
Behind the scenes, work continues on one of Thunderbird’s most ambitious long-term architectural projects: the Global Message Database.
Recent months have focused on strengthening the foundations needed to connect Panorama’s user experience with the underlying storage architecture. Geoff has resumed significant front-end work following ESR-related priorities, while Brendan has joined the project to help accelerate development and planning efforts. At the same time, Ben has been refactoring portions of the IMAP codebase to establish cleaner interfaces that will simplify integration with the new database architecture.
While much of this work remains infrastructural and therefore less visible to users today, it represents important progress toward a more modern foundation capable of supporting future performance, search, and organizational improvements throughout Thunderbird.
Maintenance, Upstream adaptations, Recent Features and Fixes
While major features tend to attract the most attention, a significant portion of Thunderbird’s engineering effort continues to be devoted to maintenance and adaptation work required to keep pace with our upstream platform.
This period is traditionally one of the busiest times of the ESR cycle. As Firefox prepares its next ESR release, large volumes of platform changes land in a relatively short period of time. While these improvements benefit Thunderbird in the long term, they can also introduce unexpected regressions, styling inconsistencies, test failures, and compatibility issues that require immediate attention.
One particularly notable example has been Mozilla’s ongoing Nova initiative, which introduces substantial visual and styling changes throughout Firefox. Without intervention, many of these changes would create inconsistencies across Thunderbird’s user experience. Richard (Paenglab) has done exceptional work identifying, triaging, and adapting these upstream changes to ensure Thunderbird continues to present a coherent and polished interface. Much of this work goes unnoticed when done well, which is perhaps the highest compliment for maintenance engineering.
Alongside these adaptation efforts, the team and contributor community have continued landing a steady stream of reliability, stability, and usability improvements across the application. Recent highlights include:
Improvements to threaded message handling and sorting behaviour.
Fixes for long-standing IMAP synchronization and data integrity issues.
Improvements to POP3 reliability, including protections against queue deadlocks.
Multi-monitor and mixed-DPI fixes for mail notifications.
Continued migration work to Fluent as part of our localization modernization efforts.
If you would like to see new features as they land, and help us find some early bugs, you can try running daily and check the pushlog to see what has recently landed. This assistance is immensely helpful for catching problems early.
In this post we walk through what folks have found on their journey to learn the Rust programming language with ups and downs covered.
As a disclaimer, LLMs (Large Language Models) come up in this post because our interviewees brought them up. We're scoping discussion to their use as a learning tool, covering research and example generation, not broader questions about AI (Artificial Intelligence) in software development.
Many paths to needing Rust
The interviews surfaced several different paths into Rust: curiosity, embedded work, job-market pressure, organizational adoption, and reassignment after a team or company chose Rust. That last path matters because many learners are not evaluating Rust from a blank slate; they are trying to become productive after Rust has already arrived in their work.
"Funny enough, I've advocated for more niche languages than Rust in the past. Rust has pretty much stopped being as much of a niche language as it was, but it's not Java." -- Fractional CTO
Rust learning resources
Likely as expected, the folks that we talked to reach for a range of resources to learn Rust. Some reach for official documentation, such as The Rust Programming Language Book and find that sufficient to build on what the compiler was already showing them.
"I started with the official Rust documentation because there are a lot of great examples of how features like the borrow checker work." -- Software engineer at an Automotive supplier
"The first time I went through the chapter in [The Rust Programming Language] on borrow checking, I was like, what is this? I read it again, then I watched a YouTube video of someone explaining the chapter." -- Rust freelance consultant
"Rust book, Rustlings, Zero to Production in Rust, Jon Gjengset tutorials. A bunch of books. It's not a one-pass reading. Can't say how many times I've gone through it." -- Software engineer working on video streaming and storage
These resources have brought up an entire generation of Rust programmers. But, to some, there is a perception that these resources have trouble keeping pace with the language.
"We'd like to use [The Rust Programming Language/'the book'], but we've found that it's out of date, unfortunately. We've looked at the GitHub repo and found it's got a lot of unresolved issues and unmerged PRs" -- Principal Software Engineering work on Rust adoption in a regulated industry
Whether or not this is factually true, Rust's growth has nonetheless put more scrutiny on these materials. Companies evaluating adoption and engineers getting reassigned to Rust teams are looking at them with fresh eyes and finding the gaps that affect their own evaluation.
Beginner stumblings and unlearning habits
It's pretty typical for Rust to be the 2nd, 3rd or Nth programming language that someone picks up. They'd end up writing their most familiar language in Rust, whether C++ patterns, Java patterns, or whatever they knew, for months or even years. Eventually they got comfortable enough to start writing idiomatic Rust.
"There's a bit of a drop in productivity compared to C if you're already familiar with it just because you're learning new rules, new syntax." -- Principal Firmware Engineer (mobile robotics)
"In the beginning it was more poking around the code and adding and removing some ampersands and asterisks to try to make sense of mut and not mut and whatever." -- Senior engineer with 20 years of Java experience in cloud and IoT
We also spoke with someone who found that not having much of a programming background seemed to benefit people picking up Rust. Not having worn-in grooves from other languages may play a role here, and it's worth investigating further.
"I had someone who had never programmed much before start working on the internals of [our Rust project]. She was just fine with getting into Rust. It's more of the senior people that struggle as they need to unlearn practices which may work in other languages, but it's not the 'Rust' way." -- Researcher, Automotive OEM R&D Lab
Learning to work with the borrow checker
We heard a lot about learning to work with the borrow checker instead of against it. People get there through different paths, but a few patterns came up repeatedly.
The compiler as teacher
Rust's diagnostics did the teaching on their own, especially around lifetimes.
"If you mess up the lifetimes in a piece of code that you've written by hand, I usually find that Rust's diagnostics are very helpful" -- Researcher working on static analysis of Rust programs
"Whatever's missing, the compiler usually fills in: it tells me 'you need to declare the lifetime of this reference', so I know and can figure it out. That all generally works pretty well." -- Senior Software Engineer
Learning by doing
Others felt like they only really internalized the borrow checker after writing a lot of Rust. It took projects, coding challenges, prototyping and so on until at some point it clicked.
"I actually did not understand the borrow checker until I spent a lot of time writing Rust" -- Founder of a startup built on Rust
"Besides the prototyping work, I also did coding-challenge-type stuff to get familiar with Rust for Advent of Code. [..] It eventually clicked to the point where I wasn't fighting with Rust, it was working for me. I had that experience other people describe: when I managed to get my program to fit with Rust, it worked. I didn't spend time debugging." -- Principal Software Engineer, large SaaS provider
Letting go of "clone guilt"
Some learners arrive with the assumption that good Rust means zero clones, zero copies, lifetimes threaded through everything. They set the bar at optimal before they've learned how to write idiomatic Rust, and it makes the borrow checker feel harder than it needs to be at the outset.
"On one of my first projects, I was like, 'I don't ever want to copy or clone anything,' so I carefully wove through all the lifetimes and got myself into a bit of a bind. Then I saw someone else just cloning the struct I was working with, and it was super cheap. Sometimes you can just clone and it's going to be okay." -- Researcher at a university
The experienced Rust developers we spoke with consistently said the same thing: clone freely while you're learning, then optimize when you understand the problem. Rust's reputation for performance and correctness feeds this. Newcomers assume anything less than optimal is wrong before they've written a first working program, and clone guilt is how that shows up.
We think it could be an interesting area of future study to check into the patterns Rust programmers employ at different levels of experience and under which circumstances. One member of the Rust Vision doc team that's very experienced with Rust noted that there's kind of an "expected shape" they understand as passing the compiler. This knowledge influences how they approach writing code which wouldn't take that shape and they naturally find themselves understanding when to use so-called workarounds, such as passing around indices into arrays or Vecs.
Multi-paradigm, but not the OOP some are used to
The Rust programming language is multi-paradigm, and how that lands depends on what you're coming from. We heard some that came from a functional background were delighted with digging into learning how much Rust inherits from that lineage. Some others noted that they and others on their teams struggled to unlearn the object-oriented style they'd come to use heavily in other languages like C++ and Java.
"Developers coming from C++ tend to think object-oriented. I think that's a difference between C++ and Rust." -- Architect at Automotive OEM
"I had exactly that thing, where I would apply all my years of Java and JS thinking, where I could just create some object, not care about it, return it, have it sloshing around between various functions. Found myself reaching for these patterns and then being told 'no, you cannot do that'." -- Principal Engineer at a SaaS company
Developers coming from functional programming had less to unlearn: strong typing, pattern matching, and an expression-oriented style were already familiar.
"My background has been more functional programming, strong typing. That originated for me as a Lisper: once a Lisper, always a Lisper." -- Principal Software Engineer working on Rust tooling for safety-regulated industries
"The languages I primarily used before Rust were things like OCaml. Way back, I came from C and C++, the classic languages, and then I spent quite a long time doing primarily pure functional stuff. These days I've ended up back in what I like to think of as a pragmatic center ground [with Rust]." -- Fractional CTO
Teaching Rust in academia
We spoke with a university professor that's been teaching Rust generally. In the academic environment, they were able to use proxies for some things such as "traits are like interfaces in Java" because the students had already gone through a set of courses in their first and second years that taught them Java. They introduced concepts slowly throughout the course, choosing to deal with some more complex topics like generics later. The outcome generally was that students had no problem picking up Rust in this setting.
"I couldn't see any big difference on the embedded side. We also teach an embedded class, and we did an experiment. Half of the students' feedback was worse on the Rust class, mostly because they needed to build the project themselves. The C students just got one from [an LLM], absolutely no problem." -- University Professor, on teaching Rust
The C cohort leaned on LLMs for the project in ways the Rust cohort couldn't. We don't yet have a clear answer for why.
What did come through clearly was the Rust cohort's experience with the community. Some students needed to figure out which drivers to use for the embedded project and how to use them. Their professor encouraged them to open issues and ask questions directly on GitHub, and the maintainers responded. Students who had never contributed to open source before were getting answers from the people who wrote the code.
Learning using LLMs
Some experienced folks shared that they saw LLMs as a tool that can help someone come up to speed quickly, either as a research tool or for generating example Rust code to understand concepts.
"I'm optimistic that there's a way to work [LLMs] in that will cut down that learning curve. One of the big things these tools bring is reducing the learning curve in general; these are very good tools to help you navigate a space that you don't know yet." -- Maintainer of large open source Rust crate
"I try [LLMs] out once a month, usually for generating an example or something like this. Just like with Stack Overflow: when you read an example, you should read it carefully and try to understand it. Not copy and paste it, but type it in your own words in code and then check it, because that's where the teeny tiny little mistakes are." -- Founder of startup built on Rust
For some learners, an LLM is just another way to find answers, no different than a search engine.
"So for the most part, picking up Rust - how do I learn? I'll [use web search for] things, I'll ask [an LLM], I'll just poke around and read the code." -- Senior Software Engineer working in a regulated space
One founder went further and claimed that LLMs change who can become a Rust developer. One consulting company founder described hiring high school graduates with no systems programming background and training them as Rust developers, with LLMs filling in the learning gaps that would previously have required years of experience.
"At the beginning, I was worried, but now that we have [LLMs] supporting development, the difficulty of the language doesn't matter. I'm seeing a huge opportunity behind strong runtime languages like Rust. [..] In [Developing Country] we hire 20-25 high school graduates, train them to be Rust programmers, then they enhance our workforce worldwide." -- Founder of a consulting company
We heard this from one organization. This is a claim that the combination of Rust's compiler and LLM tooling can dramatically shorten the path from beginner to working developer. Whether it generalizes depends on questions we can't answer from a single interview: how long these developers stay, what kind of code they can maintain independently, and whether this training/learning model works outside this company's particular structure. If it holds up, the pool of people who can become Rust developers is much larger than the usual hiring profile suggests.
Organizational considerations for Rust learners
We spoke with a number of folks on teams that are using Rust in larger organizations. Teams wanted to know that everyone would end up at roughly the same level of competence, which led a good number to invest in training courses to get there. Some leaders found that staff was able to ramp well enough by reading The Rust Programming Language, going through Rustlings, and then picking up lower risk and priority tickets to work on. Having a sense of community was also important within companies; it helps people know they are not alone when they are asked to work on Rust after, say, a reorganization happens.
"[..] the idea with the class as opposed to 'just read the Rust book on your own' was that this gives everyone kind of the same baseline going in." -- Principal Firmware Engineer (mobile robotics)
"So typically we're going to have people work through Rustlings, work through The Rust Programming Language. We have them then start to pick up lower risk tickets to work on." -- Principal Engineer at a large SaaS provider
"We've got an internal Slack channel for Rust learning where people can drop questions and others will come in and answer them. That helps build up understanding and community." -- Software Engineer at a large corporation
Some organizations found that while the person they'd hire would need to learn Rust, it was still preferable to the alternative of hiring someone for a critical piece of software written in another language.
"They needed to grow and maintain this C++ codebase. They had a C++ wizard, and they tried for about two years to find someone with the same level of expertise. They ended up hiring people that didn't know Rust and ramping them up, creating FFI bindings from the C++ side so they could work in Rust. And you can feel it: the borrow checker is teaching these people the right way to handle their systems." -- Principal Engineer at an Automotive OEM
The community and helping each other aspect seems to grow bonds as organizations mature.
"Our team is [all about] mentorship. I've mentored people coming up to speed on Rust, and people help each other hugely." -- Principal Software Engineer at a large SaaS company
Silent attrition
We identified some cases where people have approached Rust and bounced off of it, for one reason or another. In the below case, someone with a background in a language with fewer guardrails found themselves frustrated enough with Rust to walk away.
"All of that means that that embedded ecosystem is very frustrating to somebody who comes from C and is like, why can't I just get a pointer to this peripheral and then write into the registers. What are you doing to me? [..] My friend never got over that. He looked at it and said, I'm not going to deal with this and walked away." -– A second University Professor
There may be language features that for a particular domain are not seen as comfortable or usable yet, such as async Rust usage in a safety domain. We'd like to map which language features feel off-limits in which domains; async in safety-critical work probably isn't the only case.
"We're not fully sure how async [Rust] will work out in the long run in our domain. [..] People don't feel comfortable yet since C++14 doesn't provide such concepts. [..] It's the chicken-and-egg problem again: we probably need to gain some experience to see whether we can actually benefit from these new concepts in the automotive and safety domains." -- Team Lead at Automotive Supplier (ASIL D target)
We heard in at least one case, that while the language was challenging and there was a near bounce, the tooling helped keep them coming back and trying.
"Well, I think my early impressions of Rust - one is I find C++ so intimidating, and I think a big part of why I was able to succeed at [..] learning Rust is the tooling. I mean, all this makes sense [..] but it's like, for me, getting started with Rust, the language was challenging, but the tooling was incredibly easy." -- Founder of another startup built on Rust
While it might be considered more of a community concern, if there are interactions online and in spaces that point to learners having
so-called "skill issues" this feeds into the narrative that Rust must be hard to learn. We may be unintentionally turning away Rust Project contributors and maintainers due to the vibes being put out when new learners show up in certain spaces.
"People are very helpful, but generally the attitude is: if your program is very complicated, it's mostly a skill issue. There's not that much empathy when people get stuck learning, and a lot of people are just pushed away by it. There's probably a huge number of people who silently stop wanting to write Rust, because at some point it gets complicated and the feedback they get is 'you just need to be a better programmer, obviously'." -- Software Engineer at a SaaS Provider
Feedback on near-bounces from survey
We found a few interesting perspectives collected in the Rust Vision doc survey which we administered with examples of bouncing and coming back:
"I started before 1.0, got stuck very soon when trying to translate patterns from C++ to Rust (due to borrow checking). I tried again after 1.0 and it stuck. [..]" -- Survey Respondent A
Survey Respondent A went on to share in a more detailed response about a perceived weakness in Rust learning materials related to lifetimes and the borrow checker are explained. There was an observation that it's fairly easy to run into more complex situations with lifetimes and the borrow checker. They felt that the current state of this sort of material and tutorials is fairly superficial and can leave learners stuck when they run into those more complex situations.
One respondent that bounced once and came back shared challenges around usage of async. In concert with Rust's memory-safety and the borrow checker, they found some of the nitty-gritty details of async were difficult to learn. While we're aware of the Rust Project's continuous efforts to improve Rust's async story, this is another data point of a user that faced challenges.
Another survey respondent shared how they had multiple times bounced in trying to learn Rust. They returned after a year or so and found Rustlings to be highly motivating. We note that having multiple pathways for folks to learn Rust opens up more possibilities for those that nearly bounced, just like this person.
Need more focused work on silent attritrion
The thing that stood out most to us was the lack of real, first-hand knowledge of having bounced when learning Rust. While this is an obvious effect of soliciting answers to our survey and opportunities to interview through Rust channels and our networks, this cohort is good future candidate where interviews could start.
Conclusions
Across these conversations, the experience of learning Rust depended heavily on context. Why someone was learning and what support they had mattered as much as the borrow checker. The same kinds of examples kept coming up: a training course that got a team to a shared baseline, a maintainer answering a student's first GitHub issue, and a colleague whose code showed that cloning was okay.
That context is largely something the community has a hand in. With that in mind, here is what we take away from what we heard, and what we still don't know.
What seems worth trying
Learning materials aimed at unlearning. Syntax barely came up when people described their struggles. People struggled with unlearning habits from previous languages, whether OOP structuring from C++ and Java or the instinct to grab a raw pointer to a peripheral. Most of our learning materials teach Rust from first principles, and that works. What we didn't come across is much written for, say, the engineer with ten years of Java who lands on a Rust team after a reorg: material that names the patterns they'll reach for that won't transfer, and shows what to do instead. The professor we spoke with did a version of this in the classroom, leaning on "traits are like interfaces in Java" and saving generics for later in the course, and the students did fine. Something similar could work outside the classroom too.
Put the "clone freely while you're learning" advice somewhere official. Every experienced developer we spoke with gave the same advice, but learners seem to mostly pick it up by accident, like the researcher who happened to see someone else cloning the struct they had been carefully threading lifetimes through. Saying it early in official materials would take some of the steepness out of the curve. The broader version belongs there too: idiomatic Rust doesn't have to mean optimal Rust, especially on a first project.
Diagnostics are already a primary learning resource: several people told us the compiler taught them lifetimes before any documentation did. Diagnostics reach learners right at the moment they're stuck. When writing new ones, it seems worth keeping the confused newcomer in mind alongside the expert, because for a lot of people this is where the learning happens.
Is "the book" actually out of date? Whether or not The Rust Programming Language or other materials are actually behind, a team evaluating Rust looked at its repository, saw unresolved issues and unmerged PRs, and moved on. As more companies evaluate adoption, more people will look at these materials with the same fresh eyes. Visible issue triage and some communication about what's current and what's planned would address the perception, separately from whatever content work may or may not be needed.
How stuck learners get treated is shaping who stays. We heard about students getting answers on GitHub from the maintainers who wrote the code, and we heard about learners being told their struggles were a skill issue. The first group came away with a lasting good impression of Rust. Some of the second group walked away entirely, and because they leave quietly, it's easy to underestimate how many of them there are. The welcoming side of the community came up unprompted as a reason people stayed, so we know it makes a difference when we get this right.
Every organization we spoke with described essentially the same ramp-up for bringing a team to Rust. Teams that brought groups of developers to Rust described roughly the same approach: get everyone to a shared baseline with a training course or with The Rust Programming Language and Rustlings, start people on lower-risk tickets, and give them somewhere internal to ask questions. Several organizations also found that hiring developers without Rust experience and ramping them up worked out better than continuing to search for rare expertise in another language. None of this is complicated, and teams weighing adoption don't need to invent a training program from scratch.
What we still don't know
The biggest gap is the people we didn't reach. Nearly everyone we spoke with stuck with Rust long enough to be reachable through Rust channels, so the stories of bouncing off came to us second-hand: a friend who walked away from embedded Rust, colleagues who quietly stopped after the responses they got. As we wrote in our first post, finding people who decided against Rust takes targeted outreach. If the proposed User Research team comes together, talking with learners who bounced would make a good early project, and learning is probably the area where that research would teach us the most.
We also don't know what to make of LLMs as a learning tool yet. They came up as a search engine, as an example generator, and in one organization's case as something that makes training high school graduates into working Rust developers possible. We saw a classroom where the C cohort leaned on LLMs in ways the Rust cohort couldn't, and we don't have an explanation for it. All of this comes from a handful of conversations, so we treat it as a set of leads to follow up on. Given how quickly the tools are changing, it seems better to study this deliberately than to wait and see what folklore develops.
The folks we spoke with showed that people do get there: with enough passes through the materials and enough code written, it eventually clicks. The opportunities above are mostly about making it work for the people who didn't pick Rust on purpose, and for the ones who would have stuck around if their early experience had gone a little differently.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at
@thisweekinrust.bsky.social on Bluesky or
@ThisWeekinRust on mastodon.social, or
send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a
call-for-testing label to your RFC along with a comment providing testing instructions and/or
guidance on which aspect(s) of the feature need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
This week had a lot of big swings, with two significant perf regressions that are accepted
because they unlock future features and perf improvements.
We also saw large improvements in the next trait solver due to the performance optimization work happening there.
Triage done by @JonathanBrouwer with help from @Kobzol.
Revision range: b5d46ecb..8b6558a0
Summary:
(instructions:u)
mean
range
count
Regressions ❌ (primary)
0.9%
[0.2%, 2.7%]
184
Regressions ❌ (secondary)
1.0%
[0.1%, 4.2%]
160
Improvements ✅ (primary)
-0.3%
[-0.3%, -0.2%]
2
Improvements ✅ (secondary)
-11.8%
[-69.9%, -0.2%]
25
All ❌✅ (primary)
0.8%
[-0.3%, 2.7%]
186
5 Regressions, 3 Improvements, 2 Mixed; 4 of them in rollups
30 artifact comparisons made in total
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
Earlier this month, we officially stood up Mozilla.org: a new 501(c)(3) nonprofit created to steward the long term success of the Mozilla Project.
Over the last year or so, I’ve said a lot about how AI is reshaping the web — and how we need to simultaneously stand up for the open internet Mozilla helped build and shape what the internet is becoming in the AI era. This is a huge and urgent challenge.
Mozilla has evolved and grown a great deal in order to step up to this challenge.
We are still a high impact philanthropic foundation and a browser company focused on user choice. But we are also: an email company built around privacy; an open source AI startup focused on developers; a place for people to create and share data on their own terms; and an investor in responsible tech startups.
These are all pieces of Mozilla today, and are all important levers as we try to shape where the internet is headed for the better.
We have created Mozilla.org to pull all of the different pieces of Mozilla together. It will act like a strategic endowment — allocating funding, managing our brands and shaping long term strategy — to ensure every part of Mozilla is well set up to advance the vision outlined in the Mozilla Manifesto. And, if we’re successful, it will help all of the pieces of Mozilla add up to more than the sum of their parts.
This is an important milestone for Mozilla. The challenge of fusing the values of the Mozilla Manifesto into this next era of the internet is huge. This updated structure will make it easier to nimbly direct our resources and orchestrate our actions to step up to this challenge.
At the same time, what we love about Mozilla stays the same. All of Mozilla’s organizations remain under the umbrella of the 501(c)(3) Mozilla Foundation, with the new non-profit operating the Mozilla portfolio of organizations on its behalf. Our mission — and our commitment to nonprofit ownership at the top — remain steadfast.
Over the past several weeks, we have been welcoming early users from our waitlist into Thundermail, a few waves at a time. Many of you are now setting up your accounts, trying things out, and sharing your thoughts with us.
Naming updates
You may have noticed that we are now saying Thundermail more often, and Thunderbird Pro less.
Thunderbird Pro started as the name for our subscription services, including Thundermail, Appointment, and Send. But early feedback made two things clear: people cared most about Thundermail, and “Pro” created confusion about whether Thunderbird itself was becoming a paid or limited product.
So, to clarify things, Thunderbird Pro is now simply Thundermail: the email service from Thunderbird, with features like Appointment and Send included.
The Thunderbird Desktop and Mobile apps remain exactly what they are today: powerful, compatible with any email service, and free.
What we learned so far
Every day, members of our team are reading through your survey responses, your messages in the Thundermail Early Bird community chat, your support requests, and every new idea and vote on the board. We discuss what we are hearing, and we sort it into what we can address right away and what we want to plan for. Then we keep working in the open, where you can see what we are up to and tell us when something is not quite right.
Here are some of the things we’ve learned so far:
Custom domains matter a lot. Many called this out directly, along with support for unlimited custom domain aliases. Several responses said these features stood out compared to other email providers.
Multi-factor Authentication saw a lot of requests on the ideas board, and we listened. This is now in progress and will be available soon.
Users appreciate that Thundermail is open and works with any email app. It has always been our intention to stick to open standards so Thundermail stays easy and open to use with Thunderbird or any other app.
A bit of surprise that calendar and contacts are included. Apparently we should probably talk about that more.
Requests for more pricing tiers and plans were frequently mentioned, which we will be adding once Thundermail is out of beta and open to the general public.
However, there was one request which came through louder than any other…
Webmail
Webmail was, by a wide margin, the most requested idea from our community, and whereas we had it in the plans for down the road, many people expected this to be a feature available from day one.
We moved webmail to the top of the list, shifted resources into the work behind it and we are excited to share that an early alpha version of it is coming next month. As with most early releases, it will have some rough edges, but will also allow for a much more interactive user experience for our beta testers. Everyone will have a vote in how it’s shaped for the future.
More reliable email, as we keep fine tuning things behind the scenes, training global mail servers and spam filters.
Onboarding improvements for a smoother first time sign-up flow.
Send and Appointment
Our scheduling and secure file sharing tools are still here, and they are still part of your subscription. Our main focus right now is Thundermail and webmail, but we are continuing to care for both with steady improvements along the way.
Send: Improved Thundermail integration, providing end-to-end encrypted file attachments without the need for a separate add-on. Users on our Daily version can already test this feature today.
Appointment: Streamlined the sign up flow, added an easy one click connection with the Thundermail calendar, and refreshed the calendar view design.
We’re looking for more ideas
If you are an Early Bird, we would love for you to visitour ideas board to share your suggestions and vote on the ones you would most like to see. We really do read every single one.
And if you have not been invited yet, you can join the waitlist. More waves are going out soon, and we are looking forward to welcoming you onboard.
If you’ve been running into endless CAPTCHAS or website login requests lately, you’re not imagining things.
Websites, facing a rising tide of abusive traffic from bots, are adopting increasingly aggressive countermeasures, damaging user’s experience of the web, their privacy and open access to the web.
In this post, we’ll talk about a new initiative we’re launching with Cloudflare, other web browsers, and web stakeholders to address this challenge while keeping the web anonymous by default.
Privacy and access in tension
The fight for privacy on the web has made real progress. Browsers that put privacy first are eliminating third-party cookies, restricting fingerprinting, and hiding IP addresses, pushing back against the trackers.
But every step forward has come with a cost.
Users are seeing more CAPTCHAs, more demands to log in, and more outright block pages than ever before. Building privacy into the browser means dismantling the passive signals, like IP addresses and browser fingerprints that are used to profile users, but are also relied on by anti-abuse systems.
At the same time, sites are facing large increases in bot traffic. The response from websites is understandable; volumetric abuse like credential stuffing and spam can do real damage. But the result is a lose-lose: users face mounting friction and reduced privacy, while sites drive away the legitimate visitors they wanted to serve.
If nothing changes, users will increasingly be forced to choose between their privacy and their access to the web.
Proposals have been made to tackle this dilemma, by asking users to prove to sites that their devices and software are ‘trusted’. These proposals, such as Web Environment Integrity (WEI), transfer control of devices away from users and to a small handful of operating system and hardware vendors. This deprives users of choice and control and gives those gatekeepers control over which devices and software can access the web, the opposite of the open web, which Mozilla is working to protect.
Finding a better way forward
We think there’s a better way forward. It starts from a simple observation: bots cause harm because they operate at scale. To stop that kind of abuse, a site doesn’t need to know who you are, or that your device is restricted to running approved software. It only needs to know whether you’re staying within a reasonable rate limit.
To make a rate limit work, it must be hard for attackers to create new identities and reset their allowance. That’s one reason why sites demand an email address, a federated login or a device fingerprint: obtaining a new one is just costly enough to make the rate limit stick. The challenge is whether we can make rate limits work, without giving sites access to hard-to-change identifiers that also enable tracking.
Some sites naturally have a relationship with their users, like a subscription or a long-standing account. What if one of those existing relationships could quietly vouch for you elsewhere, so a site you’ve never visited could trust that you’re a real person within its limits, without learning who you are or even where the vouch came from?
For example, consider a VPN service. Many websites block VPN traffic entirely due to the high rates of abusive traffic blended with legitimate traffic. What if a VPN service could vouch for each of its subscribers? This would let sites manage a per-subscriber rate limit, meaning users get fewer roadblocks and sites get more of the legitimate traffic they want. Of course, this requires that the vouching system doesn’t enable sites to track VPN users, which would otherwise defeat the very purpose of using the VPN.
Enabling this kind of privacy-preserving vouching is already possible in a limited sense. Apple’s Private Access Tokens, built on a cryptographic protocol called Privacy Pass, let Apple devices receive single use tokens they can later present to websites without those visits being linked together.
However, Private Access Tokens have some critical shortcomings. First, like WEI, they rely on device attestation, the very hardware gatekeeping we are determined to avoid. Second, there’s no easy way to open up the system to let more parties vouch for users without compromising on user privacy, which means concentrating control in the hands of a few. To keep the web open, we need a system where any site can vouch for users, and where other sites can decide who they trust to vouch for users responsibly.
This is a much harder problem, but we think the cryptographic foundations exist to deliver it. Anonymous credentials let one party issue you a credential that you can later present to a site a limited number of times, whilst preventing sites and issuers from tracking its use. It’s even possible to hide which party issued it, proving only that it came from a set of trusted issuers.
A fix is both essential and possible
Building this into a system for the open web, where any site could vouch and any site could set its own limits is challenging, but we believe it’s both possible and essential in order to defuse the tension between privacy and access, while avoiding centralising control in a small number of gatekeepers.
Working with other web stakeholders, including Cloudflare and other browsers, we’ve started designing such a system. For a deeper dive, read our post on Hacks, which goes into more detail about the problem space and the approach we’re working on.
Our goal is simple: fewer CAPTCHAs, fewer unnecessary blocks and fewer demands to identify yourself, without compromising on privacy. This is the kind of web that Mozilla built Firefox to offer: easy to use, private and open to all.
This is the technical companion to our update on Distilled, “Keeping the web open and private in the bot era.” Here we take a deeper look at the problem space, the design we’re proposing, and the problems still left to solve.
Bots (and privacy-preserving browsers) not welcome
Browse a news site in a private window. Shop at a major retailer with a VPN. Visit a video streaming platform with anti-fingerprinting defenses tuned up. You’ll see the same responses: registration walls, block pages, and endless CAPTCHAs. The message is clear: if we think you might be a bot, you’re not welcome.
Websites have valid reasons for wanting to block bots. Bots enable volumetric abuse, abuse that wouldn’t otherwise be feasible if they had to be carried out by humans. For example: SEO comment spam, credential stuffing and DDoSing. Consequently many sites employ dedicated anti-abuse tooling which aims to keep the bots out whilst minimizing friction for human visitors.
Unfortunately, that tooling is increasingly failing at both tasks. Browser privacy protections are dismantling the passive signals that anti-abuse systems depended on to identify and distinguish visitors. Meanwhile advances in generative AI have rendered CAPTCHAs ineffective: bots now solve them faster and more reliably than humans.
Many sites are switching to more invasive mechanisms and now ask visitors to disclose identifying information, e.g. an email address, a federated login or disabling their VPN. This means greater friction for users, since providing these details on a first visit takes time. It also compromises their privacy, since these details enable the same kinds of cross-site tracking that browser privacy protections were intended to mitigate.
This leaves users with a dilemma. The more effectively they protect their privacy, the harder it is for websites to distinguish them from bots and the worse the treatment they receive. Website operators are also suffering. The additional friction they inflict upon well-behaved visitors harms their site, but many are willing to pay the costs if it mitigates volumetric abuse.
Browser-based AI agents make this tension more acute. Sites may want to allow agents which are acting on behalf of individual users while blocking agents engaged in volumetric abuse. However, with no effective mechanisms to distinguish the two, websites are opting to block both. That hurts users, who should be free to choose the user agent they use to access the web; it hurts new browsers and agents, which struggle to interoperate; and it hurts sites, which lose legitimate visitors.
The consequence is that the web gets worse for everyone. Users get more friction or less privacy or both. Website operators see more volumetric abuse and the friction they add drives away users who would otherwise want to consume their content or services. New useragents struggle to access the same content as conventional browsers.
The Costs of Convenient Solutions
Some large ecosystem players have put forward solutions that leverage their control of the dominant operating systems and their deep integration with consumer hardware. These rely on device attestation: identifiers and privileged code baked into devices at the hardware level, which let manufacturers prove what software is running on a user’s device. Exposing this functionality to the web means attesting to sites that the user is running approved software with trusted hardware and therefore isn’t a bot. There have been two substantive proposals.
Google’s Web Environment Integrity, abandoned in 2023, was the blunt version. It attested to the user agent itself, as well as the operating system and device in use. Users would have lost control in two ways: once to the attester, which would decide which operating systems and devices could be blessed, and again to the website, which would decide which software to accept. If sites had adopted allow-lists of approved user agents, building a new browser would have become virtually impossible, and sites could have withdrawn access from any user agent they chose.
Apple’s Private Access Tokens, deployed across their ecosystem in 2022, have more subtle issues. Built on the Privacy Pass protocol standardized at the IETF, they get a lot right: a user receives a renewed, limited batch of one-time tokens that can be presented to websites without linking their visits together. This provides privacy for users and has shown rate limits to be an effective tool for sites – both points we’ll return to later in this post.
However, Private Access Tokens rely on device attestation, requiring that the hardware manufacturer be in overall control of the user’s device. Presenting a PAT tells a website you are locked into Apple’s rules for what counts as acceptable software. Due to PAT’s technical design[1], there’s no way to open the system to other sources of scarcity without compromising the system’s privacy properties, meaning that if more widely deployed, access to the web would become tied to having bought expensive hardware from a small, hard to change set of vendors.
Both approaches are ultimately hostile to users and to the openness of the web. Both are premised on parts of a user’s device that sit within the manufacturer’s control and beyond the user’s own. Were they widely deployed, the web would become just another walled garden with centralized gatekeepers controlling acceptable hardware, operating systems and software. As convenient as these solutions are for the players who already dominate the ecosystem, we think there’s a better path.
A Better Path Forward
Bots’ harms arise from their ability to operate beyond human scale. For sites to prevent volumetric abuse they don’t actually need to know the user’s identity or receive cryptographic proof that they’re running approved software. If sites knew their visitors were restricted to a rate limit set by a site, that would be enough.
Rate limits only make sense if they’retied to something scarce; something an attacker can’t cheaply replicate to evade the limit. Without anchoring to a scarce resource, like the trusted hardware used in Private Access Tokens, attackers can generate as many fresh identities as they need to bypass the rate limit.
However, hardware is just one option for scarcity. Anything a user already has that an attacker can’t trivially spin up at scale will work: email addresses and phone numbers are naturally scarce. A paid subscription costs an attacker the same as a real user. Even maintaining an account on a free service requires some non-trivial work.
What if we could use these scarce signals across the web? We could build an open ecosystem with many parties offering scarcity signals, each site choosing which to accept. By opening up who can provide a signal, and letting sites choose which to accept, we can avoid transferring control to device manufacturers and the resulting harms.
As a concrete example of who might be well positioned to provide such a signal, we can consider VPN providers acting as a subscription service. Sites routinely block VPN users indiscriminately, whether through a deliberate policy choice or through an indirect consequence of rate limiting visitors per IP address. But a VPN subscription is a perfect source of scarcity. If the VPN provider could vouch for its users so that sites could rate limit each user individually – then users would be able to browse the web with less friction and without giving up their VPN usage.
The catch is that building a system that can enable this on the open web whilst maintaining user’s privacy is genuinely difficult. It requires that we take information from one site — that this user holds some scarce thing — and expose it to other sites so that they can use that as the basis for their rate limiting. Letting one site verify a signal from another is the sort of information flowthat privacy-preserving browsers have spent the last decade locking down to prevent cross-site tracking.
Our goal would be that no more than the minimum information gets through: a single bit communicating whether the user is below the rate limit set by the site. Leaking anything more – like the source of the scarcity that the rate limit is anchored to – would be unacceptable. Enabling a new cross-site information flow might feel like compromising privacy to gain better access, but reality is more nuanced. If a new system moves sites away from demanding that visitors be identifiable (whether through fingerprinting or login forms), it can be a win for both privacy and access.
The Foundations
The good news is that the cryptographic foundations for a privacy preserving approach already exist. The Privacy Pass protocol,originally developed in 2018 to reduce the friction of Cloudflare CAPTCHAs for Tor users, introduced the core primitive: a token that is unlinkable between issuance and redemption. You prove something to an issuer (e.g. by solving a CAPTCHA), receive some tokens, and later present a token to a website. The website can verify the token is legitimate, but can’t link it to the user it was issued to.
Figure 1: In Privacy Pass, a CAPTCHA provider can issue tokens to a client which can then be used to bypass challenges for future site visits. Even if the CAPTCHA provider and sites collude, they can’t use the tokens to identify the user or their browsing history.
Privacy Pass has gone on to be successfully deployed in systems where the issuer and verifier have a prior trust relationship: Apple uses it to authenticate users of Private Cloud ComputeandPrivate Relaywithout linking their activity to their identity, Chrome uses it for two-hop IP protection, and Kagi uses it to provide private search. These deployments work in part because a small number of parties have agreed in advance on who issues tokens and who accepts them.
Applying this approach to an open system where any site can act as an issuerbrings real challenges. Firstly, even though tokens are unlinkable, knowing a user has access to a specific issuer is a privacy leak on its own, because you can infer that the user meets the relevant issuance criteria. If one site can learn that you have a token from another site, that reveals that you have been to that site, which can be a major privacy problem. This compounds if sites can learn the set of issuers you have visited, since it becomes a fingerprint which can be used to identify you.
Generic techniques exist for proving a statement in zero knowledge: we can prove that a client has a token from a set of acceptable issuers without revealing which specific issuer it is. We’ll call this issuer blinding. The generic approach is often slow, but bespoke approaches tailored to the underlying cryptography can improve this considerably.
Another challenge is how sites using rate limits decide who to trust to issue tokens. If an issuer misbehaves then the site’s rate limits become ineffective, enabling volumetric abuse. However, if we need to prevent the site from learning which issuers a user has access to, the site is only going to know that one of its trusted issuers was used, not which one. This makes mistakes or misbehaviour by an issuer difficult to detect, and makes it hard for sites to evaluate new issuers. Solving this challenge is essential for openness. Without adequate information, sites are likely to lean towards conservative issuer selection. That could lead to less choice between Anchors, which in turn could lead to a new form of gatekeeper being created.
To solve this, sites at least need a way to calculate an aggregate score for each issuer they use. This should roughly correspond to how much of the traffic it considers abusive to have come from users using that particular issuer. Mozilla has long invested in systems like Prio which use multiparty computation (MPC) to protect user privacy whilst enabling aggregate measurements of system behaviour.
Privacy Pass also struggles to handle dynamic adjustments to rate limits. Once tokens have been issued, they’re difficult to invalidate without either revoking all active tokens or risking attacks which can compromise the privacy of users. It’s also beneficial if sites can adjust rate limits on a per client basis, for example by increasing rate limits where they become more confident the client is benign and withdrawing access when abuse is detected.
Anonymous Credit Tokensoffer a useful building block to solve this problem. Conventional Privacy Pass schemes rely on issuing a bucket of tokens but ACT works differently by enabling the use of a credential with state. For example, an ACT credential can hold an internal counter. When the credential is presented, the site can check the counter is over some threshold and mutate it, increasing or decreasing the counter whenever the site’s perception of the holder has improved or worsened. Critically, the exact value is never leaked to the site, preventing the site from tracking the holder and ensuring successive presentations of the same credential can’t be linked.
Putting it together
So how can we combine these techniques to build a system which can enable privacy-preserving rate limiting on the open web? In May 2026, we participated in a W3C CG Meeting in collaboration with Cloudflare, Chrome and other web stakeholders in which we started sketching out a design we’re calling PACT – Private Access Control Tokens.
Rate limits need a starting point, a source of scarcity to anchor on. We’ll call an entity that provides such a source an Anchor. To a user who meets the Anchor’s criteria, like having a subscription, an account in good standing, or a verified phone number, an Anchor issues a batch of Endorsement tokens, following the Privacy Pass model. In practice, Anchors could be any website which has access to this kind of signal. An Endorsement conveysscarcity to other sites.
That’s enough for a simple system where access is either granted or denied. But as we discussed earlier, we also want the ability to increase access where a visitor behaves benignly and decrease it where they don’t. The state needed to enforce a rate limit can’t live in the Endorsement, because Endorsements cross trust boundaries between unrelated sites. We need a second object that can hold that state, scoped to the party that maintains it.
We’ll call that the party that handles rate limiting for a site a Moderator and the stateful object a Credential. A Credential is specific to a Moderator and, unlike endorsements, we limit each site to nominating a single Moderator. In the common case the site itself plays the Moderator role, so there’s no new entity or trust boundary. A Moderator can also be a third-party service shared across many sites, allowing those sites to cooperatively share a rate limit.
In the terminology of the previous section, the Anchor is the issuer of Endorsements, and the Moderator both verifies Endorsements and issues Credentials. A Moderator manages rate-limit policy: it decides which Anchors it trusts, accepts their Endorsements, and issues a Credential in return.
Figure 2: (1) Clients acquire Endorsements from Anchors in the course of normal browsing to sites they have relationships with. (2) Clients can exchange Endorsements for a stateful Credential from a Moderator. (3) Credentials can be used to access sites which use that Moderator. Credentials can be updated over time.
Directly revealing which Anchor backed an Endorsement would leak a lot of information about the user. The issuer blinding techniques from the previous section solve this: when an Endorsement is redeemed, the Moderator only learns that it came from one of the Anchors it trusts, but not which one.
When a Moderator covers more than one site, we let Credentials be presented across all of them but partition cookies and storage as we would for any other third party site. The unlinkability of Credential presentations keeps this from creating a new cross-site identifier. The benefit is that good behaviour on one site improves access on every site the Moderator covers, and bad behaviour cuts it everywhere. Websites can already build the same capability with a shared account system, so this doesn’t create a new way to lock users out, but it does provide a new way to grant access without requiring users to give up their privacy.
Enabling Moderators that cover many sites carries a centralisation risk, similar to the concentration we see today in anti-abuse providers. The mitigation is that the choice of Moderator stays with each site, and the choice of trusted Anchors stays with each Moderator. Thiscan’t reverse the centralisation pressure the web already faces, but it ensures this system won’t lead to additional lock-in: a new Anchor or a new Moderator can be adopted without coordinating with a dominant vendor.
The system then has three flows. First, the user receives Endorsements from an Anchor in the course of normal interaction, based on the Anchor’s positive view of the user. This is a relatively rare operation for any given user and Anchor. After all, as our source of scarcity, Endorsements should not be too easy to accumulate.
Figure 3: In the course of normal browsing, clients browse to websites they have a relationship with. These sites can act as Anchors by issuing Endorsements to clients.
Second, when the user arrives at a site that works with a Moderator, the browser spends an Endorsement from an Anchor the Moderator trusts and receives a Credential in return. The presentation hides which Anchor was used, and neither the Anchor nor the Moderator can trace the Endorsement back to where it was issued. The Moderator decides what initial balance the Credential starts with. If the user has no Endorsements from suitable Anchors at all, existing mechanisms (CAPTCHAs, account creation, federated login) could be used to bootstrap a Credential the same way, so the system degrades to today’s experience rather than locking the user out.
Figure 4: When the client browses to a site, it can prompt the client for a Credential from the Moderator it uses. If the Client doesn’t have a suitable Credential, but does have a suitable Endorsement, it can exchange it for a Credential with the Moderator. In practice, the Moderator and the Site might be the same server.
Third, as the user browses, the browser presents the Credential and the Moderator updates the internal state of the Credential. The Moderator can reward behaviour that looks benign and penalize suspicious activity, but can’t track the use of the Credential or identify it if it’s used on other sites the Moderator covers. Revocation falls out of the same mechanism: a Moderator can refuse to return an updated Credential.
Figure 5:The Client can present the Credential on sites which use the matching Moderator. Sites can check if the Credential is in good standing. The sites can then adjust the access the Credential has in response to behaviour. E.g. increasing it when they gain confidence in the client or reducing it in response to malicious behaviour.
In practice, all of this would happen transparently to the user through a WebAPI that sites acting as Anchors or Moderators would call from JavaScript. In an ideal ecosystem, users would accumulate Endorsements through normal browsing, just by virtue of the sites they already visit, and the rest of the flow would happen in the background as they move around the web, leaving users with meaningfully less friction.
AI agents acting on behalf of a user slot into the same flow. An agent can carry its user’s Credentials, in which case the user remains accountable for how the agent behaves.Sites would not need to grant any more access than they would to the user themselves. Alternatively, the operator of an agent can run its own Anchor and vouch for its agents the way other Anchors vouch for human users. Sites retain control over which Anchors they accept, so they can choose how to treat agent traffic without needing a separate detection mechanism.
Several mechanisms combine to keep the information about a user that flows out close to a single bit. Cryptographic unlinkability ensures successive Credential presentations cannot be tied to each other or to the original issuance, so a user’s visits cannot be joined into a history. Each site is bound to a single Moderator, so the set of Moderators a user has Credentials with never becomes a cross-site fingerprint. The Anchor-to-Credential exchange happens in an isolated browsing context, so during ordinary browsing the only thing the site or its Moderator ever observes is a Credential presentation: the site only learns if the user has a valid Credential below the rate limit, or nothing. When the Moderator updates a Credential, it adjusts the credentials state without learning what it is.
The additional privacy given to users from Issuer blinding makes participating in the system more challenging for Moderators. Because the Moderator can’t see which Anchor backed a Credential at issuance, it can’t give a Credential from a strong Anchor more access than one from a weak Anchor: doing so would itself leak which Anchor was used. The initial access has to be uniform across the Moderator’s whole pool of Anchors, which in practice means setting it at the strength of the weakest. However, this is only relevant for that initial access, the Moderator can update credentials according to the holder’s behavior, enabling Credential’s to accrue access over time.
Building an open ecosystem also requires that sites can make effective decisions about the Anchors they choose to trust. Multiparty computation systems like Prio enable aggregate scoring without compromising privacy. When users present Credentials, they can provide an encrypted share which identifies the anchor they used and can be privately aggregated to compute the quality of an issuer.
Next Steps
We think the architecture we’ve sketched for PACT has the right shape, but many of the details still need to be worked out and the entire system needs rigorous privacy and security analysis.
We want to do that work in the open. The IETF is the natural venue for the cryptographic protocols underneath, and the W3C for the WebAPI surface that sits on top. We’ll be bringingdraft specifications to these bodies as soon as they’re ready, and we welcome collaborators from across the ecosystem: browser vendors, site operators, anti-abuse providers, and the cryptography community.
If successful, we think we can provide a system which will keep the web open and private, while still giving sites the rate-limiting signal they need.
Acknowledgements
The ideas described here are the result of collaboration and conversations with many people, including: Watson Ladd, Thibault Meunier, Michele Orrù, Trevor Perrin, Eric Rescorla, Samuel Schlesinger, Martin Thomson, Eric Trouton, Benjamin Vandersloot & Cathie Yun.
[1] PAT requires that the source of scarcity and an independent issuer be trusted not to collude. If they do, they can track users as they interact with the system. This is not suitable in the context of an open system where any party could play those two roles.
Two years ago, the Digital Markets Act was the first of its kind: an ex ante competition framework introducing contestability and supporting innovation. But, as much as its critics try to cast it as a European experiment, it was never alone. In 2019, expert reports across the US, EU, UK and elsewhere studied the competitive dynamics of digital platforms. Today, the conversation has moved on to how to restore competition and choice within digital markets.
That shift was on display at Mozilla’s event in Brussels on 2 June, “Rebalancing Digital Markets: Delivering Competition, Choice, and the Road Ahead.” Regulators and policymakers from the EU, UK, Japan, and Brazil came together to assess what two years of reform have delivered and what still needs to happen. The answer was clearer than expected: ex ante competition regulation works, but only where it has been properly enforced.
The proof of concept holds
The DMA’s browser choice screen obligations have produced real, measurable results. We have written about the data in detail. The headline numbers: Firefox has been selected via a DMA choice screen over six million times in two years, once every ten seconds. Daily active users in the EU have grown to double those in comparable countries. People who choose Firefox through a choice screen are five times more likely to stick with it than those who arrive organically. The core finding is simple: this is what competition looks like when it is allowed to work. When users are given a genuine, well-designed choice, they take it. That was not a given. Earlier choice screens resulting from ex post antitrust processes produced no measurable impact. What changed was rigour and enforcement: working with behavioural economists, testing interfaces carefully, focusing on outcomes rather than checkbox compliance.
The lesson extends well beyond browsers. Desktop remains largely untouched, leaving roughly 310 million desktops and laptops in the EU without an equivalent level of browser choice. Windows users are still frequently steered towards Microsoft’s own services through design choices that override user choice or make switching more difficult than it should be. Ensuring that users of all gatekeeper services can easily change default settings, free from manipulative practices or undue influence, remains a critical test for DMA implementation. Choice screens can help, but they are not a silver bullet. Ecosystem lock-in, interoperability barriers and entrenched defaults continue to limit competition and innovation. The window to address these issues before new forms of digital gatekeeping become entrenched remains open, but it will not stay open indefinitely.
Reform is going global and fast
The institutional approaches across jurisdictions may differ, but the direction of travel is increasingly similar. Policymakers are recognising the need to address concentrated power in digital markets, expand user choice, and create conditions for competition and innovation to flourish.
The UK has opted for a flexible, case-by-case model and has already designated Google and Apple in respect of their mobile platforms. Japan scoped its legislation tightly to mobile, moved quickly, and is now seeking to ensure effective compliance for Japanese smartphone users. Brazil is building a framework calibrated to its own market realities.
None of these jurisdictions is simply copying the EU’s DMA. All of them are drawing on their experience and developing ex ante frameworks that work for their people and their economies: what a good choice screen looks like in practice, what regulatory capacity is needed before a law enters into force, and what happens when the large tech companies seek to undermine rather than facilitate choice and competition.
What the momentum demands
The consistent lesson is unglamorous: the staff, expertise, and industry relationships needed to enforce these rules have to be built before the law arrives, not after.
A clearer consensus is also forming around what enforcement needs to deliver. Rules that look good on paper but do not change what users experience every day are not enough. Technical expertise matters, particularly as AI raises questions that economists and lawyers alone cannot answer. The European Commission’s ongoing proceedings in AI distribution are a test of exactly this: whether regulators can move fast enough to ensure competing AI services are able to reach users before vertical integration entrenches dominance. And regulators need to be clear-eyed about a pattern that has emerged across jurisdictions: gatekeepers framing incomplete compliance as a deliberate policy choice, rather than acknowledging it as a failure to meet their obligations.
These are sophisticated companies, and they will keep testing what regulators will accept. The measure of this generation of digital market frameworks is not whether they passed through legislatures, but whether they can deliver real impact for people.
For Mozilla, that means ensuring the lessons travel: to desktop, to AI, and to every jurisdiction building its own version of these rules. Competition, choice, and true innovation in digital markets should be the norm, not the exception.
Morgan added a new accessibility-specific, front-end review skill to mozilla central! 🎉 You can read about it, and learn how to use it in the accessibility review source docs.
Add-ons / Web Extensions
Addon Manager & about:addons
Migrated addon-page-header and addon-card action buttons to the reusable moz-button web component as part of the ongoing Nova restyling of about:addons – Bug 2042200 / Bug 2042204
Extended moz-page-nav-button with a forwarded title property to fix an accessibility issue where the component lacked a label in collapsed state; Landed in Firefox 153, and uplifted to Firefox 152 for about:settings which was already riding the 152 release train – Bug 2040971
Fixed a shutdown-timing bug where a pending GMP update-check timer could fire after XPCOMShutdownThreads started, causing a pref write assertion; Fixed in Firefox 153 – Bug 2043803
WebExtensions Framework
Fixed MV2 content scripts incorrectly injecting into guarded hosts because MozDocumentMatcher::MatchesURI was not consulting CheckGuarded when mCheckPermissions was false; Fixed in Firefox 153 – Bug 2041393
Added support for accessing ObservableArray attributes (such as adoptedStyleSheets) from XrayWrappers and extension content scripts, unblocking extensions that rely on this Web API; Fixed in Firefox 153 – Bug 1751346
Wired runtime_blocked_hosts and runtime_allowed_hosts enterprise policy settings through ExtensionSettings to allow administrators to restrict extension host permissions on managed devices, starting in Firefox 153 – Bug 1805205
Thanks to Mike Kaply for implementing this enterprise policy enhancement.
WebExtension APIs
Fixed promiseTabWhenReady blocking indefinitely on discarded tabs, preventing cleanup of associated resources and potentially causing memory leaks; Fixed in Firefox 153 – Bug 1653876
Fixed webNavigation.onCommitted being dispatched twice for cross-origin iframes loaded under Fission, caused by a redundant OnStateChange trigger firing in addition to OnLocationChange; Fixed in Firefox 153 – Bug 1750196
Julian Descottes [:jdescottes] migrated the markup view to HTML (from XHTML) to fix an issue when editing the markup (CodeMirror 6 does not support XHTML) (#2028058)
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at
@thisweekinrust.bsky.social on Bluesky or
@ThisWeekinRust on mastodon.social, or
send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a
call-for-testing label to your RFC along with a comment providing testing instructions and/or
guidance on which aspect(s) of the feature need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
This week we had quite a lot of changes, a few small regressions that were a bit tough to diagnose, but the week is largely positive, overall.
Notably, we got one massive improvement on the next-solver benchmark in #156187,
and a nice speedup for incremental in #157781.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
WebDriver is a remote control interface that enables introspection and control of user agents. As such, it can help developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 152 release cycle.
Contributions
Firefox is an open source project, and we are always happy to receive external code contributions to our WebDriver implementation. We want to give special thanks to everyone who filed issues, bugs and submitted patches.
In Firefox 152, multiple WebDriver bugs were fixed by contributors:
The latest version of the Firefox Profiler is now live! Check out the full changelog below to see what’s changed:
Highlights:
[Nazım Can Altınova] Add source map symbolication and source view support (#6018)
It requires Firefox changes that will land in Firefox 154, but after these changes, you will be able to see the source mapped function names as well as the source contents!
Firefox gives you many ways to make the browser your own, from privacy settings and AI controls to tab management, custom colors, and more. As we continue to improve Firefox, you get more control over how it works for you.
Today, we’re introducing a redesigned settings experience that makes your options easier to find, understand, and manage.
Over time, some settings pages became crowded, related preferences were spread across different sections, and it wasn’t always obvious where to look for a particular option. The redesign makes settings easier to navigate while preserving existing preferences and the flexibility and control that Firefox is known for.
The passwords and autofill sections, before (left) and after (right) the redesign.
The new settings feature a cleaner layout, modern visual design, improved labels and descriptions, and updated navigation, bringing related categories together. One of the most noticeable updates is the retirement of the long-standing “General” page. Many of the options that were previously there have now moved into more specific areas, including “Appearance,” “Accessibility,” “Languages,” and “Tabs and browsing.”
The redesigned settings include dedicated pages for languages and other categories.
Some options may have moved, but your existing preferences haven’t changed. The customization options you rely on are still available. If you’re not sure where to find something, the search bar can help you locate it quickly. You can also visit Mozilla Support for more detailed guidance.
This redesign reflects extensive user research, including interviews, usability testing, card-sorting exercises, and analysis of usage data. It was also shaped by feedback from the Firefox community through Mozilla Connect, Reddit, and other channels, along with collaboration across Mozilla teams.
Thank you to everyone who shared their feedback along the way. Your insights helped shape the redesigned settings experience, and they’ll continue to guide future improvements as Firefox evolves.
Firefox has been busy introducing updates across productivity, privacy and AI. From Project Nova and browser-wide AI controls to expanded privacy protections and new ways to stay organized, the goal is simple: help you spend less time managing your browser and more time getting things done online.
But building the best browser isn’t just about shipping new features. It’s also about building them alongside the people who use Firefox every day.
Introducing the Firefox roadmap
Today, we’re introducing the Firefox roadmap to give people a closer look at what we’re building and a preview of where Firefox is heading next.
We’ve always built Firefox in the open and our new roadmap is an extension of that.
“Some of the best ideas in Firefox come directly from the people who use it,” said Ajit Varma, head of Firefox. “The roadmap gives our community a new way to see what’s taking shape, share feedback earlier and help guide where we’re heading next.”
The roadmap highlights what we’re working on across Firefox, including productivity, privacy, performance, AI and the technologies that help make the web better for everyone.
Some items on the roadmap will be things we’ve already shared; others we’ll be sharing publicly for the first time. Together, it’ll provide a clearer picture of where Firefox is headed and the areas we’re investing in to build a better browser.
Here’s a look at what’s rolling out now in Firefox 152, and what we’re building next.
Tab Groups are now on Android: When “just a few” turns into dozens of tabs, it’s hard to tell what’s important or which tab had the thing you were actually looking for. Tab Groups have been helping Firefox desktop users bring order to the chaos. Now, they’re starting to roll out on Firefox for Android, turning related mobile tabs into clear threads you can name, color and come back to when you’re ready. iOS support will follow later this year.
Simpler way to manage Firefox settings: We’ve redesigned Firefox settings to make it easier to find what you’re looking for, discover controls you might not have known existed, and truly make Firefox your own. Don’t worry: Your existing preferences aren’t changing; just better organized. Get the details here and visit Mozilla Support for answers to all your settings questions.
Privacy protections you can actually see: You shouldn’t have to worry about trackers every time you browse. Firefox blocks many of them automatically so you can focus on what you came to do. The new Blocked Tracker Widget brings that protection into view, showing how many trackers Firefox has blocked over time, what kinds of tracking activity it stopped and how Firefox is working behind the scenes.
Power users know that even small efficiency improvements add up over time. One of Firefox’s most requested customization features, customizable keyboard shortcuts give you more control over how Firefox fits into your workflow, whether you’re streamlining a routine task, adapting Firefox to your accessibility needs or simply prefer your own shortcuts.
Designed to help people handle everyday PDF tasks without leaving the browser, upcoming PDF editing improvements will include the ability to split, merge and reorganize documents directly in Firefox.
Multi-Account Containers, one of Firefox’s most-loved browser extensions, helps people carve out a separate space for each part of their online life and keep work, personal and other online activities from bleeding into one another. We’re now bringing Containers into the native Firefox experience, so more people can take advantage of one of Firefox’s most distinctive tools without needing to install an add-on first.
Firefox’s free built-in VPN is coming to mobile devices, helping people stay protected across more of the devices they use every day. Whether you’re traveling, connecting from public Wi-Fi or simply browsing away from home, bringing VPN to mobile is part of a broader effort to make Firefox privacy protections available wherever you go.
Sometimes the fastest way to get information is simply to ask. With Quick Answers, people will be able to ask Firefox a question using their voice and receive a concise AI-generated answer right in the browser, with sources available when they want to learn more.
We’re continuing to build Smart Window, our optional and private AI browsing experience designed to help people get answers, compare information and make sense of what they’re already reading online. You can now try it without joining a waitlist.
We’re adding Power Saving Mode to help identify tabs that consume the most resources on your phone and automatically reduce their impact, extending battery life without constantly managing what’s running in the background.
Join the conversation
Try out the latest features, explore what’s coming next and tell us what you think on Mozilla Connect.
We’re also hosting a Reddit AMA on June 24 with Firefox product leaders, so bring your questions.
The past month was busy; the theme was evolution. We went into this quarter with our own ideas for what we wanted to accomplish. However, our users had better ideas. With the release of Thunderbird’s own mail service, Thundermail, the need for a better account settings import process across our services and apps became vital.
We have also heard from our users about issues they had with syncing, notifications, bugs, and more. As such, we refined our roadmap, because the goal is always a better, safer, more private email client, and delivering that experience is more important than any foregone projects. Our roadmap can change, but our goal to deliver the best cannot.
Android
On Android, our focus turned to our import function through a QR code. This helps transfer settings from Thunderbird desktop to mobile. We also ensured that it would work for our new Thundermail project. This allows our early Thundermail users to quickly move their accounts to the Thunderbird mobile app. Additionally, we merged fixes for importing accounts, getting the avatar monogram to match the account immediately after setup, and new translations.
We also began some exploratory work on one of our biggest upcoming projects. Our users have been clear about a recurring issue that they want resolved. Notifications. Notifications on an email client are tricky, especially one like ours, where we support so many different services. Users report not receiving notifications for newly delivered emails, even when polling or push are enabled, notifications appearing improperly in the notification shade, and many others.
We broke this up into two projects. The first priority will be to work on the quick fixes. These are bugs discovered through reports or our own testing. These fixes won’t require an entire refactor of our sync, notification, or database features, allowing us to address user concerns without launching a big project. But we are intending to launch a big project. We’ll do whatever we have to in order to make notifications work as expected. That’s the second planned project, to consider larger performance improvements, even a full refactor of sync, notifications, and the app database if we have to. Prompt email delivery is essential. We’re going to ensure Thunderbird becomes a trusted client for rapid email syncing and notification.
We’ve also begun investigating potential feature flag options. While we currently have internal feature flags for our debug builds, we’re looking into options that we could host ourselves to ensure privacy, while also allowing us to enable features more quickly, without a full update. This would also allow us to roll back any changes that introduce issues without an app update. We hope it can allow us to launch products more quickly, and potentially even give end users more control over the features they have enabled.
iOS
The iOS app is coming along nicely, with the core libraries (IMAP, SMTP, and MIME) set up. We’re working on how to store account data in the local database, as well as starting the email compose functionality. iOS will have a WYSIWYG editor for new messages, just as you’ve come to expect from other email clients. Also, this week has been busy with WWDC and understanding how the new tools and operating system will affect and improve our roadmap, mostly in the user interface.
Our Open Source Community
We wouldn’t be who we are without the open source community at our core. Open source isn’t just how we build software, it’s how we plan, make, and grow. Our community has a say in what we do, which includes making changes, bug fixes, suggesting new features, and voicing complaints – this insight from you is our greatest strength. Over the past month, we’ve heard requests for new features, bug fixes, and changes, and we’ve adapted our plans for the rest of the year to focus on this. And hopefully deliver them in more bite-sized pieces.
First, the community has helped drive our upcoming projects. From notifications to investigations into spam filters, our community is helping drive our objectives. Our priorities and our roadmap have shifted thanks to that feedback. With our community having our back, we’re making the best email client available on iOS and Android, and can’t wait to deliver these improvements. We’re listening and working on these highly requested changes.
A notable contribution from our community came in the form of a fix for our notification widget. The text wasn’t scaling for users with different font size settings. This is a serious accessibility issue. Fortunately, a contributor pushed a fix which ensures the font size scales with the system. We’re grateful for this help, and it’s a perfect example of how we build better together.
Becoming a Contributor
Interested in contributing yourself? It can be tough to figure out where to start or how to go about it. Soon starting development on the Thunderbird for Android app will be easier than ever. We’re moving our documentation around and adding templates and examples to make everything from requesting new features to working on bug fixes, and even documenting your changes easier. We’ve also added a new pull request template to help you write a detailed message explaining your pull request. This includes letting us know if you’ve used AI in the development and to what level it was used.
One note to say with contributions, given our limited team size and resources, we are focusing our efforts on the top items on the roadmap first and foremost. Second, we will spend a couple of weeks solving the largest impact bugs. Then we will spend a week or two supporting what contributions help resolve bug reports or align with our roadmap. We are intrigued about how AI can help us in these efforts, but we are also vigilant about the quality of the code. Potential contributors need a strong understanding of what they are contributing. This means being able to change, improve, and support the code they contribute in the future.
We have just three engineers on each of our iOS and Android teams. We’re supported by wonderful designers and product folks, but we also couldn’t do it without your support. So, thank you. We’re doing our best to make a great product, and with your help, contributions, donations, bug reports, feature requests, and enthusiasm, we’re able to do it better than ever. Thanks for checking in with us!
Harshit enabled video overlay detection in Nightly 153, allowing you to use the context menu to control videos on more pages! We plan on letting this ride out in Firefox 153.
As part of the work for the Project Nova about:addons page restyling, the about:addons sidebar has been migrated to the moz-page-nav and moz-page-nav-button reusable components, improving accessibility and visual consistency with the Firefox Desktop about:settings page – Bug 1881767
WebExtensions Framework
Implemented WebExtensions negative permissions infrastructure, providing the foundations for enterprise policy “blocked host permissions” features – Bug 1745823
Restricted host permission changes for MV3 extensions force-installed via enterprise policy (matching similar behaviors provided by Chrome enterprise policy behaviors) – Bug 1904054
Thanks to Mike Kaply for the implementation of this enterprise policy enforcement feature.
WebExtension APIs
Fixed handling of <all_urls> as an API permission in Manifest V3, ensuring the permission is correctly initialized on extension install – Bug 1758306
Sameem updated the “Take Element Screenshot” command from WebDriver Classic to crop screenshots of elements which exceed the viewport. This aligns with the specification and avoids errors when attempting to capture huge elements.
Much has happened in the last 2 weeks! Here’s a full bug list, and here are some highlights.
Dre fixed the List widget that was creating a new list too eagerly on the New Tab Page (2033592) — prevents accidental list creation and improves the Lists UI reliability.
Reem Hamoui added key dates state to the Sports widget, enabling the Sports card to surface event deadlines/key-date highlights on New Tab so sports users see timely date info.
Scott Downe added a reusable Newtab widget base component to centralize lifecycle, focus/keyboard handling, DOM templates, and telemetry hooks, reducing duplication and making widget behavior more consistent; see Newtab widget base component.
Dre converted per-widget expansion handling to a shared widget expansion handler to unify expand/collapse state management and prevent widgets from incorrectly retaining or losing expanded state; see Convert widget expansion handling to shared widget expansion.
Scott Downe moved widget menu items within New Tab widgets to standardize menu ordering and action grouping, so users find Add/Remove/Configure entries in expected positions across platforms.
Dre fixed a World Clock city search bug for the word clocks widget, restoring expected search filtering/matching so city lookups return correct results.
Scott Downe fixed an issue where the New Tab small weather widget size change didn’t always apply by correcting the widget size update path (JS/CSS layout interactions), improving consistent rendering for small-tile weather across responsive breakpoints and platforms; see Newtab small weather widget size change doesn’t always work.
Nina Pypchenko [:nina-py] added a group stage section to match highlights in the sports widget on New Tab so users now see stage-aware grouping and stage labels on match highlight cards, making tournament context (group vs knockout) visible while browsing highlights.
Maxx Crawford added WCW OMC message strings so World Cup widget messaging flows on New Tab now display the correct copy (localized where available) instead of falling back to missing-text behavior.
Maxx Crawford removed the persistent browser logo when all new-tab features (Top Sites, widgets, content feed) are disabled by adding a conditional render guard in the New Tab component, preventing an orphaned logo (2041033).
Irene Ni shipped multiple visual fixes for the Sports widget Sports widget – various visual fixes (spacing, truncation, icon alignment, clipping) to improve readability and layout on constrained viewports.
Firefox Profiler now has a CLI! We also added a profiler-analysis skill to the Firefox codebase. Once you capture a performance profile, you can ask Claude or an AI to analyze it by providing a link or local path. You can use it to analyze a performance regression or debug an issue if you have a profile at hand.
Drew landed several Suggest improvements: realtime suggestions colors, sports suggestions received World Cup tweaks, and online Suggest via OHTTP was enabled for eligible users in Firefox 153.
James fixed soft-block counting to track autofill dismisses, rather than consecutive backspaces on the same autofill, and added telemetry to measure URLs reintegration after blocking.
Moritz continued refactoring the urlbar code: converted some of the js modules to not be system modules, fixed dynamic results templates, incorrect reuse of result rows, and keyboard shortcuts on the unified search button panel.
Marco removed some unnecessary database transactions, fixed the bookmarks panel folder dropdown on Windows, and resolved several intermittent test failures.
Thanks to Sam Johnson who fixed the bookmark edit panel showing “mobile” instead of “Mobile Bookmarks”.
For years, the Mozilla Community Newsletter has served as a monthly touchpoint for contributors and community members across the Mozilla ecosystem. Coordinated by the Customer Experience (CX) team, it helps keep our global contributor and product communities informed, connected, and engaged through updates, contributor stories, announcements, and opportunities to get involved.
While the newsletter has traditionally been distributed directly to community members, we recognize that many of these updates are valuable to a broader audience as well. That’s why we’re bringing our content into a blog post format, making it easier for anyone interested in Mozilla’s mission, products, and community work to stay informed.
Whether you’re a longtime contributor, a Firefox enthusiast, or simply curious about what’s happening across Mozilla, we hope these updates provide useful insights into the people, projects, and initiatives shaping our community.
In this edition, we’re sharing our latest updates from May 2026. It’s packed with the latest community news, contributor highlights, project updates, and opportunities to get involved in Mozilla’s work around the world.
So, without further ado, let’s dive in!
From localizing to Firefox Enterprise
Long-time Mozillian Valery recently shared an open-source project he built to help Firefox Enterprise administrators manage Firefox deployments more easily called Browser Policy Manager or BPM. Beyond the tool itself, this story is a proof of the long-term value of investing in the community. Stories like Valery’s show how community contributions evolve over time and why fostering a strong, engaged contributor community continues to pay dividends across the Mozilla ecosystem.
Could Firefox users help grow the community by recommending Firefox to friends and family? That’s the question being explored in a recent Mozilla Connect discussion about potential referral programs. Join the conversation to share your thoughts on what would motivate you to recommend Firefox, and what a referral experience should (or shouldn’t) look like.
After years of community interest and requests dating back more than a decade, Firefox 151 now includes support for the Web Serial API. Developers can use Firefox to communicate with and manage serial-connected devices such as ESP boards, Raspberry Pi Picos, 3D printers, CNC machines, and other microcontrollers directly from the web. It’s a long-awaited milestone for the maker and hardware community, and we’re excited to finally see it land in Firefox.
In this community spotlight, we feature Baurzhan Muftakhidinov, whose work has helped bring Firefox and many other open source projects to Kazakh users. His story is a testament to the power of persistence, community, and the importance of keeping smaller languages visible online.
Mozilla Champions the Reintroduction of the American Innovation and Choice Online Act (AICOA)
Today, only a handful of tech companies shape the online experience for the more than 300 million internet users in America. This concentration of power is exactly why we need legislation that advances competition and user choice. It’s all the more urgent as AI transforms not just the tools that people use, but also magnifies the competitive inequities underlying the web itself.
The American Innovation and Choice Online Act (AICOA) is bipartisan legislation designed to curb harmful gatekeeper behaviors of the biggest tech platforms. The bill does so by prohibiting dominant platforms from unfairly preferencing their own products, discriminating against tech competitors, and preventing interoperability — all practices that stop the best product winning and stifle consumer control. The goal is straightforward: companies should compete based on the quality of their products, not by leveraging anticompetitive tactics.
As the builder and operator of the Firefox browser and the browser engine Gecko, Mozilla has firsthand experience with the impact of the exclusionary practices AICOA seeks to prevent. For example, deceptive design tactics deployed by operating systems make it difficult for people to install and keep Firefox as their preferred browser. Browsers are the portal through which people access the open web, and users should define that interaction. AICOA would help limit the ability of operating systems to steer users toward affiliated products through deceptive design choices. Ensuring meaningful user choice online is not just about variety; it reflects values and individual preferences. Openness and innovation thrives when the web is built around platforms that serve people, not the other way round.
Browser engines, while lesser-known, are among the most complex and consequential pieces of infrastructure on the modern internet, impacting user-focused innovations in privacy, security, speed, and more. Gecko is one of only three widely used engines and the only independent browser engine. The importance of that competitive counterweight cannot be underestimated. When platform owners favor their own vertically integrated products, independent challengers face barriers that have nothing to do with product quality and everything to do with a monopolized market.
It’s important to recognize that antitrust reform can make the internet more private and secure than it is today, as we’ve consistently emphasized. For example, in 2021, Firefox was at the forefront of developing technology against cross-site tracking, but could not release the technology to Firefox users on iOS because of app store rules preferring Apple’s own browser engine, blocking alternatives like Gecko.
We’re champions of AICOA and look forward to working with members of Congress to push this legislation forward and tackle longstanding anticompetitive practices. Mozilla thanks Senators Grassley and Klobuchar for their leadership in advancing competition. A thriving tech ecosystem requires an open, fair, and competitive market where innovative services can compete on merit and people can control their own experiences online.
A while back, I stumbled onto something that turned into a rewarding side-project at Mozilla.
Firefox ships with a built-in spellchecker, but it only activates if a dictionary for your language is bundled with the browser. Coverage had grown organically over the years — driven largely by localizers and community members adding support for their own languages. Dictionary work was actually very active in the early years of the Mozilla project, but like many things in a large open-source codebase with a lot to manage, it had quietly received less attention over time, for no particularly good reason. So I decided to change that.
Taking stock
I put together a full inventory dashboard of every third-party dictionary shipped in Firefox Desktop, cataloguing sources, upstream health, and — critically — licensing.
Licensing turns out to be the main bottleneck. Firefox is open-source software, so any dictionary we ship has to carry a licence compatible with the Mozilla codebase. Some excellent dictionaries exist for languages Firefox supports, but their licences don't allow direct inclusion. In those cases, the dictionary can still reach users — but only as a Firefox extension they have to find and install manually, rather than something that just works out of the box.
The goal of the inventory wasn't to point fingers at anything. It was to make the full picture visible, so that anyone who wanted to help would know exactly where to start.
Plugging into the community
Once the inventory existed, the work was really about connecting the right people. Mozilla's localizer community already had the expertise and motivation — what was sometimes missing was a clear entry point. I took care of all the patches myself, so that localizers wouldn't have to deal with the technical side of things. This work was done in coordination with Mozilla's Localization drivers team, who own the dictionary infrastructure and reviewed and merged the changes.
The results
We expanded the number of locales shipping with a built-in dictionary from 30 to 41. This shipped last week with Firefox 151.0.3, and these improvements also benefit Thunderbird users, since both applications share the same dictionary infrastructure.
New dictionaries added: Croatian, English (UK), Georgian, Persian, Slovenian, Tajik, Tamil, Tibetan, Turkish, Welsh, and Xhosa.
Part of the reason for doing this work publicly — building the inventory, filing the bugs, making the gaps visible — was to give people with the right expertise a reason to step in themselves. That's exactly what happened.
For Turkish and Russian, the existing open-source Hunspell dictionaries had become outdated — vocabulary and linguistic rules that hadn't kept pace with how the languages are actually used today. Selim (our Turkish l10n lead) and Valentin (our Russian l10n lead) each decided to take matters into their own hands.
Selim forked the TDD Turkish dictionary and updated it with modern vocabulary, better circumflex support, and performance improvements — the result is hunspell-tr-moz, now shipping in Firefox 151.0.3. Valentin built a new modern Russian dictionary from scratch, ru-spelling-dictionary, released under MPL-2.0. It's currently available as a Firefox extension — if you use Russian, Valentin would appreciate feedback on the quality before it's integrated directly into Firefox.
Both projects are public and open-source.
What's still in the pipeline
The licence question is also quietly resolving itself for a couple more locales. The maintainers of the Kabyle and Asturian dictionaries have agreed to relicense their work to allow direct inclusion in Firefox. Once that's done, those communities will join the list too.
There are still gaps in the inventory. Some are licence issues that may resolve over time. But for many of the remaining locales, the honest answer is that we simply haven't looked hard enough yet. Dictionaries are often individual passion projects or work coming out of linguistics circles — they exist, but finding them takes investigation. If you know of a dictionary for a language Firefox doesn't currently support, that's exactly the kind of lead worth following up on.
An open invitation
Mozilla is still a place where a motivated contributor can find a corner of the project, do meaningful work, and have a real impact — without needing to be a browser engineer or a Mozilla insider.
The inventory dashboard is public. If you're a localizer, a linguist, or a dictionary maintainer and you want to help bring spellchecking to more Firefox users, the gaps are clearly documented. And if you maintain a dictionary that could be included but licensing is an obstacle, that's a conversation worth having.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at
@thisweekinrust.bsky.social on Bluesky or
@ThisWeekinRust on mastodon.social, or
send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization.
If you are a feature implementer and would like your RFC to appear in this list, add a
call-for-testing label to your RFC along with a comment providing testing instructions and/or
guidance on which aspect(s) of the feature need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on Bluesky or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on Bluesky or Mastodon!
A fairly noisy week, with a bunch of small regressions contained within,
leading to a slight increase on average in instruction counts. This week had a
lot of large rollups, likely due to some CI problems, but thankfully many of
those came with pre-triaged perf results by the time (thank you to those
triagers!). Roughly similar slight regressions for cycles and wall times across
the week.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
For a limited time, where the VPN is available, users can get unlimited VPN bandwidth in Firefox – up from the 50 gigabytes monthly limit — plus access to over 25 country locations to browse from. Don’t have Firefox yet? Try it now.
Firefox’s free built-in VPN usually gives eligible users 50 GB of free bandwidth each month. From now through Aug. 31, we’re making that unlimited, so you have more room to browse privately while you travel, work from public Wi-Fi or connect from somewhere new. Not only will users get unlimited bandwidth, but we’re also unlocking access to 28 country locations to browse from during this period. The VPN returns to its standard 50 GB monthly limit and a standard location set on Sept. 1.
Whether you’re using the airport Wi-Fi, booking a last-minute flight or trying to access websites away from home, here are a few ways Firefox’s VPN can help while you travel:
Stay protected on public Wi-Fi at the airport, train station or hotel
When you’re traveling, public Wi-Fi is often part of the deal. But those networks can make it easier for others to spy on your traffic and see which websites you’re visiting. Firefox’s built-in VPN adds another layer of privacy by helping mask your IP address and makes it harder for others on the network to see your browsing activity.
Browse like you’re back home
The web can feel a little funky when you go abroad. Sites may load in another language, show a different local version or have trouble recognizing where you usually browse from. Maybe you need to schedule your monthly pharmacy prescription, but the site isn’t loading the way it normally does from home. Or maybe you’re trying to order a new dress to your apartment but the address isn’t registering properly.
With Firefox’s built-in VPN, you can switch your browsing location back to your home country so the sites and services you rely on feel a little more familiar while you’re away.
Or choose where you browse from
Firefox can recommend a VPN location based on what’s fastest and most convenient. But you can also choose from more available locations, whether you want to browse closer to home or see how the web looks somewhere else.
The full set of countries available during this summer period include: Australia, Austria, Belgium, Bulgaria, Canada, Chile, Colombia, Denmark, Finland, France, Germany, Ireland, Italy, Malaysia, Mexico, Netherlands, New Zealand, Portugal, Singapore, Spain, Sweden, Thailand, Norway, South Africa, United Kingdom and United States.
Turn off VPN for specific sites
Some sites don’t always work smoothly with VPNs. If one is giving you trouble, you can turn the VPN off for that website right from the panel. You can also add sites to a list in advanced settings if you don’t want them to connect through the VPN.
Free VPN for wherever summer takes you
Wherever you’re logging on this summer, Firefox’s built-in VPN gives you an easy way to add another layer of protection while you browse. More control for summer browsing, right where you need it. As it should be.
only bounds are going to be the most impactful change to Rust that you’ve never heard of. They are currently being designed and developed by the Arm team (David Wood, Rémy Rakic, et al.) as part of the Sized Hierarchy and Scalable Vector Extension project goal. This post explores the feature and aims to answer a particular question about the design (the scope of bounds, I’ll explain). But before I dive in, I want to give a bit of context.
Rust generics have a Sized bound by default today
In today’s Rust, every type parameter (except for Self) has a default bound called Sized:
// So this function...
fnidentity<T>(t: T)-> T{t}// ...is actually short for
fnidentity<T>(t: T)-> TwhereT: Sized,// <-- Added by default!
{t}
A type T implements Sized if the compiler can compute the size of a T value at compilation time. This is true for almost every type, with a few notable exceptions. Consider [u32], which refers to “some number of u32 instances”. We know that a single u32 is 4 bytes, but without knowing how many u32 there are, you can’t know the size of [u32]. This means you can’t have a value of type [u32] on the stack (how big should the stack frame be?).
You opt out with ?Sized
However, if you have a function like by_ref, that just takes the value by reference (i.e., by pointer), you shouldn’t need to know how big the [u32] value is, because you’re not manipulating it directly. You can have a type parameter U that doesn’t require Sized, but you have to explicitly “opt out” from the default bound:
fnby_ref<U>(t: &U)whereU: ?Sized,// <-- Opt out from the default
{}
As a fun bit of historical trivia, this system was introduced way back in 2014 to accommodate Dynamically Sized Types. Before that, &[u32] was actually a built-in, indivisible type; we even wrote it like [u32]/& for a time.1
But Sized vs ?Sized isn’t enough for everything we need
The Sized vs ?Sized design has served us reasonably well but it is also showing its limits. It turns out that “value has a statically computable size” vs “each value has a distinct size computable at runtime” doesn’t cover all the things you might want. For example, extern types are types whose values have no known size, even at runtime. And then Arm’s Scalable Vector Extension want to describe SIMD types where every value of the type has the same size (unlike str and [T], where each value can have a different length) but where that size is not known until runtime.
A richer Sized hierarchy
Rather than just Sized or ?Sized, what we really want is to have a richer hierarchy. The current plans look something like this:
trait Sized means that all values have the same size and that size can be computed knowing only the type.
trait MetadataSized means that values can have different sizes and that size can be computed given the metadata attached to a reference to the value. Examples include [T] or dyn Trait.
trait MaybeSized is implemented for all values and tells you nothing about the value’s size.
Two caveats:
I’m excluding the way that Arm’s Scalable Vector Extension fit into this, because it’s orthogonal.
The trait names aren’t settled. I’m using the names I understand the libs-api team to prefer; they’re not my favorites, but that’s ultimately the team who owns stdlib bikesheds, so I defer to them.2
Problem: ?Sized notation doesn’t scale to this hierarchy
But now we have a kind of problem. The ?Sized notation was predicated3 on the idea that users should specify the default bound they are opting out of – i.e., the ? is meant to say “I don’t know if this is Sized or not” (unlike the default, where you know it is Sized). But “opting out” from a bound doesn’t work so well with a multi-level hierarchy. When you write ?Sized, does that correspond to T: MetadataSized (but not T: Sized)? And what if we want to insert another level in between T: MetadataSized and T: Sized later? Then we either have to change what T: ?Sized means (to refer to the new bound) or we have to have T: ?Sized drop two levels down the hierarchy. Even more annoying, what do we do while that middle rung is unstable? Surely T: ?Sized shouldn’t refer to an unstable trait… what if we decide to remove it
Solution: only bounds
The new proposal is to write T: only MetadataSized or T: only UnknownSized instead of T: ?Sized. An only bound combines two things:
Like any bound, it includes a “minimum requirement” – i.e., T: only MetadataSized means that T must implement at leastMetadataSized.
It additionally disables some default bounds – i.e., we will not add the default T: Sized bound.
The name only comes from the fact that T: Sized implies T: MetadataSized. So the default of T: Sized already means that T: MetadataSized for free; but when you write only MetadataSized, you are saying “I don’t need the full hierarchy, just MetadataSized will do”.
only bounds work like normal bounds: ask for what you need
A nice feature of only bounds is that they work more like a regular bound. Whereas a ? bound is saying “I don’t need this”, an only bound is saying what you do need. So e.g. if you are writing a function that just has references to values of type T does not care what their size is, you can write
fnby_ref<U>(u: &U)whereU: onlyMaybeSized,{}
If you are writing a function that does need to compute the size of values of type V, you can ask for that capability:
only bounds allow for new levels to be added later
A nice feature of only bounds is that, later on, we can add new levels to the hierarchy, and they work normally. For example, suppose we wish to add something like Aligned where the size is not known at compilation time but the alignment is. We could change the hierarchy to
and functions with U: only MaybeSized (like by_ref) and with V: only MetadataSized (with checks_size) would continue to have the same requirements. But new functions could be written with T: only Aligned that would use the new bound. And there is no conflict with stabilization; code that writes T: only Aligned can be considered unstable until that middle hierarchy is finalized.
only bounds compose normally
Like any other bound, only bounds are combined with other bounds to form the overall requirements. So it is possible to write e.g. T: only MetadataSized + Sized. This is equivalent to T: Sized and therefore equivalent to the default and therefore kind of pointless, but you can write it. Similarly, given that trait Clone: Sized, if you write T: only MetadataSized + Clone, that is kind of pointless too: you might as well write T: Clone, which would be equivalent. We plan to have a warn-by-default lint for that.
Scaling only to other “default bound families” (speculative)
The final strength of only bounds is that they allow us to introduce whole new families of default bounds. One example is the idea of introducing a Move bound. Note that this is a distinct feature and is not covered under the current RFC.
All types in Rust today are “movable” and “forgettable”, meaning that you can memcpy the value from place to place so long as you stop using the previous location and you can recycle the memory where it is stored without running the value’s destructor. There is one notable exception – when you pin a value, it can no longer be moved, and you must run its destructor before its memory is reused – but otherwise this is a hard-and-fast rule. And that’s annoying!
The problem is that not being able to guarantee that a destructor runs blocks a lot of unsafe code patterns. For example, scoped tasks a la rayon depend on a destructor for safety. In sync code, this works because we’ve decided it’s UB to unwind a stack frame without running the destructors of values stored there, and so if you put a local variable on the stack, you can be sure its destructor will run. But that doesn’t work in async code! And there are times when unwinding without running destructors would be nice.
The solution is to introduce a second family of default traits. Unlike the Sized family we saw before, this family defines fine-grained capabilities about how values of that type can be used:
Forget, the default, says that you can recycle the memory for a value without running its destructor.
Leak says that you can skip running a destructor for a value, but only if you never reuse the memory where the value resides.
Destruct says that if you have a value of this type, you can reuse the memory where it resides by running its destructor.
Copy, which already exists, says that you can memcpy the place and keep using the original place; it’s not really a default, but I included it because it is relevant.
Move, another default, says that you can memcpy the value to a new place if you stop using the original.
Access is the root of this family. It indicates a value that can be “accessed in place” (basically, any value at all).
This introduces new checks into the compiler:
When you move a value (i.e., a = b where b is not used later), we will check that the type implements Move (whereas today, it is always allowed).
When you exit a scope, we will check that the values in local variables have either been moved or have a type that implements Destruct.
Some implications:
If your function owns a value of type T: only Destruct, then you must destruct it before your function returns. You can’t move it (because you don’t know if it implements Move) and you can’t leak or forget it either.
If your function owns a value of type T: only Move, then the only thing you can do with it is move it somewhere else. You can’t drop it (because you don’t know if it implements Destruct).
No function can own a value of type T: only Access, because you wouldn’t be able to move it nor drop it, and hence you could not return. But you could have such a value (say) in a static.
How only bounds could work in the presence of multiple families
The spur for writing this blog post was a question in a lang team meeting on how only bounds ought to work given the existence of multiple “families” of default traits, as I described above. Although the current RFC is looking only at the Sized traits, we expect to look at the “access family” in a future RFC, so we want to be sure we are not making any decisions that won’t scale to cover both.
The way I imagine it working is like this. Each default trait is associated with one or more “families”. When you have an only bound, it “opts out” from all default traits in each family that the trait is associated with:
T: only Move opts out from Forget, Leak, Destruct – but not Sized.
T: only Destruct opts out from Forget, Leak, and Move – but not Sized.
T: only MetadataSized opts out from Sized – but not Forget or Move.
T: only MaybeSized opts out from Sized – but not Forget or Move.
You may also want to “opt back in” to some defaults. For example, T: only Move + Destruct is a sensible thing to do. It means values that can be moved and destructed but not leaked or forgotten.
Examples
Option::map requires only Move
map is an example of a function that only needs Move. You need to be able to destructure self (which moves the optional value out into a local variable v and then invoke the closure op, which again moves the wrapped value v:
One interesting thing is the result type U. Using only the stuff I wrote in this blog post, it needs to be only Move, because the result will be moved into the Some value and so forth. But in-place-init would allow for this definition to omit the U: only Move bound because we could statically guarantee that the Option will be constructed in place and never moved after that.
Option::or requires only Move + Destruct
The a.or(b) method on Option returns a if it is Some and otherwise returns b. This is an interesting one because the value b may not be used and therefore requires only Move + Destruct bounds.
impl<T: onlyMove>Option<T>{fnor(self,alternate: Option<T>,)-> Option<T>whereT: Destruct,// <-- because it may be dropped
{matchself{Some(v)=>Some(v),// drops `alternate`
None=>alternate,// moves `alternate`
}}}
Rc requires MaybeSized + Leak
The Rc type is an example where we would want to relax bounds from both families:
structRc<T: onlyMaybeSized+onlyLeak>{}
I believe the proper minimum bounds for Rc are:
only MaybeSized because while it can store MetadataSized or Sized things, it doesn’t have to, it can also store things of an non-computable size (although it does raise the question of how they would be freed, but that’s an allocator concern).
only Leak because Rc values can form cycles and thus we can’t ever guarantee the destructor will be run. Interestingly, Rc<T> can implement Forget even if its contents don’t.
Frequently asked questions
What is actually under RFC today?
The post may be a bit confusing here. The current RFC is looking only at the proposed “Sized” traits. The Access family is a speculative future extension that we are exploring but at a much earlier stage.
Can I use only with any trait?
In the beginning, the plan would be that only can only be used for well-known, default traits (e.g., Move, Sized, etc). In the future though there are some thoughts to generalizing it.
Why not opt out from all defaults at once?
An alternative that was proposed is to have the opt-out be per-type-parameter. So you might write something like
fnfoo<T: MetadataSized+?default>
which would “opt out” from all defaulted bounds. Obviously we’d have to bikeshed the syntax, but ignore that for now. The question is whether opting out of all defaults is better than opting out of a single family. I prefer the per-family option for two reasons:
First, things like T: only Move demonstrate that you might very reasonably wish to opt out from a single family but retain the default Sized bound. I think it’s likely that there will be many functions that want to opt out of SizedorForgetbut not both.
You might think that we could make Move: Sized to get the same effect, but I think that would be a mistake. The fact that a value’s size must be computed dynamically doesn’t inherently mean it can’t be moved.
Second, it makes it harder to introduce new families later, if we decide there are other orthogonal properties of values that we’d like to relax.
Why do you think it’s likely that people want to opt out of being SizedxorForgetbut not both?
Because the Forget, Move, and similar traits mostly apply to owned values. The examples we saw with Option<T> were quite typical. And when you are moving values of type T around, you need that T to be Sized.
But we saw that Rc wanted to opt out of both families with only Leak + only MetadataSized, right?
Yes, that’s true, and I think that particular combo will be common. I don’t think that’s an argument for the ?default approach on its own, though, particularly since that case would not be much cleaner or shorter…
impl<T: ?default+Leak+MetadataSized>Rc<T>{}
…what I think that argues for is actually trait aliases and shorthands.
Wait, trait aliases and shorthands? Can you elaborate?
Yes! I think that a future RFC could extend only bounds to allow you to define trait aliases with “only bounds” as supertraits:
traitRefCountable=onlyLeak+onlyMetadataSized;// Equivalent to:
// trait RefCountable: only Leak + only MetadataSized {}
// impl<T> RefCountable for T where T: only Leak + only MetadataSized {}
You could then use an only RefCountable bound to define Rc<T>:
impl<T: onlyRefcountable>Rc<T>
Without the only,T: Refcountable would just be a regular trait bound and would not opt-out from any defaults.
Can we use a “root” trait to opt out of all defaults?
Yes, we could! You could define an alias like Value:
traitValue=onlyAccess+onlyMaybeSized;
Since Access and MaybeSized are both implemented for all types, this effectively becomes part of both families:
Then you can do T: only Value and opt out from both families at once.
If we did that, what would happen if we wanted to add a new family in the future?
Ay, there’s the rub. If we wish to add a new family in the future, let’s say for values that don’t live in the same memory space (T: only Distributed…?), then Value would be “out of date” because code written against Value would still be assuming uni-memory-space values. But we could make Value into an edition-dependent alias or something like that, as has been discussed.
Can we decide whether we want Value later?
Yes! We can introduce a root trait at any time. So we can add the Sized-ness family first, then the Access family, and then see how we feel. Maybe we find people are very commonly opting out of both– in which case, some aliases are useful, or perhaps a Value variant.
The only way we might “regret” it is if, in practice, people usually just opted out of both and then opted back in to what they want specifically. But we already know that T: only Move will be common and clearly T: only Value + Move + Sized is more awkward in that case, so I don’t consider that very likely.
Why the name Destruct and not Drop?
That name comes from the const trait RFC. There are a few reasons to move away from Drop. The first is that it is possible to have a destructor even if you don’t implement Drop: Drop really refers to user-provided logic in the destructor, but the compiler adds its own logic (“drop glue”, it’s sometimes called) to drop all the fields in the value. The second reason is that the Drop trait itself needs some revision, so moving away from that name lets us have other ways to specify custom logic (e.g., pinned self, or by-value, etc etc).
How does this interact with const traits anyway?
Quite beautifully! In fact, the proposal from Arm for SVE is to introduce the idea of T: const Sized being “a type whose size can be computed at compilation time”, which I find quite elegant. Similarly T: const Destruct was proposed by the const RFC as a way to say that a value has a constant destructor.
It’s annoying to write T: only Move + Destruct. Couldn’t we have Destruct imply Move so that I can just write T: only Destruct?
My original proposal for introducing linear types had Destruct extending Move. This would mean that the Option::or proposal could simply do U: only Destruct and not U: only Move + Destruct. However, Alice Ryhl and others pointed out that there are immovable types that must nonetheless be destructed, so it doesn’t make sense to combine those.
I want to close with a meta-observation and a big shout-out to the Arm team. I think they are showing how awesome open-source can be. The Arm team’s primary motivation is adding support for Scalable Vector Extension. This helps Rust make full use of Arm processors. This is, in and of itself, a laudable goal, and valuable to Rust: One of Rust’s assets, in my view, is that it gives you access to all the power your processor has to provide, and that should include unique extensions.
But rather than add the feature as a kind of special-case extension to Rust, the Arm team is going further and driving a general purpose improvement, one that will unlock a bunch of other features (extern types and, to some extent, guaranteed destructors; guaranteed destructors themselves unlock scoped async threads and better Wasm integration). I love that.
In fact, I recall that in one of my blog posts I proposed writing "" as the way to spell &str. I kinda wish we had done that just for the sheer wackiness of it (fn foo(name: "")). ↩︎
I prefer names that refer to the operations that can be performed on the values, so e.g. instead of MetadataSized I would prefer SizeOfVal, since it means that you can invoke the std::mem::size_of_val function on it. ↩︎
Your browser tabs say a lot about your life: work projects, vacation plans, shopping carts and all the rabbit holes in between.
Add the world’s biggest soccer tournament to the mix, and your browser is suddenly juggling scores to check, streams to watch, lineups to scan and group chats to keep up with. And since many matches kick off during the workday, there will be lots of temptation to just sneak a peek at the action between meetings.
Firefox is built to be your ultimate second screen. When the tournament is on, keep Firefox open to follow the action, keep up with the conversation, and stay on top of everything else happening online – whether you’re watching from the couch or checking in on your mobile device on the go.
You’ll find a World Cup widget, custom wallpapers, and game-day multitasking tools. Plus, Firefox is teaming up with Trevor Noah, a soccer superfan, as he hosts live watch parties for the tournament moments everyone will be talking about.
Your second screen for every match
When the action is happening fast, keeping up should be as easy as opening a new tab.
Firefox’s World Cup widget gives you the latest tournament updates every time you open a new tab (and you can turn it off anytime). With key match information always within easy reach, it’s easy to stay on top of the action without bouncing between apps or having to browse around.
You can follow your favorite teams and even customize Firefox with wallpapers that bring big fan vibes to every new tab. To get started, open a new tab and click the Customize icon at the bottom of the page.
Game-day pro moves
Pin the picture
With picture-in-picture in Firefox, you can detach a video from its tab and pin it anywhere on your screen so you can keep watching while working on other stuff.
Split the view
Open two tabs side by side in one window with split view. That way, you can keep live updates on one half and stats, searches or chats on the other.
Calm the chaos
Remember what we said about your tabs representing your life? While 99 tabs of fandom can make it feel more chaotic, your browser doesn’t have to.
With tab groups in Firefox, you can create separate groups for:
soccer matches and live scores
travel plans and itineraries
work or school projects
summer shopping and event planning
weekend inspiration and future adventures
Hang out with Trevor Noah – World Cup and Firefox superfan
Match days are better with good company. This summer, Firefox is teaming up with Trevor Noah to be his second screen sidekick for his World Cup watch party on YouTube.
Hosted live throughout the tournament, the series will feature Trevor alongside some of his best friends plus celebrity guests as they react to matches, highlights and the internet moments coming out of each day’s games.
Trevor is a longtime Firefox user whose comedy and commentary have explored how technology shapes everyday life. That makes this collaboration feel especially fitting for Mozilla, a company built around the idea that the internet should work better for everyone.
“I’m grateful to our incredible brand partner Firefox for helping make this series possible and for believing in the power of sport to bring people together,” said Noah.
“Events like this are some of the biggest shared experiences on the internet,” said John Solomon, Chief Marketing Officer at Mozilla. “While many people stop their lives for the World Cup, those that can’t follow them while working, traveling, connecting with friends and family, and doing everything else they need to do online. Firefox is built for moments like this, and Trevor is a fitting partner. He’s a longtime Firefox user who believes, like we do, that technology should work for people, helping them stay connected to the moments, information and communities they care about most.”
Make Firefox your World Cup sidekick this summer. Follow the tournament with the World Cup widget, multitask like a pro with picture-in-picture, split view and tab groups, and get into the spirit with custom wallpapers, all in the browser that helps you get more out of every match.
I haven't used Bleach on a project in years, but I still had some time to
maintain it. That changed about a year ago when I got re-orged into a new role
and I haven't had time to do any Bleach work since then.
To recap, Bleach sits on top of
html5lib which hasn't
been actively maintained in years. It is dangerous to maintain Bleach in that
context.
We vendored html5lib so we could make adjustments to the library to keep Bleach
going. This is not a sustainable approach, but it was ok for the short term.
Over the years, we've talked about other options:
find another library to switch to
take over html5lib development
fork html5lib and vendor and maintain our fork
write a new HTML parser
etc
None of those are feasible for me.
Bleach has been a solo-maintained project for a while now. The world is crazy
and it's much harder to build a team of trusted maintainers now than it was (or
at least, it sure feels that way). I don't see any possibility of increasing
the maintenance team or passing it to someone else responsibly.
Switching contexts from my regular work to Bleach is really hard. Bleach is
complicated, the problem domain is complicated, and there's a lot of nuanced
context. I can't just switch gears, spend 15 minutes on Bleach to do something,
and then switch back to the rest of my day. I periodically get nag messages
about this which are entirely valid, but there's nothing I can do about it.
It doesn't feel great.
Then in 2025, Emil, a long-time Bleach contributor, built
justhtml which gives us an easy
migration path off of Bleach. He even took the time to write a
migration guide.
From the first commit on 2010-02-18 to today's final commit on 2026-06-05,
the Bleach project lasted 16 years, 3 months — 5,951 days, or about 16.29
years.
There were 64 releases.
There were roughly 960 commits.
From 80 roughly contributors
Top 3:
Will Kahn-Greene: 462
James Socol: 182
Greg Guthe: 133
Roughly 5,040 lines of Python code excluding the vendored html5lib.
I was maintainer from October 2015 to now--that's a little under 11 years.
It feels weird to end a project that's outlived many of the Mozilla sites and
Python web frameworks it was designed to protect.
What happens now?
This is the end of the project.
Bleach. Last release.
If you're still using Bleach, I think you have three options:
End your project. Maybe you don't need to be maintaining your thing
anymore? Use Bleach as your reason to exit and do something different with
your time on Earth.
Switch to the sanitizer API. Rework your project to use the sanitizer API.
Swap Bleach out for justhtml. Emil provided a
migration guide
for switching from Bleach to justhtml.
Good luck with whatever option you choose!
Thanks!
Many thanks to James who created Bleach and
gave it a set of first principles that guided our choices for 16 years.
Many thanks to Greg who I worked with on Bleach
for a long while and maintained Bleach for several years. Working with Greg was
always easy and his reviews were thoughtful and spot-on.
Many thanks to Emil who was
a contributor to Bleach for a long while and created
justhtml
providing Bleach users a migration path.
Many thanks to Jonathan who, over the years,
provided a lot of insight into how best to solve some of Bleach's more
squirrely problems.
Many thanks to Sam who was an indispensible
resource on HTML parsing and sanitizing text in the context of HTML.
Many thanks to all the users and contributors of Bleach!
We’ve disabled the CSS filter implicitly applied to WebExtension pageAction SVG icons across all release channels starting in Firefox 152, completing the deprecation
NOTE: The blog post published at WebExtensions API changes in Firefox 149-152 provides to extensions developers more details about this deprecation and links to the related MDN docs.
Fixed long-standing regression on the autocomplete and datalist popups for extension inline options pages on about:addons (introduced in Firefox 68 by Bug 1532724, fix shipping in Firefox 152) – Bug 1595158
WebExtensions Framework
Fixed access to web-accessible resources declared with <all_urls> from sandboxed documents (null-principal URLs), restoring extension redirects from the context-menu search flow, starting in Firefox 152 – Bug 2033905
WebExtension APIs
Added exhaustive test coverage for tabs.move() against additional edge cases related to split-view tabs – Bug 2029092
DevTools
Andreas Farre improved the Session History tab in the Application panel (still behind devtools.application.sessionHistory.enabled)
made sure that calls to History.replaceState are reflected in the UI (#2037359)
Julian Descottes [:jdescottes] fixed the most frequent DevTools crash we were observing in Telemetry, adding a guard against IDBTransaction errors when retrieving breakpoints in the Debugger (#2030260)
Julian Descottes [:jdescottes] reduced the overhead we had because of network requests monitoring by only decoding response content when the user actually want to see the response (#2026228)
Sylvestre ported some linters (e.g. file-whitespace, test-manifest-toml, license, file-perm, rejected-words & more) to Rust to help improve the runtime of the code review bot.
We did our first region-specific trainhop on May 11th (just 15% of the US), and turned on HNT Nova (and sometimes Widgets) for those clients to get some advance-data of its behaviour in the wild! A note that HNT Nova gets turned on for everybody when Firefox 151 ships on May 19th.
We’ll be launching a similar experiment in the DE, probably on May 12th, also at 15% population.
Most of the team is heads down building out a sports-tracking widget, attempting to get that ready in time to be generally available for the upcoming World Cup event.
Dre landed a new world clock widget, which is currently off by default, but pretty snazzy!
If you want to financially support the development of Rust, please consider donating to the Rust Foundation Maintainers Fund.
A few months ago, the Rust Foundation announced the Rust Foundation Maintainers Fund (RFMF). Since then, the Rust Project has been closely cooperating with the Rust Foundation to determine how exactly this fund will be used to support Rust maintainers. This resulted in the acceptance of RFC #3931, which established the Funding team and the Maintainer in Residence program.
The primary goal of the Funding team is to ensure that maintainers who work on Rust and its toolchain will be properly supported. We will talk to Rust Project members to figure out their funding situation, meet Rust team leads to learn about their maintenance needs, approach companies to find opportunities for them to invest into Rust by supporting Rust maintainers, coordinate various funding efforts and ensure that the beneficial effects of funded maintenance are visibly promoted, with the help of the Content team.
Maintainer in Residence is a new program dedicated to financially supporting existing Rust Project maintainers1. Each Maintainer in Residence will be funded to maintain one or more critical parts of Rust, such as the compiler, the standard library, Cargo, Clippy or one of many other projects that the Rust Project develops and maintains. The funded work will include activities such as performing large-scale refactorings, code reviews, unblocking new features, issue triaging, mentoring other contributors and more, and will be split between priorities guided by the teams they are supporting and priorities of their own choosing within the Project. Where applicable, Maintainers in Residence are also encouraged to propose, champion, and drive forward Rust Project Goals.
The goal of this program is to provide stable and long-term funding so that maintainers can focus on important work that ensures the long-term health of Rust. The funding team will select Maintainers in Residence based on funding availability and maintenance needs within the Rust Project, and help ensure that they are successful. We expect that this will usually be a (near) full-time position, but that will depend on the nature of the work and the area of maintenance.
This program extends our existing support for Rust maintainers, such as the program management program and the compiler-ops program. An important development is that we now have a centralized mechanism for gathering donations from both individuals and companies, and a dedicated team that will help direct those funds to specific maintainers. You can find more details about the funding team and the Maintainer in Residence program in the RFC.
We expect to hire the first Maintainer in Residence in the upcoming months and announce it on this blog, so stay tuned!
How to contribute funds
If you are an individual who wants to help Rust succeed and thrive, you can donate to the RFMF through GitHub Sponsors2. Companies who would like to invest in better maintenance of Rust can also donate through GitHub Sponsors or they can contact the Rust Foundation directly.
The important thing is that all proceeds from this fund will be directly used to support Rust Project maintainers. We currently expect that to happen primarily through the Maintainer in Residence program, but it can also be done in the form of smaller-scale grants or other mechanisms, as determined by the Funding team. We will figure this out on the go, as this is also quite new for us.
We really appreciate each donation, however small, because with more money we can hire more maintainers to ensure that we can continue to develop Rust and that important improvements are not blocked on maintenance tasks. This is especially important at this time, where Rust is starting to get used more and more in the industry in various application areas, which increases the need for sustained maintenance. The importance of multiple funding sources is underscored by an unfortunate trend we currently observe, where key Rust maintainers are losing their funding for Rust work due to budget shifts. The Rust Foundation Maintainers Fund is designed to provide stable funding for Rust maintainers that is less dependent on sudden shifts in the job market and the IT industry.
As with most things, there is no one-size-fits-all solution, so there are multiple ways to support Rust financially. The RustNL Maintainers Team recently hired several Rust Project maintainers. Previously, we wrote about how you can support specific individuals working on Rust. And there are also Rust Project Goals in search of funding. We welcome all efforts that can help support Rust Project maintainers, who often do work that is near invisible and thankless, while at the same time incredibly important and necessary, on a volunteer basis.
Thank you for considering sponsoring the development and maintenance of Rust! You can find more information about funding Rust on our Funding page.
This program was inspired by the Developer in Residence concept used by the Python Software Foundation (PSF), with which we led several helpful discussions. Thank you, PSF! ↩
Note that the fact that GitHub Sponsors is currently enabled on the rustfoundation GitHub organization, and not the rust-lang organization, is an implementation detail that might change in the future. All donations raised on this Sponsors page will be routed to the Rust Foundation Maintainers Fund and will be spent on directly supporting Rust Project maintainers. ↩
The profile backup mechanism has been enabled by default for all desktop platforms in Nightly, as well as Beta! The current plan is to have this ride out to Firefox 151 for Windows, macOS and Linux on May 18th!
This feature, when enabled, will create a copy of your profile data in the background and store it in a single file on your file system that you can restore from.
You will be able to manage this feature in Settings under Sync (for now)
As followups to the recent addition to the WebExtension tabs API to support the new SplitView tabs feature, tabs.group() and tabs.ungroup() have been fixed to work correctly with split view tabs, and fixed split views being prepended instead of appended to tab groups when adopted into a new window – Bug 2029099 / Bug 2029534
Adaptive autofill has been enabled on Nightly.
Previously, autofill only completed domains (e.g. typing red autofilled reddit.com). Now it can also complete full URLs for pages you visit often (e.g. red → reddit.com/r/firefox), learning from what you actually click in the address bar. If a suggestion isn’t helpful, you can now dismiss it so autofill learns what not to show you too.
Markus Stange [:mstange] implemented dynamic toolbar on top in RDM (#1978145), but also implemented some static skeleton UI so it’s closer to what we actually have in Firefox for Android
dynamic toolbar is behind a pref: devtools.responsive.dynamicToolbar.enabled
it can be put on top by setting devtools.responsive.dynamicToolbar.onTop, otherwise it’s at the bottom
In preparation for the Project Nova restyling of the about:addons page, we have refactored about:addons into separate per-component ES modules, splitting the monolithic aboutaddons.js and aboutaddons.html into 16 dedicated component files under components/ (with no behavior or UI changes) – Bug 2032014
NOTE: if you have working on patches with changes to about:addons internals it is very likely you’ll need to rebase and solve merge conflicts hit on top of this refactoring, the internals are still largely the same as before but don’t hesitate to reach out to the Addons team if you have doubts / questions or need help to figure out how to adapt your patch of top of these changes
WebExtensions Framework
Fixed exportFunction to preserve the constructibility of the wrapped function instead of unconditionally making all exported functions implicitly as constructors – Bug 2033173
Thanks to Gregory Pappas for contributing this improvement to the Content Scripts’ Xray Wrappers helpers!
Fixed a Firefox 151 regression where extension content scripts accessing location.ancestorOrigins caused subsequent page script reads of the same property to fail with “Permission denied”, breaking sites like Gmail – Bug 2034329
Thanks to Simon Farre for promptly investigating and fixing this recent regression!
WebExtension APIs
Updated sessions.getRecentlyClosed() to remove the hardcoded cap when maxResults is omitted – Bug 1392125
Shoutout to Amine Zroual for contributing this enhancement to the sessions WebExtensions API!
DevTools
Artem Manushenkov fixed an issue where autosuggestion popup was removing overridden indicators from properties in the Inspector (#1983408)
Andrea Marchesini [:baku] fix DevTools cookie header serialization for long cookies, which could lead to cookies not being visible in Netmonitor (#2031299)
Julian Descottes [:jdescottes] fixed a toolbox crash that was happening we couldn’t find a localization file (e.g. when using a language pack on Nightly) (#2028930)
Nicolas Chevobbe [:nchevobbe] improved @container tooltip so it show the value of variables used in style()(#2030239), has enough contrast in dark mode (#2033782) and contains a link to select the container (#2031688)
Thanks to volunteer contributor Anthony Mclamb for his patch that disables the legacy EdgeHTML Edge migrator! Once that finishes rolling out, presuming no surprises, we’ll go ahead and remove the migrator entirely.
New Tab Page
Nova for New Tab has ridden the trains to Beta! It will be enabled by default, globally, when Firefox 151 goes out to release on May 19th
It’s possible that we’ll do a train-hop coupled with an experiment to enable HNT Nova for a few clients a bit earlier.
Maxx Crawford enabled Nova designs for New Tab, rolling out the updated layout, widgets, and customization panel behind HNT Nova flags.
Marco has fixed a couple of issues with the places databases to try and improve stability. This should help with avoiding users losing bookmarks or favicons.
Work continues on the new separate search bar to improve the functionality, e.g. allowing middle click to perform a search in a new tab, avoiding performing a search when adding a search engine.
Work also continues on the new Nova layouts.
Smart Window
uplifted 10 bugs to 150.0.1 dot release addressing initial user feedback from diary study and Connect
The error pages shown when a server sends back an invalid response header or an unsupported content encoding now display accurate, context-specific messages. The invalid response header page also gained a helpful list of next steps. – 2027209
In progress: The error page illustrations are being replaced with new artwork, and the system now supports per-illustration size configuration, giving each image the ability to define its own appropriate dimensions. – 2031837
WebGL exposes the details of your graphics hardware (specifically, the string that describes the rendering engine) in 2 ways. There are three levels of protection that browsers have taken to protect this data.
gl.getParameter(gl.VENDOR) and gl.getParameter(gl.RENDERER) - these are the 'simple' names. At some point in the past, someone argued that it wasn't enough information, and therefore we have a second API
let ext = gl.getExtension('WEBGL_debug_renderer_info'); and then gl.getParameter(ext.UNMASKED_VENDOR_WEBGL) and gl.getParameter(ext.UNMASKED_RENDERER_WEBGL)
The unmasked values are intended to be the more detailed ones, so always make sure you're comparing apples to apples. Another axis is that WebGL can render with Hardware or Software. This isn't a guarentee which one you'll get, but you can hint towards one or the other and the browser may or may not respect it. Here are your values:
Alright, now let's talk about what browsers do about it. There's no point in talking about Vendor, Renderer, and Unmasked Vendor - they don't really show as much detailed info, it's all about Unmasked Renderer. There are three levels:
Give a constant value. (Or don't return anything at all.)
'Round' the values into buckets
Give the exact value back
Safari and Tor Browser give constant values.
Firefox 'rounds'.
Chrome (and Brave, and I assume all-ish other Chrome-based browsers) give the exact value.
Firefox actually is purusing constant values, this week. I wrote this document for our QA team to test it. (You can get a sense of the internal sausage making it takes to launch a privacy feature from it.) I don't know if you can see the dates but I made it May 20th. The problem is this - websites use this data legitimately to adjust behavior so that users get the best experience possible. I found one example where they detect a buggy graphics stack; and a couple of examples where they adjust rendering so things are more performant for users with lower end machines - a problem Apple has less to worry about because they only support certain machine models!
A common response to this seems to be ambivalence, and I would suggest that is a bit elitist. Yes, if you're caring about the details reveal by a particular Web API you probably have a computer where you don't need to worry, but making the web work well for everyone is important for equitable access to improving everyone's human condition.
We have been bucketing WebGL Renderer since 2021. While many of our (supported, on-by-default) fingerprinting protections are part of Enhanced Tracking Protection - rolling out first in PBM/ETP Strict before making it to ETP Standard/Normal Browsing Mode - the bucketing is on by default, for everyone, and is not disabled if ETP is disabled.
How much of a difference does it make? A lot! Here is the distribution of the raw values. 83,705 distinct values.
Compare that to the bucketed data. 131 distinct values.
Now this data is from Firefox, so I cant say conclusively what the distribution of data is in other browsers, but... yeah. To claim Chrome (of all browsers!) is doing this better than us is pure FUD. We're making a big impact in how fingerprintable you are today and we're trying to improve it even further.
Structure-aware fuzzing can better exercise the system under test (SUT) by
crafting inputs in the format expected by the SUT, rather than throwing
pseudorandom bytes against it. That is, it avoids “shallow” inputs that the SUT
will reject early (for example, syntactically invalid source text when fuzzing a
programming language’s compiler) and only produces inputs that go “deep” into
the SUT (e.g. programs that type-check and exercise the mid-end optimizer and
backend code generator). The Rust fuzzing ecosystem is largely built around
cargo-fuzz and the libfuzzer-sys crate, which provides two methods for
structure-aware fuzzing:
Generating structured inputs from scratch with the arbitrary crate
Mutating existing inputs from the fuzzer’s corpus in a structure-aware
manner, thereby producing new structured inputs, via the
fuzz_mutator! hook
While the two methods are not technically mutually exclusive, combining the two
can be difficult and engineering resources are finite. So:
If we are only implementing one approach, is generation or mutation better?
To help answer this question, I implemented structure-aware generation and
mutation of guaranteed-valid WebAssembly (Wasm) instruction sequences. This
task is small enough to be easily understandable but large enough and real
enough to (hopefully) be representative and applicable to other domains, or, at
the very least, interesting.1 To evaluate their effectiveness, I
used Wasmtime as the SUT, libfuzzer-sys as the fuzzing engine driving
everything, and then compared code coverage over time when using mutation-based
fuzzing versus generation-based fuzzing.
Additionally, there are many ways we can generate pseudorandom WebAssembly
instruction sequences. In this experiment, I’ve evaluated three methods:
Unconstrained instruction sequence generation followed by a fixup pass to
ensure validity
Generating valid instructions in a forwards, bottom-up
manner (from operands to operators)
Generating valid instructions in a backwards, top-down manner (from operators
to operands)
In contrast, while there are surely many ways to mutate a given WebAssembly
instruction sequence into a new, valid instruction sequence, I’ve only
implemented one method: perform an arbitrary instruction insertion, deletion, or
replacement, producing a new but probably-invalid instruction sequence, and then
run the same fixup pass mentioned previously to ensure validity. This is the
direct mutation-based equivalent of the first generation-based method.
Before continuing further, I want to disclose that I am the author of
wasm-smith and mutatis, and a maintainer of Wasmtime, arbitrary,
libfuzzer-sys, and cargo-fuzz. That is, while I am familiar with Wasm,
fuzzing, fuzzing Wasm, and both the arbitrary and mutatis crates, I may also
be propagating my own biases into these implementations.
Background
Generation-Based and Mutation-Based Fuzzing
A generation-based fuzzer uses a generator to create a pseudo-random test
cases from scratch, feeds these into the system under test, and reports any
failures to the user:
fngeneration_based_fuzzing<T>(// A test-case generator.generator:implFn()->T,// A function to run the system under test with a// generated test case, returning a result that// describes whether the run was successful or// not.run_system_under_test:implFn(&T)->FuzzResult,){loop{// Generate an input.letinput=generator();// Run the input through the system under test.letresult=run_system_under_test(&input);// If the system crashed, panicked, failed an// assertion, violated an invariant, or etc...// then report that to the user.ifletErr(failure)=result{report_to_user(&input,failure);}}}
On the other hand, mutation-based fuzzers are given an initial corpus of inputs
and create new inputs by mutating existing corpus members. They run each new
input through the SUT, report failures the same as before, and if the new input
was “interesting” (for example, exercised new code paths in the SUT that weren’t
previously covered in any other input’s execution) then the new input is added
into the corpus for use in future test iterations:
fnmutation_based_fuzzing<T>(// A corpus of test cases.corpus:&mutCorpus<T>,// A function to pseudo-randomly mutate an existing// input into a new input.mutate:implFn(&T)->T,// A function to run an input in the system under// test, returning a result that describes whether// the run was successful or not.run_system_under_test:implFn(&T)->FuzzResult,){loop{// Choose an old test case from the corpus.letold_input=corpus.choose_one();// Pseudo-randomly mutate that old test case,// creating a new one.letinput=mutate(old_input);// Run the input through the system under test.letresult=run_system_under_test(&input);// If the system crashed, panicked, failed an// assertion, violated an invariant, or etc...// then report that to the user.ifletErr(failure)=result{report_to_user(&input,failure);}// If the input was interesting, for example if// it executed previously-unknown code paths,// then add it into the corpus for use in a// future iteration.ifresult.input_was_interesting(){corpus.insert(input);}}}
The two approaches are not mutually exclusive and hybrid generation- and
mutation-based fuzzers exist.
Structure-unaware fuzzing will generate pseudorandom byte sequences and pass
them directly to the SUT. If the SUT expects some sort of structured input,
e.g. the source text for a programming language, it is likely that these byte
sequences are invalid and will be rejected early by the SUT’s frontend. For
example, when fuzzing a compiler, the input is rejected as syntactically invalid
by the parser or rejected as semantically invalid by the type checker. This can
be useful when hardening a tokenizer, parser, or type checker, but is less
useful when hunting for misoptimization in the mid-end or bad instruction
encoding in the backend because the inputs are unlikely to make it that far
through the compiler’s pipeline.
Structure-aware fuzzing will produce inputs that match the SUT’s expected
input format. Returning to the compiler-fuzzing example, structure-aware fuzzing
lets us generate valid programs for the compiler, so we can exercise more of the
mid-end and backend, rather than just the frontend.
Structure-aware fuzzing is often generation-based: for example using
grammar-based fuzzing to generate pseudorandom strings from a given language
grammar or language-specific tools like csmith and wasm-smith that
generate C and WebAssembly programs respectively. But structure-aware fuzzing
can also be mutation-based: libFuzzer’s custom mutator
example
implements a structure-aware mutator for zlib-compressed strings, where the raw
input is decompressed, the decompressed data is mutated, and then the mutated
data is recompressed to provide the new raw input. The mutator is aware of the
SUT’s zlib-compressed input structure.
The arbitrary crate helps Rust developers write custom structure-aware
generators for fuzzing. It provides building blocks and abstractions for
translating a raw byte sequence (usually from a fuzzing engine) into a
structured type, effectively interpreting the raw bytes as a “DNA string” or set
of predetermined choices for its decision tree. The library also provides a
derive(Arbitrary) macro to automatically implement its functionality for a
given type.
Because arbitrary is effectively implemented by combining decision trees, it
is extremely easy to create imbalanced trees and unintentionally bias the
distribution of generated test cases.
The mutatis Crate
The mutatis crate is, at a high-level, performing the same role for
authoring structure-aware mutators that arbitrary plays for generators. That
is, it provides Rust developers with abstractions and combinators for creating
custom structure-aware mutators. It also provides a derive(Mutate) macro to
automatically implement its functionality for a given type.
mutatis is designed to resist bias via a two-phase design: first, it
enumerates all of the candidate mutations that could be applied to a test case,
and only afterwards chooses a particular random mutation from the candidate set
to actually apply.
WebAssembly
WebAssembly is a virtual instruction set designed to be safe, portable, and
fast. It is a stack machine where an instruction’s operands are popped off a
stack during execution and results pushed. It has sandboxed linear memories,
global variables, and local variables (the latter two effectively being two
kinds of virtual registers). The following instruction sequence computes a * 3
and stores the result into memory at address p:
The range of all three generators and the mutator is the same universe of
WebAssembly programs. They are all implemented on top of the same Module and
Inst types, and, given enough time, none is capable of producing an
instruction sequence that another cannot. This helps ensure that our comparison
is apples-to-apples. However, due to their different implementation techniques,
they do produce different distributions of WebAssembly programs within that
universe, and produce test cases at different speeds from one another, which
ultimately affects how efficiently they exercise the SUT.
All of the generators are built on top of the arbitrary crate. The mutator
is built on top of the mutatis crate.
The Module type is our structured fuzzing input. It describes a WebAssembly
module containing a variable number of linear memories, a variable number and
type of globals, and one function with a variable number and type of parameters
and results and a variable instruction sequence:
/// A WebAssembly module of the shape:////// (module/// (memory ...)/// (memory ...)/// ...////// (global ...)/// (global ...)/// ...////// (func (export "run") (param ...) (result ...)/// .../// )/// )pubstructModule{num_memories:u32,globals:Vec<Global>,param_types:Vec<ValType>,result_types:Vec<ValType>,instructions:Vec<Inst>,}
The Inst type is an enum of all the WebAssembly instructions the
implementations support, which is all of the integer, float, SIMD, memory,
local, and global instructions. Control-flow, threading, table, and GC
instructions are not supported. Here is a subset of Inst’s definition:
There is an Inst::operand_types method that returns the types that the
instruction pops from the stack, and an Inst::result_type method that returns
the type of the value that the instruction pushes onto the stack, if
any. Finally, the Module::to_wasm_binary method encodes the module into
WebAssembly’s binary format, so it can be fed into Wasmtime. These methods are
used, directly or indirectly, in every generator and mutator implementation.
arb
The arb generator leverages derive(arbitrary::Arbitrary) on our structured
input types to generate a pseudorandom instance of Module, unconstrained by
validity. The module’s instruction sequence is almost certainly not valid at
this point: it likely is missing operands for instructions, producing more
results than the function’s signature describes, producing results of types that
don’t match the function signature, accessing globals and locals that don’t
exist, etc… Having produced an instance of Module, it next calls the
Module::fixup method to mutate the Module so that it is valid.
The fixup method works by abstractly interpreting the instruction sequence to
track the types of each value on the stack at every program point. Whenever an
instruction’s operand types don’t match the types on top of the stack, it
generates dummy values of the correct type. When the instructions produce more
values than the function’s signature proscribes, it emits drop instructions.
implModule{pubfnfixup(&mutself,mutmake_value:implFnMut()->i64){// ...// The fixed-up instructions.letmutfixed=Vec::with_capacity(self.instructions.len(),);// The types on the stack at any given program// point. Similar to the Wasm spec's appendix's// validation algorithm.letmutstack:Vec<ValType>=Vec::new();forinstinmem::take(&mutself.instructions){// Special-case `drop` because it is// polymorphic.ifmatches!(inst,Inst::Drop){ifstack.is_empty(){fixed.push(ValType::I32.make_const(make_value()),);}else{stack.pop();}fixed.push(inst);continue;}// First clamp entity indices to valid// ranges.letSome(inst)=self.fixup_inst_immediates(&mutmake_value,has_mutable_global,inst,)else{continue};// Then make sure that the stack has// operands of the correct types for this// instruction.self.fixup_stack(&mutmake_value,&mutfixed,&mutstack,&inst,);// Finally, apply the effects to the stack.letlen_operands=inst.operand_types(&self.globals,).len();stack.truncate(stack.len()-len_operands);stack.extend(inst.result_type(&self.param_types,&self.globals,));fixed.push(inst);}// ...self.instructions=fixed;}fnfixup_stack(&mutself,mutmake_value:implFnMut()->i64,fixed:&mutVec<Inst>,stack:&mutVec<ValType>,inst:&Inst,){letneeded=inst.operand_types(&self.globals);letn=needed.len();ifstack.len()>=n{if(0..n).all(|i|{stack[stack.len()-n+i]==needed[i]}){// All needed operands are on the stack.return;}}else{ifstack.iter().enumerate().all(|(i,ty)|{*ty==needed[i]}){// A prefix of needed operands are on the// stack; make constants for the tail that// are missing.fortyin&needed[stack.len()..]{fixed.push(ty.make_const(make_value()));stack.push(*ty);}return;}}// Otherwise, just make constants for all the// needed operands.fortyinneeded{fixed.push(ty.make_const(make_value()));stack.push(*ty);}}// ...}
The fixup method also makes sure that for all instructions that have an
immediate referencing some entity, the referenced entity is valid. For example,
for a local.get $l instruction, it ensures that local $l actually exists or
else rewrites the local to one that does exist.
After calling fixup, the arb generator invokes Module::to_wasm_binary to
get the encoded Wasm program.
bottom_up
The bottom_up generator also uses abstract interpretation to track the types
of values on the stack. It generates instructions in forwards order, from
operands to operators. It begins with an empty stack, filters candidate
instructions down to just those that would be valid given the types currently on
the stack, randomly chooses one, updates the stack types accordingly, and
repeats the process. This is the same approach that wasm-smith uses. After
generating instructions this way, it then makes sure that the final types on the
stack match the function signature’s results, similar to the end of fixup.
implModule{pubfnbottom_up(u:&mutUnstructured<'_>)->Result<Self>{// ...letmax_insts=u.int_in_range(1..=MAX_INSTS)?;letmutinstructions=Vec::new();letmutstack:Vec<ValType>=Vec::new();for_in0..max_insts{ifstack==result_types&&u.ratio(3,4)?{break;}// Choose a random instruction whose operand// types match those currently on the stack.letinst=choose_inst_bottom_up(u,&stack,¶m_types,&globals,num_memories,)?;// Apply this instruction's effects to the// stack.apply_inst(&inst,&mutstack,¶m_types,&globals,);instructions.push(inst);}// ...Ok(Module{param_types,result_types,globals,num_memories,instructions,})}}fnchoose_inst_bottom_up(u:&mutUnstructured<'_>,stack:&[ValType],param_types:&[ValType],globals:&[Global],num_memories:u32,)->Result<Inst>{// Build up all the valid candidate instructions.letmutcandidates:Vec<Inst>=Vec::new();// Producers are always okay: [] -> [t]candidates.push(Inst::I32Const(0));candidates.push(Inst::I64Const(0));candidates.push(Inst::F32Const(0.0));candidates.push(Inst::F64Const(0.0));candidates.push(Inst::V128Const(0));if!param_types.is_empty(){candidates.push(Inst::LocalGet(0));}// ...lettop=stack.last().copied();letsecond=stack.get(stack.len()-2).copied();// Drop needs 1 operand of any type: [t] -> []iftop.is_some(){candidates.push(Inst::Drop);}// i32 unary: [i32] -> [...]iftop==Some(I32){candidates.push(Inst::I32Clz);candidates.push(Inst::I32Ctz);candidates.push(Inst::I32Popcnt);// ...}// i64 unary: [i64] -> [...]iftop==Some(I64){candidates.push(Inst::I64Clz);candidates.push(Inst::I64Ctz);candidates.push(Inst::I64Popcnt);// ...}// ...// i32 binary: [i32 i32] -> [...]iftop==Some(I32)&&second==Some(I32){candidates.push(Inst::I32Add);candidates.push(Inst::I32Sub);candidates.push(Inst::I32Mul);// ...}// i64 binary: [i64 i64] -> [...]iftop==Some(I64)&&second==Some(I64){candidates.push(Inst::I64Add);candidates.push(Inst::I64Sub);candidates.push(Inst::I64Mul);// ...}// ...// Choose a random instruction from the// candidates.letmutinst=*u.choose(&candidates)?;// If the instruction has immediates, generate// them here, as they were hard-coded during// candidate selection.match&mutinst{Inst::I32Const(v)=>*v=u.arbitrary()?,Inst::I64Const(v)=>*v=u.arbitrary()?,// ...Inst::GlobalGet(g)=>{*g=u.int_in_range(0..=(globals.len()asu32-1))?;}// ...Inst::I32Load(m)|Inst::I64Load(m)|Inst::F32Load(m)|Inst::F64Load(m)|Inst::V128Load(m)|Inst::I32Store(m)|Inst::I64Store(m)|Inst::F32Store(m)|Inst::F64Store(m)|Inst::V128Store(m)|Inst::MemorySize(m)|Inst::MemoryGrow(m)=>{*m=u.int_in_range(0..=(num_memories-1))?;}_=>{}}Ok(inst)}
After constructing a Module via bottom_up, we don’t need to call fixup
because the module is already valid by construction, so all that’s left is
invoking Module::to_wasm_binary to get the encoded Wasm program.
top_down
The top_down generator is very similar to bottom_up, but instead of
generating instructions forwards, from operands to operators, it generates them
backwards, from operators to operands. Instead of maintaining a stack of the
types of values generated thus far by the instruction sequence prefix, it
maintains a stack of the types of values expected by the instruction sequence
suffix. This is the approach that rgfuzz by Park, Kim, and Yun
takes.2
implModule{pubfntop_down(u:&mutUnstructured<'_>,)->Result<Self>{// ...letmax_insts=u.int_in_range(1..=MAX_INSTS)?;letmutinstructions=Vec::new();letmutneeded=result_types.clone();for_in0..max_insts{ifneeded.is_empty()&&u.ratio(3,4)?{break;}// Choose a random instruction in a// top-down manner.letinst=choose_inst_top_down(u,needed.last().copied(),¶m_types,&globals,num_memories,)?;// Pop the result type from `needed`, if// any, as it's been satisfied.letty=inst.result_type(¶m_types,&globals,);ifty==needed.last().copied(){needed.pop();}// Add operand type demands.match&inst{Inst::Drop=>{// `drop` is polymorphic; choose// a random type.needed.push(u.arbitrary()?);}Inst::GlobalSet(g)=>{needed.push(globals[*gasusize].ty);}_=>{needed.extend_from_slice(inst.operand_types(&globals),);}}instructions.push(inst);}// Fill remaining needed types with// constants.fortyinneeded.iter().rev(){instructions.push(ty.make_const(u.arbitrary()?),);}// Instructions were generated backwards, so// reverse.instructions.reverse();Ok(Module{param_types,result_types,globals,num_memories,instructions:prefix,})}}fnchoose_inst_top_down(u:&mutUnstructured<'_>,target_ty:Option<ValType>,param_types:&[ValType],globals:&[Global],num_memories:u32,)->Result<Inst>{letmutcandidates:Vec<Inst>=Vec::new();matchtarget_ty{Some(I32)=>{candidates.push(Inst::I32Const(0));candidates.push(Inst::I32Add);candidates.push(Inst::I32Sub);candidates.push(Inst::I32Mul);// ...}Some(I64)=>{candidates.push(Inst::I64Const(0));candidates.push(Inst::I64Add);candidates.push(Inst::I64Sub);candidates.push(Inst::I64Mul);// ...}Some(F32)=>{candidates.push(Inst::F32Const(0.0));candidates.push(Inst::F32Add);candidates.push(Inst::F32Sub);candidates.push(Inst::F32Mul);// ...}// ...None=>{// Nothing needed. `drop`, `global.set`, and// stores add demand.candidates.push(Inst::Drop);ifglobals.iter().any(|g|g.mutable){candidates.push(Inst::GlobalSet(0));}ifnum_memories>0{candidates.push(Inst::I32Store(0));// ...}}}letmutinst=*u.choose(&candidates)?;// If the instruction has immediates, generate// them here, as they were hard-coded during// candidate selection. Same as `bottom_up`.match&mutinst{// ...}Ok(inst)}
Similar to bottom_up, after we’ve constructed a Module via top_down, we
don’t need to call fixup because the module is already valid by construction.
All that’s left is invoking Module::to_wasm_binary to get the encoded Wasm
program.
mutate
mutate is, as the name implies, a mutator rather than a generator. It is the
direct equivalent of the arb generator, but for mutation: it uses
derive(mutatis::Mutate) on Module and Inst to automatically generate
custom mutators for these types, rather than authoring them by hand. After
producing a new Module by mutating an old Module, that new Module probably
represents an invalid Wasm program, in the same way that
derive(arbitrary::Arbitrary) produces Modules that are probably invalid. And
mutate also uses the same approach that arb does to resolve this problem:
the fixup method.
But first, a mutator-specific wrinkle is that fuzz_mutator! gives us a mutable
byte slice to mutate, not a Module. We address this gap by deriving the
serde crate’s Serialize and Deserialize traits on Module and Inst,
deserializing a Module from the mutable byte slice, mutating that deserialized
Module with mutatis, and then reserializing it back into the mutable byte
slice. We use the postcard crate here, but could just as easily use
bincode, JSON, or protobuf.
uselibfuzzer_sys::{fuzz_mutator,fuzz_target,fuzzer_mutate};fuzz_mutator!(|data:&mut[u8],size:usize,max_size:usize,seed:u32,|{// With probability of about 1/8, use default// mutator.ifseed.count_ones()%8==0{returnfuzzer_mutate(data,size,max_size);}// Try to decode using postcard; fallback to// default input on failure.letmutmodule:Module=postcard::from_bytes(&data[..size]).ok().unwrap_or_default();// Mutate with `mutatis`.letmutsession=mutatis::Session::new().seed(seed.into()).shrink(max_size<size);ifsession.mutate(&mutmodule).is_ok(){ifletOk(encoded)=postcard::to_slice(&module,data,){returnencoded.len();}}// Fallback to the default libfuzzer mutator if// serialization or mutation fails because, for// example, `data` doesn't have enough capacity.fuzzer_mutate(data,size,max_size)});
Finally, the fuzz target itself deserializes the Module from the raw bytes,
calls fixup, encodes it to a Wasm binary via Module::to_wasm_binary, and
then passes that into Wasmtime.
We pair each of our generators and mutator with libfuzzer-sys and feed the
resulting test cases into Wasmtime. All fuzzers start with an empty corpus.
The most important metric for a fuzzer is its bug-finding ability, but that can
be difficult to measure directly. For example, Wasmtime is actively fuzzed 24/7
with more-complete fuzzers than those implemented here, so, as expected, I have
not found any bugs via these benchmarks. Therefore, instead of reporting a
found-bugs count, the benchmark harness reports two alternative metrics:
Coverage over time: Coverage is the cumulative code paths exercised by
the fuzzer. A fuzzer cannot find bugs in code paths it does not cover. This
is the most important metric reported.
Executions over time: An execution is one iteration of the fuzzing
loop. This is basically measuring how fast the fuzzer can produce test
cases. All else being equal, more executions is better, but all else is
rarely equal. It is easy to generate poor test cases very quickly: just
return an empty sequence of Wasm instructions every time. Unfortunately, that
exclusively leads to useless executions. Therefore, this metric is really
only useful when comparing two implementations of the same algorithm, and
I’ve omitted its results in the next section.
Additionally, I report results for both 24 hours of fuzzing and 5 minutes of
fuzzing. The expected behavior of long-term fuzzing, e.g. 24/7 fuzzing in
OSS-Fuzz, can be extrapolated from the 24-hour results. The 5-minute results
show the expected behavior of short-term fuzzing, e.g. when using
mutatis::check or arbtest.
Discussion of short-term fuzzing is somewhat rare, so I feel its motivation
deserves explanation. I find short-term fuzzing useful in the following
scenarios, for example:
Running a quick fuzzing session locally, to catch bugs that avoid detection in
the traditional unit- and integration-test suites, before opening a pull
request.
Running some quick fuzzing in CI before allowing a pull request to merge, for
similar reasons.
That is, short-term fuzzing is useful for the same reasons and in the same
scenarios as property-based testing.3
arb has 1.00 ± 0.00 times more coverage than bottom_up (p = 0.01)
mutate has 1.01 ± 0.00 times more coverage than arb (p = 0.00)
top_down has 1.00 ± 0.00 times more coverage than arb (p = 0.00)
mutate has 1.02 ± 0.00 times more coverage than bottom_up (p = 0.00)
top_down has 1.01 ± 0.00 times more coverage than bottom_up (p = 0.00)
mutate has 1.01 ± 0.00 times more coverage than top_down (p = 0.00)
5 Minutes of Fuzzing
bottom_up has 1.01 ± 0.01 times more coverage than arb (p = 0.04)
mutate has 1.47 ± 0.02 times more coverage than arb (p = 0.00)
top_down has 1.06 ± 0.02 times more coverage than arb (p = 0.00)
mutate has 1.45 ± 0.01 times more coverage than bottom_up (p = 0.00)
top_down has 1.05 ± 0.02 times more coverage than bottom_up (p = 0.00)
mutate has 1.38 ± 0.02 times more coverage than top_down (p = 0.00)
Conclusion
The mutate fuzzer performs best. It vastly outperforms all the others at 5
minutes of fuzzing (36-49% more coverage), and while the rest narrow that gap
after 24 hours of fuzzing, mutate maintains its lead (1-2% more coverage).
The comparison between arb and mutate is as apples-to-apples of a comparison
as it gets between idiomatic test-case generation and mutation in Rust:
derive(Arbitrary) and derive(Mutate). They use the same fixup method to
ensure that the resulting Wasm instructions are valid. The fuzzer built with
mutatis and test-case mutation provides better coverage over time than the
fuzzer built with arbitrary and test-case generation. When writing
structure-aware fuzzers, I used to reach for arbitrary; in the future, I
will reach for mutatis instead.
The top_down fuzzer performs second-best, and is best of the generation-based
fuzzers. This aligns with results from the rgfuzz paper, which found that
top-down Wasm instruction generation resulted in better instruction diversity
than bottom-up generation. This result is intuitive, they point out, because
Wasm instructions tend to have more operands than results, which means that more
candidates are filtered out from consideration when generating instructions in
forward order from operands to results (bottom-up) than when generating them in
backward order from results to operands (top-down).
Subjectively, none of the approaches feel significantly more-complicated nor
easier to implement than the others. All approaches require a stack of types,
representing the generated Wasm’s operand stack, at some point in their
implementation. Some require it during instruction generation (top_down and
bottom_up) while others require it during fixup (mutate and arb). Adding
support for new Wasm instructions is roughly the same in all of them: add a new
variant to enum Inst and define its operand and result types. top_down and
bottom_up additionally require adding a line for the new instruction in their
choose_inst_{top_down,bottom_up} functions, but this could be avoided with
some targeted macro_rules! sugar.
The fixup method fixes instructions in a forwards order; as future work, it
would be interesting to implement a backwards_fixup method that fixes
instructions in a backwards order and see if mutate and backwards_fixup
outperforms the current mutate and forwards fixup the same way that
backwards generation (top_down) outperforms forwards generation
(bottom_up).
fixup makes an attempt to reuse stack operands when it can, rather than
synthesize dummy constants or drop already-computed values, but the attempt is
somewhat half-hearted. Dropping operands introduces dead code, which is not very
interesting for exercising deep into the compiler pipeline. Dummy constants are
not that interesting either. Therefore, another potential line of follow-up work
would be to investigate ways to maximize operand reuse and minimize drops and
dummy constants inserted while ensuring validity. That could include storing
values to memory or globals instead of droping them when possible. It could
even include liberating ourselves from the stack-focused paradigm we’ve had thus
far.
WebAssembly is a stack-based language and so it is natural that our approaches
have focused on producing stack-y code. But, in practice, optimizing WebAssembly
compilers like Wasmtime’s use a static single-assignment intermediate
representation, and erase the operand stack early in their compilation
pipelines. Therefore, from these compilers’ point of view, the following two
WebAssembly snippets are identical:
;; `x = a + (b * c)` in a "stack-y" encoding and;; without temporary locals.local.get$alocal.get$blocal.get$ci32.muli32.addlocal.set$x;; `x = a + (b * c)` in a "non-stack-y" encoding;; that uses temporary locals for every operation.;;;; Equivalent of;;;; temp0 = b * c;; temp1 = a + temp0;; x = temp1local.get$blocal.get$ci32.mullocal.set$temp0local.get$alocal.get$temp0i32.addlocal.set$temp1local.get$temp1local.set$x
Producing code that uses many temporaries in this manner might be easier than
code that doesn’t, but, more importantly, it may enable better reuse of
already-computed subexpressions, emit less dead code, and ultimately produce
more interesting data-flow graphs that better exercise the deep innards of the
compiler.
A final vein of interesting follow-up work to mine would be comparing
arbitrary-based generators and mutatis-based mutators for structured inputs
that are not programming languages and when the SUT we are fuzzing is not a
compiler. Do we see these same results when, for example, producing PNG images
to fuzz an image-transformation library?
WebAssembly’s stack-based instructions encode an expression tree
— local.get $a; local.get $b; local.get $c; i32.add; i32.mul is
isomorphic to a * (b + c) — so the experiment should be relevant and
applicable to any other generator or mutator for a programming language with
expressions, even if it might not appear so at first glance. ↩
Ignoring its rule-guided bit, which is orthogonal and could be
applied to bottom_up as well. ↩
Structure-aware fuzzing and property-based testing are basically the
same:
convergent evolution from different communities. ↩
I’ve spent a lot of time at Mozilla working on session history, the machinery that keeps track of where you’ve been so the back and forward buttons do something sensible. It’s one of those parts of the browser that sounds simple from the outside and turns out to be anything but. Once you add iframes, nested iframes, and the subtle rules about when a navigation creates a new entry versus replacing the current one, the state you’re reasoning about gets large and hard to hold in your head.
For years my main tool for understanding that state was reading code and printing things to a log. That works, but it’s slow, and it never quite shows you the shape of the thing. So I built a way to see it: a new DevTools panel in Firefox Nightly called Session History Diagrams.
Enabling it
The panel is available in Firefox today, behind a pref. It’s been there in some form since Firefox 150, growing more stable with each release. To turn it on, set devtools.application.sessionHistory.enabled to true in about:config, then reload DevTools. The new panel lives under the Application tab, next to Service Workers and Manifest, and it draws the browser’s session history as a diagram that updates as you navigate.
Since Firefox 153 it also works over remote debugging. Connect to a device from about:debugging and you can watch the session history of a page running on Android, the same as you would on the desktop.
Jake diagrams
I didn’t invent the idea of drawing this. The HTML spec already has a notation for it, called a Jake diagram after Jake Archibald, and that’s where I started. It’s a tabular notation where columns represent steps in session history, and rows represent navigables (the top-level browsing context plus any iframes). Background colors identify documents, a fresh color marking a new document loaded in that navigable, and the current step is shown in bold. It’s a genuinely useful way to capture multi-navigable interactions that are otherwise hard to describe in prose.
These diagrams don’t have to be drawn by hand. Domenic Denicola, one of the HTML spec editors, built a Jake diagram generator that turns a description of a navigation sequence into a rendered diagram. That’s where I first started playing with a more dynamic approach to the visualization. The thing I missed the most was being able to build a history up step by step rather than describe a finished sequence all at once. So I wrote rejake, a small tool that draws diagrams in the same style1, but lets you construct the history one step at a time.
But rejake, like the spec’s diagrams and Domenic’s generator before it, was stuck with a limitation the spec itself admits to, that they only work with a single level of nesting. That was exactly my problem. Real pages nest iframes inside iframes, and the bugs I was chasing usually lived down in that deeper nesting, precisely where the diagram stops being able to help. And however I drew them, I was still typing the history out by hand. It’s a short step from there to wanting the diagram to draw itself from the browser’s actual session history instead2.
Firefox Session History Diagrams
So the panel extends Jake diagrams to handle arbitrary nesting. Every column is a step in the session history. Every row is a frame, listed in pre-order from the frame tree: top-level document first, then its first iframe, then that iframe’s children, and so on. The current entry is highlighted in blue, and the diagram updates live as you navigate.
The recording above is an ordinary bit of browsing, a handful of pages visited one after another. The top row tracks the page you’re actually looking at, and the current position is the one in blue. The interesting part is everything underneath that top row.
Some of those pages didn’t just load a single document. They pulled in nested frames of their own, and the diagram stacks those below the page that owns them. None of that is visible in the address bar or anywhere in the page chrome, and the frames come and go as you move through the history. Normally you’d have no way of knowing they were ever there. Here you can read straight off the diagram which frames a given step carried, when each one entered, and when it dropped away again.
Who else might want this
I built this for myself, working on Gecko’s session history internals, where being able to watch the diagram change while reproducing a bug turns opaque state into something I can point at. But it turns out I’m not the only one who hits this wall. Plenty of people working elsewhere in Gecko, anywhere near navigation, end up reasoning about the same state, and now we all share one picture of it.
If you build single-page applications, or work with the History API or Navigation API, you’ve probably run into the same kind of confusion from the other side. A push where you expected a replace, a missing history entry, an iframe that accumulated entries unexpectedly. These are hard to reason about without seeing the state directly, and that’s exactly what the diagram gives you.
Session history isn’t a Firefox-specific problem either. Every engine implements the same part of the HTML spec, and Jake diagrams come from that shared spec. The panel only ever shows Firefox’s state, but the rules are the same everywhere, so if you work on another engine it can still be a useful reference for how one implementation behaves. It’s often the only practical way to surface an interoperability difference, which might be a bug in any of the engines, but stays hidden until you can actually see it.
Thanks
A big thanks to Nicolas Chevobbe, whose assistance was invaluable in getting the DevTools integration right. The work, including what’s still to come, is tracked in Bug 2015726. There’s a fair bit still on that list, like marking whether a step was a push or a replace, surfacing back/forward cache state, tying the diagram into the Network and Inspector panels, and more, all heading toward fuller DevTools support for Navigation and Session History.
Notes
Which, naturally, meant re-implementing the whole of Session History along the way. ↩
Getting nerd-sniped by Jan Jaeschke definitely contributed as well. ↩
Like many, docker and and compose have become my go-to tool to create software that can be conveniently deployed to production with a limited amount of headache. However, many tasks, and sometimes whole services, pertain only to the development side of the workflow, and need to stay there.
Moreover, some tasks, such as time-consuming provisioning tasks, are only on-demand one-offs. They shouldn’t run at all most of the time, but they should slot into the dependency graph correctly when needed.
We can start with a simple setup where our long-running main service depends on an init service to perform preliminary steps. This can be setup with depends_on the compose.yaml.
Perhaps we are lucky, and while it needs to run once, we don’t need it to run everytime (think: database setup).
Docker compose can use profiles to select when services are started. It will then only be started when this profile is selected. Services without explicit profile will always be started, but any service with one or more profile listed will only get started iff that profile is selected.
We can make the opt-init service part of the opt profile. We can also make the main service dependent on it, so it is started beforehand.
This works well enough when the opt profile is specified but… Oh no! If the profile is not specified, the dependency on the opt-init isn’t resolvable, and none of the stack can spin up with just docker compose up
And that’s really all there is to it: with the right profile, the optional dependency is started in the desired order, but its absence is otherwise transparently ignored. Both docker compose up and docker compose --profile opt work as desired.
Profiles afford us another useful trick: on-demand tasks not started by default. This can be handy for maintenance tasks (data cleanup, garbage collection, …) or test scripts (running test workload, sending message, …). Those are handy during development, but would not be necessary, or take a different form, in other deployments.
Conveniently, when explicitly running a service, it is not necessary to request a matching profile, keeping the command line lean: docker compose run say-hello.
So here we are. Compose profiles allow us to control which services get started, and mark some as conditional. This, coupled with the ability to mark some depends_on rules as not required is a good way to seamlessly prevent heavy or otherwise time consuming services from starting when not needed, while retaining proper dependency ordering when enabled.
For completeness, the full, final, compose.yaml looks as follow.
Servo 0.2.0 contains all of the changes we landed in April, which came out to yet another record 534 commits (March: 530).
For security fixes, see § Security.
crypto.subtle.supports() (@kkoyung, #43703) – Servo is the first major browser engine to support this!
cellPadding, cellSpacing, and align properties on HTMLTableElement (@mrobinson, #43903) – previously supported in HTML only
relatedTarget on ‘focus’ and ‘blur’ events (@mrobinson, #43926)
transferFromImageBitmap() on ImageBitmapRenderingContext (@Messi002, #43984)
Servo’s support for text in Chinese, Japanese, and Korean languages has improved, with correct wrapping in the layout engine (@SharanRP, #43744), and CJK fonts now enabled in servoshell’s browser UI on Windows, Linux, and FreeBSD (@yezhizhen, @CynthiaOketch, @nortti0, #44055, #44138, #44514).
Navigating to a JSON file as the top-level document now renders the JSON with an interactive pretty-printer (@webbeef, @TimvdLippe, #43702).
April was a big milestone for Servo, with some automated tests failing because they had hard-coded cookie expiry dates set to April 2016 plus ten years.
Surprise!
We’re still here.
Here’s to the next 100 years of Servo (@jdm, #44341).
CryptoKey now zeroes buffers containing key material after use (@kkoyung, #44597).
With only a few exceptions, you can only access DOM APIs in another document if that document is in the same origin.
But if that document is in the same site with a different port number, Servo currently allows these accesses even though it shouldn’t.
We’ve fixed some (but not all) of these incorrect accesses, specifically those that involve binding a Window or Location method in this document with a this from the other document (@yvt, @jdm, #28583).
We’ve fixed a bug where localStorage and sessionStorage were usable in sandboxed <iframe> and shared with every other sandboxed <iframe>, rather than throwing SecurityError (@Taym95, #44002).
We’ve fixed a bug where localStorage and sessionStorage were shared between all <iframe srcdoc> documents, rather than isolated using the origin of the containing document (@niyabits, #43988, #44038).
We’ve fixed a bug where IndexedDB was usable in sandboxed <iframe> and data: URL web workers (@Taym95, #44088).
We’ve fixed a bug where pages in some IP address origins can evict cookies from other IP address origins (@officialasishkumar, #44152).
Only evicting cookies was possible, not reading or writing them.
We’ve fixed an out-of-bounds memory read in texImage3D() on WebGL2RenderingContext (@simartin, #44270), and fixed some undefined behaviour in servoshell’s signal handler (@Narfinger, #43891).
IndexedDB now uses Servo’s new “client storage” system, which is based on the Storage Standard and will allow us to have a unified on-disk format and quota management for all web platform features that persistently store data (@gterzian, #44374, #43900).
We’ve also made key range queries more efficient (@arihant2math, #39009), landed improvements to IDBDatabase, IDBObjectStore, IDBCursor, IDBKeyRange, IDBRequest, and to the handling of transactions, keys, values, and exceptions (@Taym95, #44128, #43901, #44009, #43914, #44161, #44183, #44059, #44215, #42998, #43805).
We’ve made more progress on the IntersectionObserver API, under --pref dom_intersection_observer_enabled (@stevennovaryo, @jdm, #42204).
All of the features above are enabled in servoshell’s experimental mode.
Servo can now build a very basic accessibility tree for web contents, under --pref accessibility_enabled (@alice, @delan, @lukewarlow, #42338, #43558, #44437, #44438).
This includes text runs, plus nine other non-interactive accessibility roles (@alice, @delan, #44255).
We’ve also fixed a crash when reloading pages with accessibility enabled (@alice, #44473), and made accessibility tree updates more efficient (@alice, #44208).
servoshell for Android now has a revamped browser UI, including a new history view (@espy, #43795), the apk is 30% smaller (@jschwe, #44278, #44182), and we’ve fixed the black screen bug when closing settings or switching back from another app (@yezhizhen, #44327).
You can now close tabs on OpenHarmony too (@Narfinger, #42713).
As for servoshell on desktop platforms, we’ve fixed some focus- and IME-related bugs (@mrobinson, #43872, #43932), and on Windows, we now install a normal shortcut without the strange behaviour of an “advertised” shortcut (@yezhizhen, #44223).
For developers
When using the Inspector tab in the Firefox DevTools, the Rules panel now includes declarations in ‘@layer’ rules (@arabson99, #43912).
When using the Debugger tab, you can now use the Scopes panel to inspect local and global variables (@eerii, @atbrakhi, #43792, #43791), you can now debug web worker scripts (@atbrakhi, #43981), and we’ve started implementing blackboxing, aka the Ignore source button (@freyacodes, #44142).
We’ve also landed some initial support for the Style Editor tab (@rovertrack, #44517, #44462).
We’re working towards re-enabling our automated DevTools tests in CI, which should make the feature more reliable (@freyacodes, #44577), and we’ve landed a small build reproducibility fix too (@jschwe, #44459).
For developers of Servo itself, please note that the Cargo ‘release’ profile is no longer #[cfg(debug_assertions)] (@jschwe, @mrobinson, #44177).
If you’ve been using ‘release’ as a “faster ‘debug’ with assertions” build locally, consider switching to ‘checked-release’ or ‘medium’.
The pull request template has been updated (@mrobinson, #44135).
‘Testing’ and ‘Fixes’ should go at the bottom of the PR description, and ‘Testing’ is about automated tests, not how you tested the PR locally.
In the meantime, did you know that you can use Lix or Nix to build Servo on Linux with a lot less hassle, even if you’re not using NixOS?
For now at least, head to the NixOS page in the book to learn more.
We’ve also fixed a regression that made --debug-mozjs and MOZJS_FROM_SOURCE builds take much longer to complete on Linux when not using Nix (@jschwe, #44346).
We’ve fixed building Servo with the ‘jitspew’ feature in mozjs, allowing you to set IONFLAGS to enable JIT logging (@simonwuelker, #44010).
We’ve also fixed build issues on Windows and FreeBSD (@zhangxichang, @mrobinson, #44264, #44591).
Embedding API
With this second monthly release of the Servo library, we have some quick notes about API stability and semver compatibility:
Until we integrate semver analysis into our release process, each monthly release will have a breaking version number, while non-breaking version numbers may be used for LTS updates.
In general, dependencies of ‘servo’, like ‘servo-base’ and ‘servo-script’, do not use semver.
Any release may include breaking changes.
WebViewDelegate::play_gamepad_haptic_effect and stop_gamepad_haptic_effect have been removed (@mrobinson, #43895), but they have not worked since February 2026 – use GamepadDelegate instead
You can configure Servo to write all of its storage to a unique directory for that session by enabling Opts::temporary_storage (@janvarga, #44433).
Note that these unique directories currently persist after Servo exits, so it’s an isolation feature, not a privacy feature.
Tab navigation now works across <iframe> boundaries (@mrobinson, #44397), and Ctrl+Backspace (or ⌥⌫) now deletes a whole word in input fields (@mrobinson, #43940).
Tab characters are now rendered correctly in <pre> (and other elements with ‘white-space: pre’), with proper tab stops (@mrobinson, @SimonSapin, #44480).
Spaces are now rendered correctly in 2D <canvas>, instead of twice as wide as they should be (@mrobinson, #43899).
<a href> now correctly resolves the URL with the page encoding (@sabbCodes, #43822).
We’ve improved the default appearance of <input type=file> (@sabbCodes, #44496) and <textarea placeholder> (@mrobinson, #43770).
All keyboard events, mouse events, wheel events, and pointer events, other than ‘pointerenter’ and ‘pointerleave’, now bubble out of shadow roots (@simonwuelker, @webbeef, #43799, #44094).
‘error’ events on Window now report the correct filename (source in onerror) and lineno (@Gae24, #43632).
console.log() and friends now support printf-style formatting directives, although for now %c is ignored (@TG199, #43897).
file: URLs are now considered secure contexts, so they can now use features like crypto.subtle and crypto.randomUUID (@simonwuelker, #43989).
Servo makes its first TLS connection in each session 30–60 ms faster (@jschwe, #44242), and we’ve instrumented the Servo and servoshell startup processes to find more opportunities for optimisation (@jschwe, #44443, #44456).
Like most browser engines, Servo is a multi-threaded (and sometimes multi-process) system requiring a great deal of IPC messages to keep everything connected.
Two key components of this system are the constellation thread, which manages the engine as a whole, and the script threads (or web processes), which render the web pages.
Sending these messages can be expensive though, so to reduce unnecessary IPC traffic, we’ve landed an optimisation that allows script threads to selectively receive only the relevant messages from the constellation (@webbeef, #43124).
We’ve reduced the memory usage of each Attr, Text, and CharacterData node in the DOM by 16 bytes (@mrobinson, @Loirooriol, #44074), and fixed a memory leak when deleting <video controls> or <audio controls> (@Messi002, #43983).
Our about:memory page is more accurate now too, with new tracking of libc memory allocations on macOS, improved tracking of libc memory allocations on Linux (@jschwe, #44037), and more accurate tracking of PathBuf and types in tokio, http, data_url, and urlpattern (@Narfinger, #43858).
Less memory usage isn’t always better in browser engines though, because there are many kinds of caches and other optimisations we can do to make browsing the web faster, at the expense of increased memory usage.
For example, we can greatly speed up prototype checks for DOM objects by storing a number in each object that identifies the concrete type, at the expense of making each DOM object 64 bits larger (@webbeef, #44364).
Layout can now reuse fragments in later reflows, in many cases that involve block layout or ‘position: absolute’ (@mrobinson, @lukewarlow, @Loirooriol, #42904, #44231).
We’re also working on reusing shaping results in later reflows, and making inline layout more efficient (@mrobinson, #44370, #43974, #44436).
when shadow roots are deeply nested, or when calling attachShadow() removes elements from the flat tree (@yezhizhen, @mrobinson, #43888, #43930, #44259)
We fixed a crash in servoshell when pressing keys like Ctrl+2 or ⌘2 with not enough tabs open (@mrobinson, #44070).
DOM data structures (#[dom_struct]) can refer to one another, with the help of garbage collection.
But when DOM objects are being destroyed, those references can become invalid for a brief moment, depending on the order the GC finalizers run in.
This can be unsound if those references are accessed, which is a very easy mistake to make if the type has an impl Drop.
To help prevent that class of bug, we’re reworking our DOM types so that none of them have #[dom_struct] and impl Drop at the same time (@willypuzzle, #44119, #44501, #44513).
Thanks again for your generous support!
We are now receiving 7349 USD/month (+2.5% from March) in recurring donations.
This helps us cover the cost of our speedyCIandbenchmarkingservers, one of our latest Outreachy interns, and funding maintainer work that helps more people contribute to Servo.
Servo is also on thanks.dev, and already 33 GitHub users (−4 from March) that depend on Servo are sponsoring us there.
If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
We now have sponsorship tiers that allow you or your organisation to donate to the Servo project with public acknowlegement of your support.
If you’re interested in this kind of sponsorship, please contact us at join@servo.org.
This is a blog post about standards, their proliferation and the issues
that may arise.
My first involvement with standards was just as a reader. To
better understand complicated code or unexpected behavior in a protocol.
After a while, I also got involved and helped clarify certain things to ensure
implementations align on the same behavior in edge cases.
Eventually, I found myself co-editing a specification -
Subresource Integrity (SRI) which was published as
a W3C Recommendation in 2015. The core idea behind SRI is that you include
third-party JavaScript combined with a SHA2 digest of the expected file.
If the browser does not find the downloaded URL to match the expected digest,
the script will not execute. This allows using a fast CDN for JavaScript
without giving them full control over the scripts on your page - essentially
reducing the security risks.
The standard format for these digests is e.g.,
sha(size)-(base64 encoding of the digest).
While computing the hash digest is rather straightforward, base64 comes in two
encoding alphabets: First, a-zA-Z0-9/+ and secondly the url-safe variant
which uses a-zA-z0-9_-. The specification examples all used the former.
Only approximately ten years after publication, in 2025, we still found a bug.
As part of a compatibility report against Firefox not properly supporting a
website, we found that the core issue was actually with a different browser.
The other browser liberally accepted both types of encoding, which resulted in
websites expecting support for base64 and base64url interchangeably.
The page did not work in Firefox, because it did not accept all hashes a
website wanted the browser to check, revealing a minor security issue.
The real fix would have been that the standard clarifies that
the base64url variant is incorrect and the other browser engine changes
their behavior.
But due to (somewhat unrelated) issues around proliferation of standards, web
compatibility and the unfortunate market dominance of certain browsers, we
went the other road. To support existing web content, we changed the standard
to acknowledging that both types of encoding are considered valid
representations.
This example shows, that it can take multiple years for subtle differences to
appear. Interoperable specifications can establish a shared
understanding along a "happy path", but not necessarily in adversarial
settings. In addition, standards need to continuous maintenance and active
stakeholders who ensure that implementations remain interoperable and secure
over time.
From specification to standard
Originally, a specification is at first just a write-up, an idea how something
could be better:
How it should behave, how it works, what the data structures, the algorithms
and the interactions of them look like. Anyone can come up with a grammar,
a parser and a resulting data structure.
For a standard, this specification needs a shared agreement that is also
widely and consistently implemented. This will work best with iterative
co-design of the spec, the implementations and intense discussions of
corner cases.
Some may go further and use shared test suites.
This will lead to Interoperability (interop), but still
requires constant maintenance and observation of the ecosystem beyond
individual implementations. While interop is asymptotic and requires a shared
agreement over time, security demands understanding - a broader reach that
requires the inspection of limitations and subtle boundaries.
This deeper level of understanding is often missing when implementations
consider syntax "simple enough" without reading the spec. The base64 SRI example is just one example, but there are more:
Many people have written their own parsers for text-based
languages. You may have seen code that parses HTML with regular expressions.
Other great examples of "easily" parsed languages are maybe XML, JSON, or YAML.
But these implementations often make different assumptions, leading to subtle incompatibilities or even security flaws.
Parser Differentials
More practical, let's look at an issue with JSON, to demonstrate the impact of
handling input that is ostensibly simple.
Let's examine this JSON string and the resulting data structure:
{"test":0,"test":1}
When parsed into an object obj, what do you think will obj.test return?
Most JSON parsers are so liberal that they will happily consume two dictionary
keys with the same name "test". One implementation may simply assign obj.test
twice: First with 0 and then overwrite it with 1.
Another one might check for existing keys
and reject the second "test" key silently, keeping the first one.
The lack of rigor in the original description of JSON as a
"subset of JavaScript" was already acknowledged and raised as problematic
in the JSON RFC (which came much later in 2017).
But still to this day, many implementations allow input
with duplicate dictionary keys and show divergent behavior.
While the examples with SRI and JSON are relatively harmless, real
parser differential bugs were leading to code execution,
authentication bypasses and more1.
What do we learn from this?
Perfect interoperability is not created through a specification, it needs
constant maintenance. The ambiguity can only be removed through long-term
commitment and regular feedback from implementations and users.
The same is true for security: The SRI bug persisted for ten years and
nobody noticed how implementations disagreed and corner cases were overlooked.
They only aligned due to a real, user-facing issue.
But these examples are not a warning sign, they are scar tissue that shows how
the internet is made. Standards can only mature through vigilant maintenance.
The bug reports, the spec issues being filed, the shared test
cases, sometimes even the random forum complaints. All of these help to
remove ambiguity and allow internet standards to mature.
In the end, standards are not secure because they are written down. They are secure because people continue to question, understand, and maintain them.
The Rust team is happy to announce a new version of Rust, 1.96.0. Rust is a programming language empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, you can get 1.96.0 with:
If you'd like to help us out by testing future releases, you might consider updating locally to use the beta channel (rustup default beta) or the nightly channel (rustup default nightly). Please report any bugs you might come across!
What's in 1.96.0 stable
New Range* types
Many users expect Range and related core::ops types to be Copy, but this is not the case: they implement Iterator directly, and it is a footgun to implement both Iterator and Copy on the same type so this has been avoided. RFC3550 proposed a set of replacement range types that implement IntoIterator rather than Iterator, meaning they can also be Copy. The standard library portion of that RFC is now stable, introducing:
core::range::Range
core::range::RangeFrom
core::range::RangeInclusive
Associated iterators
A Rust version in the near future will also add core::range::RangeFull and core::range::RangeTo as re-exports from core::ops (these do not implement Iterator and already implement Copy), and core::range::legacy::* as the new home for the current ranges. Range syntax like 0..1 still produces the legacy types for now, but will be updated to core::range types in a future edition.
With these stabilizations, it is now possible to store slice accessors in Copy types without splitting start and end:
The new RangeInclusive also makes its fields public, unlike the legacy version which avoided exposing the exhausted iterator state. This isn't a concern with the new type since it must be converted to begin iteration.
Library authors should consider making use of impl RangeBounds in public API, which accepts both legacy and new range types. If a concrete type is needed, prefer using new ranges as this will eventually become the default.
Assert matching patterns
The new macros assert_matches! and debug_assert_matches! check that a value matches a given pattern, panicking with a Debug representation of the value otherwise. These are essentially the same as assert!(matches!(..)) and debug_assert!(matches!(..)), but the printed value improves the possibility of diagnosing the failure.
These new macros have not been added to the standard prelude, because they would collide with popular third-party crates that provide macros with the same name. Instead, they should be manually imported from core or std before use.
use core::assert_matches;/// [Random Number](https://xkcd.com/221/)fn get_random_number() -> u32 { // chosen by a fair dice roll. // guaranteed to be random. 4}fn main() { assert_matches!(get_random_number(), 1..=6);}
Changes to WebAssembly targets
WebAssembly targets no longer pass --allow-undefined to the linker which means that undefined symbols when linking are now a linker error instead of being converted to WebAssembly imports from the "env" module. This change prevents modules from linking unless all linking-related symbols are defined to catch bugs earlier and prevent accidental issues with symbol naming or similar.
Undefined linking-related symbols are often indicative of build-time related bugs or misconfiguration. If, however, the old behavior is intended then it can be re-enabled with RUSTFLAGS=-Clink-arg=--allow-undefined or by editing the source code and using #[link(wasm_import_module = "env")] on the block defining the symbol.
This change was previously announced on this blog, and now takes effect in Rust 1.96.
You felt it. The shift. That your role has fundamentally changed thanks to
LLMs. It first entered your subconscious when you realized how easily you can
now crank out PRs. You felt it more concretely (and less enthusiastically), as
a reviewer when you opened your laptop one morning and noticed your review
queue was double what it normally is thanks to everyone else cranking out PRs.
And you feel this pervasive, general sense of friction.
It’s difficult to pinpoint exactly where this friction is coming from.
Depending on the repository size and CI setup, it will be slightly different
for everyone. It might involve longer review times or slipping review
standards. You might be noticing more merge conflicts and merge related CI
failures. Perhaps there are more failures sneaking through to main or CI is
taking longer to give you results. You almost certainly feel the grind.
People are on edge, tired; developers are pulling in opposite directions.
Here’s what LLMs shifted. The bottleneck is no longer producing code. The
bottleneck is integrating it. The friction we’re feeling is a result of more
PRs, more ideas, more reviews, more disagreements all made possible thanks
to LLMs. In short, the problem can best be summarized by Figure 1:
But we’re living in a moment where many folks haven’t realized this yet, and
are still under the impression that their job is to produce code.
Disruptions to internet connectivity can occur in countless ways – from weather incidents, natural disasters and accidents to intentional interferences like cyberattacks and government-issued blackouts. Yet while some disruptions are unavoidable, deliberate shutdowns represent a fundamentally different and deeply concerning trend. They undermine the open, global nature of the internet and put the safety, security, and fundamental rights of millions at risk.
For over 25 years, Mozilla has worked to ensure that the internet remains a global public resource—open, accessible, and safe for all. This vision, grounded in the Mozilla Manifesto, holds that the internet must remain a shared, decentralized infrastructure that empowers individuals, supports civic participation, and enables economic opportunity. Internet shutdowns run counter to these principles by restricting access, concentrating control, and weakening the very foundations of the open web.
To help organizations study and document outages, Mozilla makes aggregated Firefox telemetry data available to help identify and understand connectivity disruptions. As 2026 progresses, this data continues to show significant outages affecting millions of people worldwide—many of them the result of deliberate restrictions.
As of late May, Iran’s internet blackout had been in place for over 80 days, making it the longest shutdown since the Arab Spring. Following an earlier shutdown amid nationwide protests in January 2026, Iranian authorities have restricted access to the internet since 28 February. This has meant that, for almost three months, millions of Iranians have been cut off from news, communication, work, education, and basic services. It also means that almost no independent information about the situation in Iran is leaving the country, making it almost impossible for humanitarian organizations to assess the situation on the ground. The shutdown has also had a massive impact on the Iranian economy, severely disrupting financial activity and blocking international transactions. Although Iran’s president has recently ordered an end to the shutdown, it is unclear how and when Iranians will be able to reconnect to the web.
When large numbers of Firefox users experience connection failures for any reason, this produces an anomaly in the recorded telemetry data. At the country or city level, this can provide a corroborative signal of whether an outage or intentional shutdown occurred. Our telemetry documents the magnitude of the latest outage in Iran. The graph below documents the effect of the outage in multiple ways, such as users’ country location, language and timezone.
Across the globe, governments are increasingly interfering with and limiting access to connectivity. Both the number of states limiting connectivity and the amount of internet shutdowns has been growing steadily. In 2025 alone, 313 shutdowns across 52 countries have been documented, a sad record. This is a stark indication that shutdowns and restrictions are no longer a rare emergency measure, but established levers of control.
While the triggers for shutdowns are varied, access to the internet continues to be blocked especially often in times of conflict and political unrest. Especially in the context of hostilities, political tensions or public health emergencies, access to connectivity is a basic humanitarian need.
Beyond their immediate human impact, blackouts also affect the internet itself. Local networks depend on each other to form the global internet, and local restrictions affect the resilience and reliability of the web at large. When governments deliberately disrupt connectivity, they do not only isolate populations; they also contribute to the fragmentation of the global internet, undermining trust, interoperability, and the stability of shared infrastructure. Over time, this erosion risks replacing a single, open web with a patchwork of disconnected or controlled networks.
Governments should foster the health of the internet, not erode it. Access to the internet is widely recognized as essential for enjoying human rights. It is an integral part of modern life, facilitating education, communication, collaboration, business and entertainment. Preserving the open web requires sustained commitment: resisting shutdowns, promoting transparency, and reinforcing the technical and governance frameworks that keep the internet global, interoperable, and accessible. The internet’s value—as a platform for opportunity, innovation, and human connection—depends on it remaining open to all.
With Jujutsu, I've been able to work in multiple workstreams more efficiently than before. This means that if I'm working on multiple things, there is a higher likelihood of something going stale while I wait for a review or touch multiple files.
Dealing with conflicts aren't so bad these days, however if I can automate the easy ones, why not?
This is the prompt I've been using with my agent whenever I have a list of changes that have conflicts and don't need me to participate actively on it.
Using the jj version control system, fix the conflicts that are in the changesets from `<start_rev>` to `<end_rev>`. Keep trying until there are no more "(conflict)" in the changesets between those two IDs.
The Rust Security Response Team was notified that Cargo incorrectly handled
symlinks inside of crate tarballs downloaded from third-party registries,
allowing a malicious crate to override the source code of another crate from the
same registry.
This vulnerability is tracked as CVE-2026-5223. The severity of the
vulnerability is medium for users of third-party registries. Users of
crates.io are not affected, as crates.io forbids uploading crates containing
any symlink.
Overview
When building a crate, Cargo extracts its source code in a local cache (stored
within ~/.cargo), reusing it for any future build. Cargo includes protections
to prevent any file from being extracted outside of the crate's own cache
directory.
It was discovered that it's possible to craft a malicious tarball able to
extract files one level below the crate's own cache directory. With the way the
cache is structured, that allowed the malicious crate to override the cache of
other crates belonging to the same registry.
Mitigations
Rust 1.96.0, to be released on May 28th, 2026, will update Cargo to reject
extracting any symlink within crate tarballs, regardless of whether they come
from crates.io (which already forbids them) or third-party registries. Note that
Cargo never added symlinks when running cargo package or cargo publish, so
the impact of this should be minimal.
Users who are not able to upgrade to the most recent Rust version are
recommended to audit the contents of their registry for the presence of any
symlink, and to configure their registry to reject symlink (if such option is
available).
Affected versions
All versions of Cargo shipped before Rust 1.96.0 are affected.
Acknowledgements
We'd like to thank Christos Papakonstantinou for reporting this to us according
to the Rust security policy.
We also want to thank the members of the Rust project who helped us address the
vulnerability: Josh Triplett for developing the fix; Arlo Siemsen for reviewing
the fix; Emily Albini for writing this advisory; Emily Albini, Josh Stone and
Manish Goregaokar for coordinating the disclosure; Ed Page and Eric Huss for
advising during the disclosure.
The Rust Security Response Team was notified that Cargo incorrectly normalized
the URLs of third-party registries using the sparse index protocol. If a
hosting provider allowed multiple registries to be hosted with arbitrary names
within the same domain, an attacker able to publish crates in a registry could
obtain the credentials of others users of the same registry.
This vulnerability is tracked as CVE-2026-5222. The severity of the
vulnerability is low, due to the extremely niche requirements needed to
achieve the attack.
Overview
Originally Cargo only supported storing a registry's index within git
repositories. Most git hosting solutions allow accessing a git repository with
or without the .git suffix, so Cargo mirrored this behavior when normalizing
registry URLs. This allowed credentials for https://example.com/index to be
used for https://example.com/index.git.
This normalization was unintentionally applied to the new sparse indexes too.
Sparse indexes can be hosted on any HTTPS server, which treat URLs ending with
.git as different URLs than those without the suffix.
If the following conditions apply:
https://example.com/index is a sparse index.
https://example.com/index allows crates to depend on crates from any other
registry.
The attacker is able to publish crates on https://example.com/index.
The attacker is able to upload arbitrary files to
https://example.com/index.git.
...the attacker could configure https://example.com/index.git to be a Cargo
sparse registry requiring authentication for downloads, and with a download URL
pointing to a server recording any credentials set to it.
When the attacker then publishes a crate foo to https://example.com/index
depending on a crate bar from https://example.com/index.git, and tricks the
victim into downloading foo, Cargo will think the two registries share the
same credential and send the victim's Cargo token to the malicious registry.
Mitigations
Rust 1.96, to be released on May 28th, 2026, will update Cargo to only strip the
.git suffix from registry URLs using the git protocol. No mitigations are
available for users of older versions of Cargo.
Affected versions
All versions of Cargo shipped between Rust 1.68 (the stabilization of sparse
registries) and 1.96 are affected.
Acknowledgements
We'd like to thank Christos Papakonstantinou for reporting this to us according
to the Rust security policy.
We also want to thank the members of the Rust project who helped us address the
vulnerability: Arlo Siemens for developing the fix; Weihang Lo, Eric Huss and
Emily Albini for reviewing the fix; Emily Albini for writing this advisory;
Emily Albini, Josh Stone and Manish Goregaokar for coordinating the disclosure.
Leif Oines and Will Lachance introduce Glean Annotations: a process and technology for curating and communicating knowledge about the data we collect in Mozilla's products.
We try to be responsible with data. For example, we:
- store as little sensitive data as possible
- monitor changes in incoming data on which we've built models
But what happens when those two approaches conflict?
How do we monitor changes in incoming data that we don't want to store?
This talk explains the schema we use to monitor changes in what people are searching for in Firefox...even when we deliberately don't store some of what people are searching for.
The web is built by communities, but not all communities use the web the same way.
That philosophy shaped part of this week’s Firefox 151 release, which introduced support for the Web Serial API on desktop. Most folks won’t use this API, but for our community of builders and tinkerers, it unlocks the ability to use Firefox to communicate directly with compatible hardware devices like microcontrollers, development boards, and other serial-connected devices.
For developers, makers, educators, hardware enthusiasts, and embedded-device communities, browser-based hardware workflows have increasingly become part of the modern web experience. With Firefox’s browser engine, Gecko, now supporting Web Serial, users can now connect, code, configure, and control compatible hardware directly from the browser in many workflows, often without additional software or complicated setup.
If you want to dive deeper into the technical details behind Web Serial support in Firefox 151, you can read our full engineering post here.
Adafruit collaboration
As part of this week’s launch, Adafruit, one of the internet’s most beloved open-source hardware communities, is collaborating with us to test and validate what browser-based hardware development can look like in Firefox with Web Serial support.
If you’ve ever spent time with CircuitPython, browser-based board programming, custom controllers, sensors, classroom kits, STEM homework assignments, or a desk covered in blinking microcontrollers—you probably already know Adafruit.
With Web Serial support in Firefox 151, Adafruit’s browser-based hardware workflows now work directly in Firefox as well, with no additional software or complicated setup required for many projects. We invite you to give it a try.
Different communities care about different browser experiences. Some people want simplicity, familiarity and productivity. Others want flexibility, customization, and tools that support the way they work, build, experiment, and create. We want the web to be open, flexible, and shaped by the diversity of people building on it.
If you’re wiring up your first board, experimenting with hardware projects, or dusting off an old electronics kit, give Adafruit and Web Serial in Firefox a try.
Build something amazing. Make something useful. Tell us what works. Tell us what breaks. Most of all, make it your own.
Firefox can now connect directly to microcontrollers, development boards, 3D printers, power meters, and other serial-connected hardware from the web. Starting in Firefox 151 for Desktop, support for the Web Serial API allows web applications to communicate with compatible devices without requiring native software.
Web Serial compatible devices are popular among hobbyists, hardware hackers, educators, makers, and developers with use cases ranging from home automation to hardware prototyping and 3D printing. Web Serial support makes Firefox more useful for these kinds of projects.
One of the organizations that has demonstrated the value of Web Serial is Adafruit, a leader in open-source hardware and STEM education. They’ve made it quick and easy to install CircuitPython on their devices by delivering firmware over Web Serial. Then it’s straightforward to run Python programs on the device. Name your file code.py and, for most devices, the code can be installed by dragging-and-dropping the file onto the USB device. Your Python programs can interoperate with a web page over Web Serial using simple text-based I/O.
To install CircuitPython firmware with Firefox, we recommend using the Adafruit Web Serial Tool and not the OPEN INSTALLER method on the CircuitPython site.
Here’s an example using an Adafruit ESP32-S2 based board where messages sent from web code can be directly displayed on the device over Web Serial.
We’ve collaborated with Adafruit to test Firefox’s implementation against real hardware workflows commonly used by this community. The result: Firefox is a more practical browser for programming and interacting with hardware directly using web technology.
As an example of how you can combine Web Serial with electronics, Mozilla engineer Alex Franchuk created an amazingly fun and functional device that melds electronics and web editing. Check out the Page Playground.
The list of serial compatible devices includes Espressif ESP-based boards such as the popular ESP32 chips, Raspberry Pi Picos, 3D printers, LEGO devices, and many more. There are many tools for running your own code on these small affordable microcontroller boards, and with Web Serial it’s easier than ever to connect them to a computer and interact through a web-based user interface.
What is Web Serial?
Web Serial is a web API that allows a website to read and write to serial devices using JavaScript. See the MDN documentation for the details. While modern computers don’t typically include serial ports, serial devices connected to a USB port or paired via Bluetooth can advertise themselves as serial-capable devices so they appear as serial ports in the operating system.
The Web Serial API lets developers use the web platform to communicate with these devices. For example, websites can control devices or deliver firmware without requiring native applications or installers.
Mozilla’s own Florian Quèze, who has experimented with many projects to measure power consumption, demonstrated how Web Serial could be used to read power data from an off-the-shelf USB power meter and display it in Firefox. Florian’s code can also export the data into the Firefox Profiler, making it easy to visualize and share power data. Here’s the page and GitHub repo. The screenshots below show the page in action and the data in the Firefox Profiler after recording the power usage of a light with three brightness modes.
A screenshot of Florian’s site showing a power recording of a light with three brightness modes.The power meter used in the pictured power tests was the AVHzY C3 USB. The Joy-IT TC66C and YZXStudio USB ZY1280 were also successfully tested.
A screenshot of the Firefox Profiler displaying the imported power recording from Florian’s site.
Home Assistant is another example. It’s a popular (and growing) open source project for home automation. The ESPHome project offers Home Assistant-compatible firmware for affordable ESP32 and similar devices which can be installed and configured over Web Serial in just a few clicks.
Security and Privacy
There are clear security and privacy concerns with allowing the web platform to read and write to hardware devices. Most importantly, with Web Serial, websites do not have visibility or access to serial ports until the user explicitly allows it.
Ports are allowed on a per-site and per-port basis. The Web Serial API requires websites to call navigator.serial.requestPort(), which lets the user choose which port to allow access to, or disallow all access entirely. This means websites do not receive a list of connected devices and there is no useful fingerprinting information outside of the port the user selects.
A screenshot of the Web Serial port selection prompt in Firefox.
To help users understand when and why a site requests access to a serial port, Firefox uses add-on gating which we introduced with our Web MIDI API implementation. Compared to other web permission prompts, this gives the user a more detailed explanation of what they’re allowing. The add-on gating prompts appear before the port selection prompt the first time a site requests port access.
For organizations using Firefox Enterprise Policies, Web Serial is disabled by default. Administrators can explicitly allow or disallow Web Serial functionality across their organization using the DefaultSerialGuardSetting policy setting.
Standardization
While Web Serial still resides in the Web Incubator Community Group (WICG), we’re optimistic there’s a path to standardization given its scope and long-running incubation. We are pursuing standardizing the Web Serial API in the WHATWG in a new Workstream proposal and are excited to work with ecosystem partners and standards bodies to help shape access to peripherals on the web.
Feedback
If you already have a Web Serial workflow with a device you can test on, give Firefox a try. We’d love to hear what you’re building and which workflows matter most to you. Mozilla Connect is a great place to share projects, ask questions, and give feedback.
Crafted with care. Built for speed. Ready for what’s next.
A great browser is so intuitive that you often forget you’re using it. Yet today the internet is changing faster than ever, and your browser needs to keep up. Firefox is still the only browser built for people, not platforms: independent, customizable, private and firmly in users’ control.
Keeping Firefox the best browser for being online today is what motivated our recent work to update Firefox’s design and design system. We’re aiming to deliver a more cohesive foundation for Firefox: making the browser feel cleaner, warmer, faster and more adaptable.
Internally, we’ve been calling this work Project Nova. The name fits: A nova can look like a new star, yet it comes from existing matter — a renewal, not a replacement. When it rolls out later this year, you can just call it Firefox. Here’s what it’s all about:
Privacy at the center
A good default matters. When you choose Firefox, privacy and clear data practices are there from the start. Our new design pulls privacy features forward, making it easier to find and use tools like our free, built-in VPN and private browsing.
We’re also redesigning Settings so choices about your data are easier to understand and act on. That includes controls for turning off AI features entirely, plainer language throughout, as well as tuning Enhanced Tracking Protection to match your preferred balance of protection and usability.
Speed you can feel
Privacy and speed aren’t trade-offs. When Firefox blocks trackers, pages load faster, too. We also prioritize the most important parts of a page before the optional stuff around the edges. In the last year, we’ve improved load times for key page content by 9%.
The new design can speed up your workflows, too. It’s easier to access tab groups, split view, and vertical tabs – putting these productivity features at your fingertips, but not in your face.
And we’re bringing back compact mode. People told us that they missed it, and we listened. If you want your browser controls as condensed as possible, this one’s for you.
Balancing the new and familiar
When it came to design, we wanted Firefox to feel current, but not generic. Warm, but still precise. More expressive, but never louder than the web itself. You’ll see the change first in the fundamentals:
Tabs have a softer shape, with a subtle gradient that gives the active tab more presence and creates a sense of light around the browser chrome.
Components are more rounded and consistent, so panels, menus, settings and browser controls feel like part of the same system.
Icons have been updated to feel cleaner and more balanced across light and dark themes, supporting quick recognition without adding visual noise.
Spacing is rebalanced across the interface with the knowledge that every pixel matters when the browser is where you spend your day.
The refreshed color palette is inspired by the feeling of fire: the glow around your active tab, deep smoky purples and lighter tones that add warmth.
The voice is warming up, too. Firefox copy is becoming more direct, more human, and sometimes more playful or fiery. Always genuine… because that’s what sets Firefox apart.
The effect is distinctly Firefox: approachable and energetic, while still easy to scan. Under the hood, reusable tokens, components, patterns, and a shared design language make Firefox easier to evolve over time, so new features feel integrated instead of bolted on.
The redesign is most visible on desktop, but the work extends to mobile, too. Shared colors, icons, copy and design foundations help Firefox feel more consistent across devices.
Yours to shape
Firefox has long been the most customizable browser. It’s in our open source DNA. Now we’re adding more ways to make Firefox feel like yours, including new themes and wallpapers. And we’re exploring more customization over time, like controls for the shape of the interface — tabs, components, and related visual treatments.
Accessibility is a key part of customization. Firefox is being designed with attention to contrast, readability, focus states, keyboard behavior, target sizes, system settings, visual comfort, and how the interface works across themes and windows.
Dark mode, for example, is not just a preference for many people. It is their default environment. For some, it helps reduce eye strain. For others, it is part of a broader system setup.
Building in public
Firefox has always been built in the open, and with the help of a global community of contributors and supporters. You help us build the browser, test, extend and improve it. You tell us when something doesn’t feel right. That relationship is part of what makes Firefox different.
While the new design system for Firefox is still being shaped, keep telling us what feels right, and what gets in your way. We’re listening.
The 2021 SciPy conference (https://www.scipy2021.scipy.org/) involved the showcasing of the latest open source Python projects for advancement in scientific computing. Mozilla was a diversity sponsor and a few Mozillians attended and shared their experience of the event.
Axe-time, sword-time, shields are sundered,
Wind-time, wolf-time, ere the world falls.
– Völuspá, Poetic Edda
As of Firefox 148, SpiderMonkey’s asm.js optimizations are disabled by default, and we plan to remove the code entirely in a future release.
If you maintain a site that uses asm.js, nothing will break. asm.js is just a subset of plain JavaScript, so the code keeps running through our regular JIT just like any other script. That said, recompiling to WebAssembly will get you faster execution and smaller binaries.
History
asm.js was Mozilla’s response to the question posed by NaCl and PNaCl: how can the web run code at native speeds?
The idea was clever: pick a strict, statically-typed subset of JavaScript that an engine could recognize on the fly and compile down to native code. We could get performance similar to NaCl/PNaCl and still have code live inside web content and use web API’s (no separate sandbox, IPC, or alternative API’s).
asm.js shipped in Firefox 22 back in 2013 and was a success. It let projects like Unity and Unreal ship C/C++ codebases to the web for the first time, using just standard web technologies. The Epic Citadel demo was ported to the web in just four days. It was a landmark achievement, and a fond memory for the original asm.js team.
asm.js proved that we could run code at near-native speed on the web using just web technologies. This opened the door to WebAssembly, which shipped several years later in Firefox 52. Without asm.js, we likely wouldn’t have WebAssembly.
Why now?
So why turn it off? WebAssembly has succeeded, and asm.js usage has mostly migrated over. Keeping the asm.js path alongside WebAssembly costs us maintenance time and gives us extra attack surface in the VM.
If you are shipping asm.js content, please consider recompiling to WebAssembly! Our WebAssembly pipeline is significantly more advanced than the asm.js one ever was. You should see faster execution and smaller binaries.
Ragnarök
The asm.js compiler is called OdinMonkey. As was foretold long ago, OdinMonkey must meet his fated doom. The bug Ragnarök tracks the “Twilight of OdinMonkey”.
All is not lost however, for born of OdinMonkey is BaldrMonkey, our WebAssembly optimizing compiler. OdinMonkey may be swallowed whole by the wolf, Fenrir, but BaldrMonkey will rule over the reborn world alongside RabaldrMonkey (“commotion”), our WebAssembly baseline compiler.
On this Odin’s day (Wednesday) we thank OdinMonkey for thirteen years of service. Skål!
Then fields unsowed bear ripened fruit,
all ills grow better, and Baldr comes back;
Baldr and Hoth dwell in Hropt’s battle-hall.
– Völuspá, Poetic Edda
The redesign of Firefox Settings is now enabled by default in Nightly! With this change, we are making it easier for people to customize Firefox and discover the controls that matter most to them. The redesign improves navigation and organization, updates labels and descriptions, and uses a new underlying architecture that will make Settings easier to update over time.
Firefox Settings have grown a lot over the years. Our research showed that some areas had become crowded and more difficult to navigate, and that important controls could be hard to discover. Some terminology and layouts had also become inconsistent over time. Internally, the existing structure also made Settings harder to maintain and evolve over time.
Here are some of the changes you’ll notice:
More pages within Settings, with less content per page
Clearer grouping and better flow between related controls
Improved labels and helper text
Consistent use of our design system throughout
The new Settings navigation and layout
While the organization of Settings has changed, all your existing choices and preferences remain in place. You can always use the search bar to jump straight to what you’re looking for.
We plan to ship the redesign to the Release channel in Firefox 152. You will continue to see changes in Nightly, and we welcome feedback, especially in Mozilla Connect.
Customization has long been a core part of Firefox, and this redesign is intended to continue improving how people discover and manage their browser settings. We appreciate all of the feedback from the community so far on this project and look forward to refining the experience with your input!
The Firefox for Android app has always had a complicated build process - we're cramping a complex cross-platform browser engine and all the related components that make it work on Android into one package. In its current form, it lives in the Firefox mono-repo at mozilla-central (now mozilla-firefox using the git repository).
I wanted to document my "artifact-mode" environment here since it's worked quite successfully for me for many years with minor changes.
NOTE: After a fresh clone of the mono-repo, don't forget to first run and follow the prompts of ./mach bootstrap .
mozconfig
My mozconfig below is enabled for artifact mode, but occasionally I switch between various configurations. You can see those commented out, with these few extra notes:
I like to separate out my objdirs to avoid cache pollution between the different build types. I think you can get away without needing to specify this and an objdir for your build type and arch will be generated.
sccache speeds up the native portion of full builds after the first slow one, but it's a hit or miss if you fetch from the remote repository but don't need to rebuild as often.
I don't care to manually run the clobber step, and I don't truly appreciate why that isn't always automatically done.
# Build GeckoView/Firefox for Android:ac_add_options --enable-application=mobile/android# Targeting the following architecture.# For regular phones, no --target is needed.# For x86 emulators (and x86 devices, which are uncommon):# ac_add_options --target=i686# For newer phones or Apple siliconac_add_options --target=aarch64# For x86_64 emulators (and x86_64 devices, which are even less common):# ac_add_options --target=x86_64# sccache will significantly speed up your builds by caching# compilation results. The Firefox build system will download# sccache automatically.# This only works for non-artifact builds.#ac_add_options --with-ccache=sccache# Enable artifact builds; manager-mode.ac_add_options --enable-artifact-builds# Write build artifacts to..## Full build dir#mk_add_options MOZ_OBJDIR=./objdir-droid#mk_add_options MOZ_OBJDIR=./objdir-desktop## Artifact buildsmk_add_options MOZ_OBJDIR=./objdir-frontend# Automatic clobbering; don't ask me.mk_add_options AUTOCLOBBER=1
JAVA_HOME
Sometimes you might find yourself needing to run a (non-mach) command in the terminal. Those typically will need to invoke some parts of gradle for an Android build, so it's best to make sure those are using the same JDK as the bootstrapped one in the mono-repo. This avoids weird build errors where something that compiles in one place isn't working in another (like Android Studio).
The location for the JDKs are typically in ~/.mozbuild/jdk/, and if you've between around for ~6 months you end up with multiple versions after every JDK bump:
$ ls -l ~/.mozbuild/jdk/drwxr-xr-x@ - jalmeida 15 Apr 2025 jdk-17.0.15+6drwxr-xr-x@ - jalmeida 15 Jul 2025 jdk-17.0.16+8drwxr-xr-x@ - jalmeida 21 Oct 2025 jdk-17.0.17+10drwxr-xr-x@ - jalmeida 20 Jan 09:00 jdk-17.0.18+8drwxr-xr-x@ - jalmeida 26 Feb 15:04 mozboot
You can find some way to point your latest JDK to one location or you can be lazy like me and pick the latest version to assign as your JAVA_HOME property by adding this to your shell's RC file:
export JAVA_HOME="$(ls -1dr -- $HOME/.mozbuild/jdk/jdk-* | head -n 1)/Contents/Home"
Android Studio
UPDATE: With D286123 landed, this should no longer be necessary! 🎉
Similarly for Android Studio, let's do the same so that environment is identical. Head to, Settings | Build, Execution, Deployment | Build Tools | Gradle, and ensure that "Gradle JDK" path is set to JAVA_HOME.
Lately, the default seems to be for it to follow GRADLE_LOCAL_JAVA_HOME which is a property we can't easily override, so we have to manually set this ourselves.
Using the same Android SDK also helps speed things up and avoids source confusion. You can typically find it in ~/.mozbuild/android-sdk-macosx and update it at Settings | Languages & Frameworks | Android SDK.
Debugging
This section is for miscellaneous build error situations that come-up, but assuming mach build work and there are no known Android build changes, my solution has typically always been the same.
For example, the other day I fetched another engineers patch to test out locally1 as part of reviewing it where I faced the error message below:
Execution failed for task ':components:feature-pwa:compileDebugKotlin'.
FAILURE: Build failed with an exception.* What went wrong:Execution failed for task ':components:feature-pwa:compileDebugKotlin'.> A failure occurred while executing org.jetbrains.kotlin.compilerRunner.GradleCompilerRunnerWithWorkers$GradleKotlinCompilerWorkAction > Internal compiler error. See log for more details* Try:> Run with --info or --debug option to get more log output.> Run with --scan to generate a Build Scan (powered by Develocity).> Get more help at https://help.gradle.org.* Exception is:org.gradle.api.tasks.TaskExecutionException: Execution failed for task ':components:feature-pwa:compileDebugKotlin'. at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.lambda$executeIfValid$1(ExecuteActionsTaskExecuter.java:135) at org.gradle.internal.Try$Failure.ifSuccessfulOrElse(Try.java:288) at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.executeIfValid(ExecuteActionsTaskExecuter.java:133) at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.execute(ExecuteActionsTaskExecuter.java:121) at org.gradle.api.internal.tasks.execution.ProblemsTaskPathTrackingTaskExecuter.execute(ProblemsTaskPathTrackingTaskExecuter.java:41) at org.gradle.api.internal.tasks.execution.FinalizePropertiesTaskExecuter.execute(FinalizePropertiesTaskExecuter.java:46) at org.gradle.api.internal.tasks.execution.ResolveTaskExecutionModeExecuter.execute(ResolveTaskExecutionModeExecuter.java:51) at org.gradle.api.internal.tasks.execution.SkipTaskWithNoActionsExecuter.execute(SkipTaskWithNoActionsExecuter.java:57) at org.gradle.api.internal.tasks.execution.SkipOnlyIfTaskExecuter.execute(SkipOnlyIfTaskExecuter.java:74) at org.gradle.api.internal.tasks.execution.CatchExceptionTaskExecuter.execute(CatchExceptionTaskExecuter.java:36) at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter$1.executeTask(EventFiringTaskExecuter.java:77) at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter$1.call(EventFiringTaskExecuter.java:55) at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter$1.call(EventFiringTaskExecuter.java:52) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:209) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:204) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:66) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:166) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.call(DefaultBuildOperationRunner.java:53) at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter.execute(EventFiringTaskExecuter.java:52) at org.gradle.execution.plan.DefaultNodeExecutor.executeLocalTaskNode(DefaultNodeExecutor.java:55) at org.gradle.execution.plan.DefaultNodeExecutor.execute(DefaultNodeExecutor.java:34) at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$InvokeNodeExecutorsAction.execute(DefaultTaskExecutionGraph.java:355) at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$InvokeNodeExecutorsAction.execute(DefaultTaskExecutionGraph.java:343) at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$BuildOperationAwareExecutionAction.lambda$execute$0(DefaultTaskExecutionGraph.java:339) at org.gradle.internal.operations.CurrentBuildOperationRef.with(CurrentBuildOperationRef.java:84) at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$BuildOperationAwareExecutionAction.execute(DefaultTaskExecutionGraph.java:339) at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$BuildOperationAwareExecutionAction.execute(DefaultTaskExecutionGraph.java:328) at org.gradle.execution.plan.DefaultPlanExecutor$ExecutorWorker.execute(DefaultPlanExecutor.java:459) at org.gradle.execution.plan.DefaultPlanExecutor$ExecutorWorker.run(DefaultPlanExecutor.java:376) at org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:64) at org.gradle.internal.concurrent.AbstractManagedExecutor$1.run(AbstractManagedExecutor.java:47)Caused by: org.gradle.workers.internal.DefaultWorkerExecutor$WorkExecutionException: A failure occurred while executing org.jetbrains.kotlin.compilerRunner.GradleCompilerRunnerWithWorkers$GradleKotlinCompilerWorkAction at org.gradle.workers.internal.DefaultWorkerExecutor$WorkItemExecution.waitForCompletion(DefaultWorkerExecutor.java:289) at org.gradle.internal.work.DefaultAsyncWorkTracker.lambda$waitForItemsAndGatherFailures$2(DefaultAsyncWorkTracker.java:130) at org.gradle.internal.Factories$1.create(Factories.java:33) at org.gradle.internal.work.DefaultWorkerLeaseService.lambda$withoutLocks$2(DefaultWorkerLeaseService.java:344) at org.gradle.internal.work.ResourceLockStatistics$1.measure(ResourceLockStatistics.java:42) at org.gradle.internal.work.DefaultWorkerLeaseService.withoutLocks(DefaultWorkerLeaseService.java:342) at org.gradle.internal.work.DefaultWorkerLeaseService.withoutLocks(DefaultWorkerLeaseService.java:326) at org.gradle.internal.work.DefaultWorkerLeaseService.withoutLock(DefaultWorkerLeaseService.java:331) at org.gradle.internal.work.DefaultAsyncWorkTracker.waitForItemsAndGatherFailures(DefaultAsyncWorkTracker.java:126) at org.gradle.internal.work.DefaultAsyncWorkTracker.waitForItemsAndGatherFailures(DefaultAsyncWorkTracker.java:92) at org.gradle.internal.work.DefaultAsyncWorkTracker.waitForAll(DefaultAsyncWorkTracker.java:78) at org.gradle.internal.work.DefaultAsyncWorkTracker.waitForCompletion(DefaultAsyncWorkTracker.java:66) at org.gradle.api.internal.tasks.execution.TaskExecution$3.run(TaskExecution.java:260) at org.gradle.internal.operations.DefaultBuildOperationRunner$1.execute(DefaultBuildOperationRunner.java:29) at org.gradle.internal.operations.DefaultBuildOperationRunner$1.execute(DefaultBuildOperationRunner.java:26) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:66) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:166) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.run(DefaultBuildOperationRunner.java:47) at org.gradle.api.internal.tasks.execution.TaskExecution.executeAction(TaskExecution.java:237) at org.gradle.api.internal.tasks.execution.TaskExecution.executeActions(TaskExecution.java:220) at org.gradle.api.internal.tasks.execution.TaskExecution.executeWithPreviousOutputFiles(TaskExecution.java:203) at org.gradle.api.internal.tasks.execution.TaskExecution.execute(TaskExecution.java:170) at org.gradle.internal.execution.steps.ExecuteStep.executeInternal(ExecuteStep.java:105) at org.gradle.internal.execution.steps.ExecuteStep.access$000(ExecuteStep.java:44) at org.gradle.internal.execution.steps.ExecuteStep$1.call(ExecuteStep.java:59) at org.gradle.internal.execution.steps.ExecuteStep$1.call(ExecuteStep.java:56) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:209) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:204) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:66) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:166) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.call(DefaultBuildOperationRunner.java:53) at org.gradle.internal.execution.steps.ExecuteStep.execute(ExecuteStep.java:56) at org.gradle.internal.execution.steps.ExecuteStep.execute(ExecuteStep.java:44) at org.gradle.internal.execution.steps.CancelExecutionStep.execute(CancelExecutionStep.java:42) at org.gradle.internal.execution.steps.TimeoutStep.executeWithoutTimeout(TimeoutStep.java:75) at org.gradle.internal.execution.steps.TimeoutStep.execute(TimeoutStep.java:55) at org.gradle.internal.execution.steps.PreCreateOutputParentsStep.execute(PreCreateOutputParentsStep.java:50) at org.gradle.internal.execution.steps.PreCreateOutputParentsStep.execute(PreCreateOutputParentsStep.java:28) at org.gradle.internal.execution.steps.RemovePreviousOutputsStep.execute(RemovePreviousOutputsStep.java:68) at org.gradle.internal.execution.steps.RemovePreviousOutputsStep.execute(RemovePreviousOutputsStep.java:38) at org.gradle.internal.execution.steps.BroadcastChangingOutputsStep.execute(BroadcastChangingOutputsStep.java:61) at org.gradle.internal.execution.steps.BroadcastChangingOutputsStep.execute(BroadcastChangingOutputsStep.java:26) at org.gradle.internal.execution.steps.CaptureOutputsAfterExecutionStep.execute(CaptureOutputsAfterExecutionStep.java:69) at org.gradle.internal.execution.steps.CaptureOutputsAfterExecutionStep.execute(CaptureOutputsAfterExecutionStep.java:46) at org.gradle.internal.execution.steps.ResolveInputChangesStep.execute(ResolveInputChangesStep.java:39) at org.gradle.internal.execution.steps.ResolveInputChangesStep.execute(ResolveInputChangesStep.java:28) at org.gradle.internal.execution.steps.BuildCacheStep.executeWithoutCache(BuildCacheStep.java:189) at org.gradle.internal.execution.steps.BuildCacheStep.lambda$execute$1(BuildCacheStep.java:75) at org.gradle.internal.Either$Right.fold(Either.java:176) at org.gradle.internal.execution.caching.CachingState.fold(CachingState.java:62) at org.gradle.internal.execution.steps.BuildCacheStep.execute(BuildCacheStep.java:73) at org.gradle.internal.execution.steps.BuildCacheStep.execute(BuildCacheStep.java:48) at org.gradle.internal.execution.steps.StoreExecutionStateStep.execute(StoreExecutionStateStep.java:46) at org.gradle.internal.execution.steps.StoreExecutionStateStep.execute(StoreExecutionStateStep.java:35) at org.gradle.internal.execution.steps.SkipUpToDateStep.executeBecause(SkipUpToDateStep.java:75) at org.gradle.internal.execution.steps.SkipUpToDateStep.lambda$execute$2(SkipUpToDateStep.java:53) at org.gradle.internal.execution.steps.SkipUpToDateStep.execute(SkipUpToDateStep.java:53) at org.gradle.internal.execution.steps.SkipUpToDateStep.execute(SkipUpToDateStep.java:35) at org.gradle.internal.execution.steps.legacy.MarkSnapshottingInputsFinishedStep.execute(MarkSnapshottingInputsFinishedStep.java:37) at org.gradle.internal.execution.steps.legacy.MarkSnapshottingInputsFinishedStep.execute(MarkSnapshottingInputsFinishedStep.java:27) at org.gradle.internal.execution.steps.ResolveIncrementalCachingStateStep.executeDelegate(ResolveIncrementalCachingStateStep.java:49) at org.gradle.internal.execution.steps.ResolveIncrementalCachingStateStep.executeDelegate(ResolveIncrementalCachingStateStep.java:27) at org.gradle.internal.execution.steps.AbstractResolveCachingStateStep.execute(AbstractResolveCachingStateStep.java:71) at org.gradle.internal.execution.steps.AbstractResolveCachingStateStep.execute(AbstractResolveCachingStateStep.java:39) at org.gradle.internal.execution.steps.ResolveChangesStep.execute(ResolveChangesStep.java:64) at org.gradle.internal.execution.steps.ResolveChangesStep.execute(ResolveChangesStep.java:35) at org.gradle.internal.execution.steps.ValidateStep.execute(ValidateStep.java:62) at org.gradle.internal.execution.steps.ValidateStep.execute(ValidateStep.java:40) at org.gradle.internal.execution.steps.AbstractCaptureStateBeforeExecutionStep.execute(AbstractCaptureStateBeforeExecutionStep.java:76) at org.gradle.internal.execution.steps.AbstractCaptureStateBeforeExecutionStep.execute(AbstractCaptureStateBeforeExecutionStep.java:45) at org.gradle.internal.execution.steps.AbstractSkipEmptyWorkStep.executeWithNonEmptySources(AbstractSkipEmptyWorkStep.java:136) at org.gradle.internal.execution.steps.AbstractSkipEmptyWorkStep.execute(AbstractSkipEmptyWorkStep.java:66) at org.gradle.internal.execution.steps.AbstractSkipEmptyWorkStep.execute(AbstractSkipEmptyWorkStep.java:38) at org.gradle.internal.execution.steps.legacy.MarkSnapshottingInputsStartedStep.execute(MarkSnapshottingInputsStartedStep.java:38) at org.gradle.internal.execution.steps.LoadPreviousExecutionStateStep.execute(LoadPreviousExecutionStateStep.java:36) at org.gradle.internal.execution.steps.LoadPreviousExecutionStateStep.execute(LoadPreviousExecutionStateStep.java:23) at org.gradle.internal.execution.steps.HandleStaleOutputsStep.execute(HandleStaleOutputsStep.java:75) at org.gradle.internal.execution.steps.HandleStaleOutputsStep.execute(HandleStaleOutputsStep.java:41) at org.gradle.internal.execution.steps.AssignMutableWorkspaceStep.lambda$execute$0(AssignMutableWorkspaceStep.java:35) at org.gradle.api.internal.tasks.execution.TaskExecution$4.withWorkspace(TaskExecution.java:297) at org.gradle.internal.execution.steps.AssignMutableWorkspaceStep.execute(AssignMutableWorkspaceStep.java:31) at org.gradle.internal.execution.steps.AssignMutableWorkspaceStep.execute(AssignMutableWorkspaceStep.java:22) at org.gradle.internal.execution.steps.ChoosePipelineStep.execute(ChoosePipelineStep.java:40) at org.gradle.internal.execution.steps.ChoosePipelineStep.execute(ChoosePipelineStep.java:23) at org.gradle.internal.execution.steps.ExecuteWorkBuildOperationFiringStep.lambda$execute$2(ExecuteWorkBuildOperationFiringStep.java:67) at org.gradle.internal.execution.steps.ExecuteWorkBuildOperationFiringStep.execute(ExecuteWorkBuildOperationFiringStep.java:67) at org.gradle.internal.execution.steps.ExecuteWorkBuildOperationFiringStep.execute(ExecuteWorkBuildOperationFiringStep.java:39) at org.gradle.internal.execution.steps.IdentityCacheStep.execute(IdentityCacheStep.java:46) at org.gradle.internal.execution.steps.IdentityCacheStep.execute(IdentityCacheStep.java:34) at org.gradle.internal.execution.steps.IdentifyStep.execute(IdentifyStep.java:44) at org.gradle.internal.execution.steps.IdentifyStep.execute(IdentifyStep.java:31) at org.gradle.internal.execution.impl.DefaultExecutionEngine$1.execute(DefaultExecutionEngine.java:64) at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.executeIfValid(ExecuteActionsTaskExecuter.java:132) ... 30 moreCaused by: org.jetbrains.kotlin.gradle.tasks.FailedCompilationException: Internal compiler error. See log for more details at org.jetbrains.kotlin.gradle.tasks.TasksUtilsKt.throwExceptionIfCompilationFailed(tasksUtils.kt:22) at org.jetbrains.kotlin.compilerRunner.GradleKotlinCompilerWork.run(GradleKotlinCompilerWork.kt:112) at org.jetbrains.kotlin.compilerRunner.GradleCompilerRunnerWithWorkers$GradleKotlinCompilerWorkAction.execute(GradleCompilerRunnerWithWorkers.kt:75) at org.gradle.workers.internal.DefaultWorkerServer.execute(DefaultWorkerServer.java:68) at org.gradle.workers.internal.NoIsolationWorkerFactory$1$1.create(NoIsolationWorkerFactory.java:64) at org.gradle.workers.internal.NoIsolationWorkerFactory$1$1.create(NoIsolationWorkerFactory.java:61) at org.gradle.internal.classloader.ClassLoaderUtils.executeInClassloader(ClassLoaderUtils.java:100) at org.gradle.workers.internal.NoIsolationWorkerFactory$1.lambda$execute$0(NoIsolationWorkerFactory.java:61) at org.gradle.workers.internal.AbstractWorker$1.call(AbstractWorker.java:44) at org.gradle.workers.internal.AbstractWorker$1.call(AbstractWorker.java:41) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:209) at org.gradle.internal.operations.DefaultBuildOperationRunner$CallableBuildOperationWorker.execute(DefaultBuildOperationRunner.java:204) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:66) at org.gradle.internal.operations.DefaultBuildOperationRunner$2.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:166) at org.gradle.internal.operations.DefaultBuildOperationRunner.execute(DefaultBuildOperationRunner.java:59) at org.gradle.internal.operations.DefaultBuildOperationRunner.call(DefaultBuildOperationRunner.java:53) at org.gradle.workers.internal.AbstractWorker.executeWrappedInBuildOperation(AbstractWorker.java:41) at org.gradle.workers.internal.NoIsolationWorkerFactory$1.execute(NoIsolationWorkerFactory.java:58) at org.gradle.workers.internal.DefaultWorkerExecutor.lambda$submitWork$0(DefaultWorkerExecutor.java:176) at org.gradle.internal.work.DefaultConditionalExecutionQueue$ExecutionRunner.runExecution(DefaultConditionalExecutionQueue.java:194) at org.gradle.internal.work.DefaultConditionalExecutionQueue$ExecutionRunner.access$700(DefaultConditionalExecutionQueue.java:127) at org.gradle.internal.work.DefaultConditionalExecutionQueue$ExecutionRunner$1.run(DefaultConditionalExecutionQueue.java:169) at org.gradle.internal.Factories$1.create(Factories.java:33) at org.gradle.internal.work.DefaultWorkerLeaseService.lambda$withLocksAcquired$0(DefaultWorkerLeaseService.java:269) at org.gradle.internal.work.ResourceLockStatistics$1.measure(ResourceLockStatistics.java:42) at org.gradle.internal.work.DefaultWorkerLeaseService.withLocksAcquired(DefaultWorkerLeaseService.java:267) at org.gradle.internal.work.DefaultWorkerLeaseService.withLocks(DefaultWorkerLeaseService.java:259) at org.gradle.internal.work.DefaultWorkerLeaseService.runAsWorkerThread(DefaultWorkerLeaseService.java:127) at org.gradle.internal.work.DefaultWorkerLeaseService.runAsWorkerThread(DefaultWorkerLeaseService.java:132) at org.gradle.internal.work.DefaultConditionalExecutionQueue$ExecutionRunner.runBatch(DefaultConditionalExecutionQueue.java:164) at org.gradle.internal.work.DefaultConditionalExecutionQueue$ExecutionRunner.run(DefaultConditionalExecutionQueue.java:133) ... 2 more
The full trace was long and didn't seem related to a code failure in the module itself. So I employed the solution, which is always the same:
./mach build
In Android Studio, File > Sync Project with Gradle Files.
Yup, that's all. Very simple and boring.
1
With Jujutsu, this is the moz-phab command I use which has made it easier to manage review patches: moz-phab patch <patch-id> --no-branch --apply-to main@origin
Comments
With an account on the Fediverse or Mastodon, you can respond to this post. Since Mastodon is decentralized, you can use your existing account hosted by another Mastodon server or compatible platform if you don't have an account on this one. Known non-private replies are displayed below.
Learn how this was implemented from the original source here.
<noscript><p>Loading comments relies on JavaScript. Try enabling JavaScript and reloading, or visit <a href="https://mindly.social/@jonalmeida/116197244320129422">the original post</a> on Mastodon.</p></noscript>
<noscript>You need JavaScript to view the comments.</noscript>
&>"'
Update on May 19, 2026: Firefox’s free built-in VPN now supports location selection, giving people access to a fully comprehensive VPN experience directly within the browser. Starting today, Firefox users in the U.S., U.K., France, Germany, and Canada can choose to browse from any of the countries where we’ve launched VPN support. Browsing is subject to the local laws and content restrictions of the selected region.
Original post from March 2026:
Today we’re introducing a free built-in VPN in Firefox, a new IP-protection feature designed to keep you even more private while you browse. We’re starting by offering an industry-leading 50 gigabytes of free VPN-browsing each month.
Firefox has long focused on building privacy tools directly into the browser to protect you online. Over the years, we’ve introduced world-class protections that block known trackers, reduce fingerprinting and limit how companies can follow people across the web. Our goal has been consistent: make meaningful privacy protections accessible to Firefox users every day.
Firefox is the only major browser to include a built-in VPN like this for free — giving you more control over your privacy, right where you browse.
Privacy built into the browser
Every time you visit a website, your IP address is shared automatically. IP addresses help websites know where to send information back to your device, but they can also be used to approximate your location, link your browsing activity across sites and keep logs about your online behavior, meaning websites can track your behavior. It’s one of many ways companies track activity across the internet.
Additionally, when you’re using public Wi-Fi while at a coffee shop, in a hotel, or in your dorm, people can spy on your network traffic and see which websites you might be visiting.
At Mozilla, we believe people should have stronger protections against this kind of tracking and spying, and that those protections should be easy to use.
Introducing built-in VPN
Our free built-in VPN is designed to make IP protection simple to use in Firefox.
The built-in VPN includes an unprecedented 50 GB per month of free VPN browsing, enough to cover everyday activities like shopping, banking, and reading.
Turn it on in Firefox with a single click. No extra apps. No downloads. Once it’s on, Firefox routes your browsing traffic through a proxy network that replaces your IP address before it reaches a website. The sites you visit see the proxy’s IP address rather than your own. Firefox already encrypts your traffic with HTTPS, but masking your IP adds another layer of privacy. You can mask the URLs you’re visiting from anyone trying to spy on your network traffic on public Wi-Fi, like while you’re enjoying a latte at your favorite coffee shop.
If you reach the monthly limit, IP protection is paused until the next cycle. Firefox will require you to confirm before proceeding without the VPN so your browsing doesn’t unintentionally continue without IP protection.
Browser-level protection and full-device protection
The free built-in VPN helps secure your traffic while browsing in Firefox, making it a simple way to protect your IP address from being tracked by big tech. However, it does not offer full device protection.
For those looking for broader coverage, you can also choose protection that extends across your entire device, including other apps. The standalone Mozilla VPN subscription offers this capability with unlimited data across multiple devices. Depending on your needs, you can pick the level of privacy and protection that suits you.
We’ve heard concerns about so-called “free VPNs,” which often rely on advertising or selling user data to generate revenue. Firefox’s built-in VPN is designed differently. It does not sell your browsing data and does not inject advertising into your traffic. Instead, we offer a limited amount of browser-level protection for free, alongside Mozilla VPN, our paid, unlimited, full-device VPN service.
The free built-in VPN is currently rolling out as a beta to Firefox desktop users in the United States, the United Kingdom, Germany and France, with plans to expand to additional countries coming soon over the next several releases.
As with many Firefox features, we’re introducing it gradually starting in Firefox 149 so we can learn from user feedback and continue improving the experience.
Building a more private web
Protecting privacy online is an ongoing effort. As the web evolves, new technologies create both opportunities and challenges for keeping personal information safe.
Mozilla has spent years building privacy protections — from Total Cookie Protection to Private browsing mode to anti-fingerprinting — directly into Firefox so people have more control over how they experience the web. This built-in VPN is one more way Firefox helps you browse with less exposure and more peace of mind.
By continuing to build these protections into Firefox, we aim to make the web safer, more transparent and more respectful of the people who use it.
Today, Firefox is rolling out updates across desktop and mobile that give you more choice over how you browse.
Here’s a look at what’s new.
Adding location selection to Firefox’s free VPN
Firefox now offers a fully featured VPN experience directly in the browser — for free. In just two months, over 1 million users have already signed up to try it.
With the addition of location selection, one of the most requested features from the Firefox community, Firefox’s free built-in VPN now delivers all the flexibility and functionality people expect from a modern VPN.
Starting today, Firefox users in the U.S., U.K., France, Germany, and Canada can choose to browse from any of the countries where we’ve launched VPN support. Whether you want to view local news, shop regionally, or see how content appears in another country, location selection gives you more control over where your connection appears from online.
Firefox will recommend the location closest to you by default, but people can switch locations at any time. Additional locations are planned for future releases. Browsing will still be subject to the local laws and content restrictions of the selected region.
Available in Firefox 151.
More controls over AI features on mobile
You can now decide how AI shows up in your Firefox mobile browsing experience, with more control over which AI features to activate and more ways to use them across devices and languages.
After launching AI controls on desktop earlier this year, Firefox is bringing them to iOS and Android. Depending on your device and region, available controls include features like translations, voice search and Shake to Summarize. Preferences can be updated at any time, making it easy to keep only the tools you want to use as new AI-powered features arrive in Firefox.
Shake to Summarize, recognized by TIME as one of the Best Inventions of 2025, helps you cut to the chase on mobile webpages by generating a simple summary with a flick of your wrist. The feature is now expanding to Android devices, with English rolling out first and additional languages coming soon. Shake to Summarize is now available on iOS in English, German, French, Spanish, Portuguese, Italian, and Japanese, giving more people the option to use it in the language that works best for them.
AI controls are available on iOS and Android. Shake to Summarize is available on Android in English and on iOS in English, German, French, Spanish, Portuguese, Italian, and Japanese.
A one-click reset for Private Browsing
Finished shopping for a surprise gift or logging into a temporary account? A new flame-shaped “Clear Private Session” button, located to the right of the address bar, instantly clears your current private session and starts a new one without requiring you to close and reopen the browser. Cookies, browsing history, logins, and other session data from your private windows are deleted automatically. Read more in this week’s release notes.
Try it out in Firefox 151.
Coming soon in Nightly: A refreshed settings page
Firefox is previewing a redesigned settings page in Nightly that makes it easier to find the controls you’re looking for and move through settings more intuitively. The redesign introduces improved navigation, clearer organization, and updated labels and descriptions designed to make customization easier.
Existing settings and preferences will remain unchanged, and the updated search experience helps people quickly find settings that may appear in new sections.
This will be enabled by default for Nightly users starting later this week.
Download the latest version of Firefox to explore what’s new and share feedback with us on Mozilla Connect.
Mobile browsing is personal. It’s the link you open from a group chat because someone said, “Wait, is this real?” It’s the article you read in the few quiet minutes you have to yourself. It’s the review you skim before buying something you’ve been thinking about all week.
On a phone, browsing follows you through the day, from the first thing you look up in the morning to the last tab you close at night. So when AI features are part of the experience, you should have a clear way to choose what helps and what stays off.
That’s why we’re bringing AI controls – a popular desktop feature on Firefox – to iOS and Android users. AI controls let you turn off Firefox’s AI features entirely, enable only the ones you want or adjust your choices later. The feature rolls out on mobile on May 19.
AI features you can choose on Firefox mobile
What you see may vary by device and location, but AI controls in Firefox mobile let you turn on or off features, including website translations and voice searchon Android, and translations and Shake to Summarize on iOS, where available.
As Firefox adds new features, you can come back to your settings and choose what works for you.
Mobile browsing on your terms
As AI becomes a bigger part of the web, the question isn’t just what it can do. It’s how much control people have over it.
In Firefox mobile, AI can help make browsing easier, from finding what you need to understanding pages faster. But Firefox isn’t just adding AI features. We’re adding the controls, too.
Decide how AI fits into your experience. Try the features you want. Turn off the ones you don’t. Keep browsing on your terms.
WebDriver is a remote control interface that enables introspection and control of user agents. As such, it can help developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 151 release cycle.
Contributions
Firefox is an open source project, and we are always happy to receive external code contributions to our WebDriver implementation. We want to give special thanks to everyone who filed issues, bugs and submitted patches.
In Firefox 151, Armin Ulrich contributed a fix to WebDriver BiDi:
Implemented the browser.setClientWindowState command. This command allows clients to change the OS-level window state of a browser window, such as maximized, minimized, fullscreen, or normal. It also allows repositioning and resizing the window.
Don’t let bloated websites slow you down. When you just need the gist, scrolling through ads and filler content can turn a quick check into an endless scroll.
Firefox’s Shake to Summarize feature solves that. We first launched it on iOS in English last September, earning a special mention in TIME’s Best Inventions of 2025 and a strong response from users. Since then, we’ve expanded it to iOS users in German, French, Spanish, Portuguese, Italian and Japanese. Starting today, we’re bringing it to Android users in English, with more languages coming soon.
Get the gist in seconds
On any web page under 5,000 words, just shake your phone and a clean summary will instantly appear.
If you prefer tapping, you can select Summarize Page under More in the three-dot menu.
Powered by AI, protected by Firefox
To keep your data secure, Shake to Summarize uses different technology depending on your device:
On iPhone 15 Pro or later (running iOS 26+): Your summary is generated right on your device using Apple Intelligence.
On all other devices: Your text is sent securely to Mozilla’s cloud-based AI. We power this with Mistral-Small, an AI model carefully selected for its speed, efficiency, and alignment with an open internet
Your phone’s default browser leaves you stuck scrolling through cluttered pages and content overload.
The Firefox mobile team is taking a purposeful approach – with smart tools that respect your time, privacy and choices. Download Firefox today to try Shake to Summarize, and get ready for even more features designed to help you move faster and protect your focus.
The 2025H2 Project Goal period has now concluded. Over these months, the Rust Project pursued 41 Project Goals, 13 of which were designated as Flagship Goals. This post contains curated updates on our progress since the last post and the final status for each of the goals (many of which continue as part of the 2026 period). Full details for any particular goal are available in its tracking issue.
Self-reviewed Implement borrowck for &pin mut|const $place. Found that the current approach of handling pinned borrows may be incorrect, as it failed to distinguish a pinned borrow from a coercion of a normal-to-pinned reference. The latter doesn't prevent a T: Unpin type from being moved, but the former does, which breaks the pin coercion test.
At the beginning of December, we set out to answer five important questions regarding the virtual places approach. We discussed four questions and arrived at answers for three.
Earlier this month, NadrierilDing Xiang Fei and I held a meeting on autoref and method resolution in a world with field projections. This meeting resulted in a new page for the wiki on autoref.
The first pull request of the lang experiment has just been merged: rust-lang/rust#152730
This PR enables the use of the field_of! macro to obtain a unique type for each field of a struct, enum variant, tuple, or union. We call these types field representing types (FRTs). When the base type is a struct that is not repr(packed), only contains Sized fields, this type automatically implements the Field trait that exposes some information about the field to the type system. The offset in bytes from the start of the struct, the type of the field and the type of the base type.
The feature is still incomplete and highly experimental. We also want to tackle the limitations in future PRs. For the moment this is enough to give us the ability to experiment with library versions of field projections and write functions that are generic over the fields of structs. For example one can write code like this:
#![feature(field_projections)]use std::field::{Field, field_of};use std::ptr;fn project_ref<'a, T, F: Field<Base = T>>(r: &'a T) -> &'a F::Type { // SAFETY: the `Field` trait guarantees that this is sound. unsafe { &*ptr::from_ref(r).byte_add(F::OFFSET).cast() }}struct Struct { field: i32, other: u32,}fn main() { let s = Struct { field: 42, other: 24 }; let r = &s; let field = project_ref::<_, field_of!(Struct, field)>(r); let other = project_ref::<_, field_of!(Struct, other)>(r); println!("field: {field}"); // prints 42 println!("other: {other}"); // prints 24}
A very important feature of the types returned by field_of! is that you can implement traits for them if you own the base type. This allows anointing fields with information by extending the Field trait. For example, this allows encoding the property of being a structurally pinned field:
use std::pin::Pin;unsafe trait PinnableField: Field { type StructuralRefMut<'a> where Self::Type: 'a, Self::Base: 'a; fn project_mut<'a>(base: Pin<&'a mut Self::Base>) -> Self::StructuralRefMut<'a> where Self::Type: 'a, Self::Base: 'a;}fn project_pinned<'a, T, F>(r: Pin<&'a mut T>) -> <F as PinnableField>::StructuralRefMut<'a>where F: PinnableField<Base = T>,{ F::project_mut(r)}
We can then implement this extra trait for all of the fields of our struct (and automate that with a proc-macro):
unsafe impl PinnableField for field_of!(Struct, field) { type StructuralRefMut<'a> = &'a mut i32; fn project_mut<'a>(base: Pin<&'a mut Self::Base>) -> Self::StructuralRefMut<'a> where Self::Type: 'a, Self::Base: 'a, { let base = unsafe { Pin::into_inner_unchecked(base) }; &mut base.field }}unsafe impl PinnableField for field_of!(Struct, other) { type StructuralRefMut<'a> = Pin<&'a mut u32>; // u32 is `Unpin`, so this isn't doing anything special, but it highlights the pattern. fn project_mut<'a>(base: Pin<&'a mut Self::Base>) -> Self::StructuralRefMut<'a> where Self::Type: 'a, Self::Base: 'a, { let base = unsafe { Pin::into_inner_unchecked(base) }; unsafe { Pin::new_unchecked(&mut base.other) } }}
Now you can safely obtain a pinned mutable reference to other and a normal mutable reference to field by calling the project_pinned function and supplying the correct FRT.
We have an updated plan for this goal in 2026 consisting of three major steps:
a-mir-formality,
Implementation,
Experimentation.
Some of their subtasks depend on other subtasks for other steps. You can find the details in the updated tracking issue. Here is a short rundown of each:
a-mir-formality: we want to create a formal model of the borrow checker changes we're proposing to ensure correctness. We also want to create a document explaining our model in a more human-friendly language. To really get started with this, we're blocked on the new expression based syntax in development by Niko.
Implementation: at the same time, we can start implementing more parts in the compiler. We will continue to improve FRTs, while keeping in mind that we might remove them if they end up being unnecessary. They still pose for a useful feature, but they might be orthogonal to field projections. We plan to make small and incremental changes, starting with library additions. We also want to begin exploring potential desugarings, for which we will add some manual and low level macros. When we have that figured out, we can fast-track syntax changes. When we have a sufficiently mature formal model of the borrow checker integration, we will port it to the compiler. After further evaluation, we can think about removing the incomplete_feature flag.
Experimentation: after each compiler or standard library change, we look to several projects to stress-test our ideas in real code. I will take care of experimentation in the Linux kernel, while Tyler Mandry will be taking a look at testing field projections with crubit. Josh Triplett also has expressed eagerness of introducing them in the standard library; I will coordinate with him and the rest of t-libs-api to experiment there.
Yesterday, we held a t-lang design meeting on our current approach. Nadrieril and I authored a design document with the feedback of Tyler Mandry, Ding Xiang Fei, Alice Ryhl, and Gary Guo. In this document, we provided the motivation for this feature, what the look and feel of a solution fitting into the existing features of Rust is, and a comprehensive + compact introduction to our current approach based on virtual places.
The general reception was extremely positive. To give some concrete quotes from the meeting:
Josh:
I adore this! I love how orthogonal it is, and how impactful and universal it is. I anticipate this becoming a beloved, pervasive feature of Rust.
Places and projection seem important enough to me that they're worth giving one of our precious remaining ASCII sigils to, and @ is nicely evocative of a place (something is at a place). So to the extent the final syntax benefits from a sigil, :+1: for giving this @. (See some feedback below on the details, though.)
TC:
Love it. High concept. As I said in the last meeting:
I particularly like language features that reduce the need for library surface area, and this is one of those.
There are, of course, many details to resolve and understand further, e.g., with respect to migration issues, interaction with const, async, and other effect-like things, etc. I'm looking forward to seeing the formalization work.
tmandry:
What I love about this direction is how effectively it builds on what Rust already has. I love to see designs that reinforce our existing concepts while pushing them in directions that make them more expressive.
Jack:
Whoo boy. This is great. There's so much here that I'm not exactly sure where to begin and what to comment on. I think this is the type of thing that we will only really be able to figure out the nitty gritty details and ergonomics only after some amount of experimentation.
There are a few takeaways from this meeting:
Mark raised the concern that t-libs should be more involved in reviewing the experimental traits that we intend to add. Ensuring that we don't accidentally stabilize or expose some behavior, have sufficient documentation on our experimental traits, and that t-libs is in the loop of this feature in general.
Mark offered to review PRs and I will be tagging him in those.
Jack raised the concern that increasing the cognitive load for the 95% use-case should be avoided. Making the right choice between @ and & might be challenging for users.
We discussed this point more in the meeting and concluded with that we need to do some experimentation, possibly utilizing the user research team. We will of course keep this in mind and revisit it later when we have a partially working implementation.
TC requested that we publish our fine-grained design axioms, essentially the list of things we go through when considering a modification of our proposal.
I will write an update on this issue explaining exactly those.
Aside from the concerns and directly actionable items, the meeting also covered design questions/comments that we want to take a look at in the coming weeks/months:
PR open to get the first working version of the Reborrow and CoerceShared traits merged.
Blockers
Currently "blocked" on PR review, and of course my (and Ding's) work to fix all review issues.
The review has brought up an opportunity to replace Rvalue::Ref / ExprKind::Ref with a more generalised variant that could encompass both references and user-defined references. This would be powerful, but it would be a very big and scary change. If this turns out to be a blocking issue for reviewers, then this will block the goal for the foreseeable future as the PR then starts on a massive refactoring.
Help wanted
The PR currently does not include derive traits, but we'd really want them. Instead of these:
impl<'a> Reborrow for CustomMarker<'a> {}impl<'a> CoerceShared<CustomMarkerRef<'a>> for CustomMarker<a'> {}impl<'a, T> Reborrow for CustomMut<'a, T> {}impl<'a, T> CoerceShared<CustomRef<'a, T>> for CustomMut<'a, T> {}
If anyone feels like picking up this thread, that'd be awesome: the derive macros do not need to really perform any validity checking, as the trait itself will do that.
If the PR merges soon, then public testing and exploration of the traits will be the next big thing. Likely concurrently with that the massive refactoring to generalise Rvalue::Ref / ExprKind::Ref.
No major updates this cycle - we're still working through feedback on rust-lang/rfcs#3874 and rust-lang/rfcs#3875 and prototyping the implementation to be prepared.
Update this cycle is the same as last time - rust-lang/rfcs#3874 and rust-lang/rfcs#3875 are progressing, with feedback being addressed and checkboxes checked, and we're still working out what the implementation would look like.
rust-lang/rfcs#3874 has finished FCP and is due to be merged any day now. I'm working on resolving the remaining open comments on rust-lang/rfcs#3875 and then intend to nudge the reviewers to have a look and check their boxes or leave concerns.
Adam Gemmell has opened rust-lang/cargo#16675 with an early sketch of some of the core changes that build-std would require and is working with the Cargo team to address feedback and work out how to proceed with the implementation.
There hasn't been too much progress over the last few weeks and I've been mostly taking a Christmas break. Nicholas Nethercote has been looking into the performance of the new trait solver, cleaning up canonicalization and slightly improving its performance: PR 1 and PR 2.
Shoyu Vanilla looked into ICE from mir validation on unsizing in opendal and uncovered the underlying bug there. While this issue also affects the old solver and the proper fix for it requires where-bounds on binders, we can work around this bug in the trait solver for now and intend to do so.
We've started another crater run with all our recent changes and adwin has started to triage it, uncovering one new issue up until now. Intend to continue going through that over the next few weeks.
we discussed how to investigate and fix the remaining correctness issues in Tage's work, to be able to evaluate it more accurately: in particular around variance and bidirectional edges, and without the reliance on NLL (having computed region values / errors)
we've tried to see if it'd be possible to remove the cfg region elements
Amanda is still working on her two papers, one about the current borrow checker and one about the work on Polonius. Her major PR for the restructuring of placeholder handling during region inference is stalled due to a conflict with further trait solver developments and may have to be abandoned. Work with the larger types team is ongoing and smaller patches/refactorings/improvements are being landed in the meantime.
I've also fixed more small inefficiencies (computing boring/relevant locals on-demand in diagnostics, removed conversions between locations and points, etc) building on top of the previous PRs (so they need to be reviewed first)
I've looked at crates.io again with the alpha, to find functions that are slower than with NLLs. AFAICT the worst case there is 60% for a 5KLOC function with 42K loans, 255K statements, and 125K outlives constraints. I'll see what we can do with this. Small composable functions is still good advice.
there seem to be optimization opportunities to 1. limit propagation to the smaller number of blocks that could be affected by bidirectional edges, 2. for unifying invariant lifetimes of live locals that are assigned at most once (à la use-def chains), 3. for invalidations that are just the activation of a reservation
we discussed possible plans to gather actual statistics, using the infrastructure that was created for the Metrics project
we're also preparing the new project goal for this year, where we'll want to stabilize the alpha 🤞
We had a bit less time this month, the update will be shorter, but still meaningful I hope:
#150551 has landed, and it feels stabilizable. To me, this part of the goal is achieved.
still, "stabilizable" is not stable, and there is more work to do. We plan to stabilize this year, and the project goal proposal for 2026 tracks how.
tiif is still deep in #152051, and a-mir-formality work with Niko and I.
Amanda has opened a few cleanup PRs (#152438, and #152579), and #151863 has landed already. She also has started looking into Tage's old PR to see if we can fix it, benchmark it more accurately, and see the cool parts there that we could be using.
Jack is possibly going to have some time to work with us this year! His help will be very welcome, especially as I will have less time available myself.
we'll be tracking the opaque type region liveness soundness issue in #153215, and I've added a couple tests, in case tiif's PR or anything that impacts them lands.
some of the tiny cleanups I mentioned last time have also landed in #152587.
The Rust Foundation is opening up a short-term, approximately 3-month, contracting role to assist in our Rust/C++ Interop initiative. The primary work and deliverables for the role will be to make substantial progress on the Problem Space Mapping Rust Project Goal by collecting discrete problem statements and offering up recommendations on the work that should follow based upon the problems that you found.
If you are interested in how programming languages interoperate, are curious in understanding the problems therein, and are have a passion to think about how those problems may be resolved for the betterment of interop, then this work may be for you.
An ideal candidate will have experience with Rust programming. Having experience in C++ is strongly preferred as well. If you have direct experience with actual engineering that required interoperating between Rust and C++ codebases, that's even better.
If you are interested, please email me (email address found in my GitHub profile) or contact me directly on Zulip by Tuesday, January 27 and we can take it from there to see if there may be a potential fit for further discussion.
The effort to fill the contracting role to support this project goal is in the process winding down. The interview and discussion process is nearly complete. We expect to make a final decision for the role in early February.
Next step is prioritising a few of the use cases, then working on related problem statements in more detail.
Blockers
Nothing at the moment, still working through the high level mapping of the problem space.
Help wanted
Suggestions for more interop use cases would be very welcome, just open a discussion in t-lang/interop and I'll turn it into a ticket. Or go ahead and open a use case ticket directly.
Next step is continuing to work on overloading and build systems in more detail. If you have specific Rust/C/C++ build system blockers, please open a chat or ticket.
Blockers
Nothing at the moment, everyone has been extremely helpful, and I'm getting good feedback on use cases, problems, priorities, and Rust language experiments.
these interop user experiences are waiting for analysis, so they can be summarised in the build system and overloading problem statements
this will likely happen after RustWeek and the All Hands
Next step is continuing to work on the overloading experiment, along with RustWeek/All Hands preparation, and collecting feedback during the conference.
Blockers
Nothing at the moment. There is a steady stream of new use cases, problems, code examples and Rust language experiment feedback.
Boxy and I have established a regular time to check-in on formalizing this within a-mir-formality. Today we mostly worked on the "model" of const values, starting with this
i.e., a const value can be a scalar value (as today) or a struct literal like Foo { ... } (which would also cover tuples and things). We got the various tests passing. Huzzah!
In addition to what niko posted previously there's been a lot of other stuff happening. A lot of people have opened PRs to improve mGCA this month: León Orell Valerian LiehrNoah Lev @enthropy7 Kivooeomu001999 @Human9000-bit Redddy @Keith-Cancel @AprilNEA
A rough list of things that have been improved for mGCA:
Lots of new expressions now supported by mGCA: const constructors, tuple constructor calls, array expressions, tuple expression, literals
associated_const_equality has been merged into min_generic_const_args. the former was effectively dependent on the latter already so this just makes it nicer to use the former :)
traits can now be dyn compatible if all associated constants are type consts and are specified in the trait object (e.g. dyn Trait<ASSOC = 10>)
type consts are enforced to be non-generic
a bunch of ICEs have been fixed
camelid has been working on "non-min" version of mGCA which will allow arbitrary expressions to be used in the type system (a blog post with more detail will be published once this actually lands)
In non-mGCA updates, as niko says, we've been meeting regularly to make progress on modelling const generics in a-mir-formality. I've also been spending time thinking about the interactions between adt_const_params and ADTs with privacy/safety invariants and I think I know how to structure the RFC in this area so can make progress on that again
There's been a lot of miscellaneous fixes for mGCA this month. I've also started drafting some blog posts to explain what's going on with mGCA/oGCA as well as soliciting use cases/experience reports for them and adt_const_params. I also talked with some folks at Rust Nation this month about const generics and what features would be useful for them and why.
Late on the update :') niko and i continue to meet to discuss const generics. we've made some progress on figuring out problems around privacy/safety in const generics. we've also been discussing the big picture stuff for const generics and where we're "heading".
started running weekly meetings about const generics to make it easier to keep up to date with all the people who are working on const generics stuff. i think min_adt_const_params is now at the point of what the RFC is going to specify.
GCA is making good progress thanks to ashley's work. i also met with lcnr where we talked about whether there was some version of mGCA that is stabilizeable in the near future or not (maybe!)
since we completed the 1.94.0 release of the FLS a bit early this time, we checked into the stretch part of our goal this year to look at 1.95.0 early
we learned a bit more of the release notes process thanks to tips from Eric Huss and TC
Tshepang Mbambo and I attended the t-release meeting last week where we chatted about working a little "upstream" with them on generating the release notes a bit earlier
tomorrow in our t-fls meeting we'll discuss our interest with engaging over there; at a minimum I'll get engaged with t-release
Glossary and main-body text harmonization:
the first PR landed from Tshepang Mbambo removing IDs from the glossary
further steps planned, we have a tracking issue for it
Developer guide:
akin to how the Reference now has a developer's guide now for contributing we'll do the same in the FLS
Yesterday, we posted an MCP for our retag intrinsics. While that's in progress, we'll start adapting our current prototype to remove our dependence on MIR-level retags. Once that's finished, we'll be ready to submit a PR.
We published our first monthly blog post about BorrowSanitizer.
Our overall goal for 2026 is to transition from a research prototype to a functional tool. Three key features have yet to be implemented: garbage collection, error reporting, and support for atomic memory accesses. Once these are complete, we'll be able to start testing real-world libraries and auditing our results against Miri.
We provide detailed error messages for aliasing violations, which look almost like Miri's do!
We have two forms of retag intrinsic: __rust_retag_mem and __rust_retag_reg. We no longer require a compiler plugin to determine the permission associated with a retag, which will make it possible to use BorrowSanitizer by providing a single -Zsanitizer=borrow flag to rustc. You can check out our MCP for more detailed design updates.
We are starting to have a better understanding of how BorrowSanitizer performs in practice, but we do not have enough data yet to be certain. From one test case, it seems like we are somewhat faster but still in the same category of performance as Miri when we compare against other sanitizers. Expect more detailed results to come as we scale up our benchmarking pipeline.
We have a tentative plan for upstreaming BorrowSanitizer in 2026, starting with its LLVM components. We intend to start the RFC process on the LLVM side this spring, once our API is stable.
We added hundreds more relevant tests from Miri's test suite. At the moment, 80% pass.
We improved our cargo plugin (cargo-bsan) to better support multilanguage libraries. This will let us start to recreate the bugs from our earlier evaluation.
Our goal for April is to continue expanding our test suite, finish an initial version of the LLVM components of BorrowSanitizer, and hopefully start the RFC process on the LLVM side.
We have some exciting news: our talk on BorrowSanitizer was accepted at RustConf this year! We’re grateful for the opportunity and looking forward to sharing our results with the broader community this September.
BorrowSanitizer now uses a shadow stack to track metadata at runtime - this is a significantly different strategy than other LLVM sanitizers, and it will help us support garbage collection.
We are now ready to start sending in PRs for our retag intrinsics. It will take a little time to split our changes up into meaningful, reviewable chunks—you can expect to see these throughout the next week.
The RFC for our LLVM components is taking a little longer than expected, but it was worth taking the extra time to test out compiler changes and make sure that we had the core parts of the instrumentation pass settled. We’ll be drafting the RFC throughout the next few weeks.
std::autodiff is moving closer to nightly, and std::offload is gaining various performance, feature, and hardware support improvements.
autodiff
Jakub Beránek, sgasho, and I continued working on enabling autodiff in nightly. We have a PR up that builds autodiff in CI, and verified that the artifacts can be installed and work on Linux. For apple however, we noticed that any autodiff usage hangs. After some investigation, it turns out that we ended up embedding two LLVM copies, one in rustc, and one in Enzyme. It should be comparably easy to get rid of the second one. Once we verified that this fixes the build, we'll merge the PR to enable autodiff on both targets in nightly.
offload
A lot of interesting updates on the performance, feature, and hardware support side.
Marcelo Domínguez, @kevinsala, @jdoerfert, and I started implementing the first benchmarks, since that's generally the best way to find missing features or performance issues. We were positively surprised by how good the out-of-the-box performance was. We will implement a few more benchmarks and post the results once we have verified them. We also implemented multiple PRs which implement bugfixes, cleanups, and needed features like support for scalars. We also started working on LLVM optimizations which make sure that we can achieve even better performance.
I noticed that our offload intrinsic allowed running Rust code on the GPU, but it wasn't of much help when calling gpu vendor libraries like cuBLAS. I implemented a new helper intrinsic which allows calling those functions conveniently, without having to manually move data to or from the device. It will benefit from the same LLVM optimizations as our full offload intrinsic. It also a bit simpler to set up on the compiler and linker side, so it already works with std and mangled kernel names, something that we still have to improve for our main offload intrinsic.
A lot of work happened on the LLVM offload side for SPIRV and Intel GPU support. At the moment, our Rust frontend is tested on NVIDIA and AMD server and consumer GPUs, as well as AMD HPC and Lapotop APUs. Karol Zwolak reached out since he wants to help with with also running Rust on Intel GPUs. Offload relies on LLVM which started gaining Intel support, so hopefully we won't need much work beyond a new intel-gpu target and a new stdarch module. There is also work on a new spirv target for rustc, which we could also support if it goes through LLVM. Due to some open questions around typed pointers it does not seem clear yet whether it will, so we will have to wait.
Nikita started working on updating our submodule to LLVM 22. This hopefully does not only brings some compile and runtime performance improvements, but also greatly simplifies how we can build and use offload. Once it landed I'll refactor our bootstrapping logic, and as part of that start building offload in CI.
std::autodiff is now partly in CI, and std::offload got tested on a lot more benchmarks.
autodiff
Work continued on enabling autodiff in nightly. Since the last update, we have enabled autodiff in some Mingw and Linux runners. Users can now download libEnzyme artifacts, place them locally in the right spot for their toolchain, and then use autodiff on their nightly compiler. Once macOS is added, we will enable a new rustup component that will handle the download for users. Before enabling autodiff on macOS, however, we want to change how we distribute LLVM on this target (from static to dynamic linking). There are a lot of workflows and users of this target, not all of which can be modelled in the Rust CI. Our last two attempts sadly broke such downstream users and local contributors, so both attempts had to be reverted. Since testing here is tricky, progress here might be on the slower side; we will see.
offload
Most of the work on the offload side lately has been invisible, since we were working on implementing more benchmarks and LLVM optimizations, as well as missing features, discovered by those benchmarks. We achieved excellent performance on those benchmarks; more details will soon be presented by Marcelo Domínguez at the EuroLLVM conference in two weeks!
Beyond benchmarks, there was a lot of tinkering on smaller PRs, reviewing, and housekeeping. LLVM-22 landed, so we updated our bootrstrap code to make use of new APIs, and tried to move a few smaller PRs forward, mainly around a better user experience and for making more Rust features available. Since the focus is still on benchmarks, not many of those PRs landed. They are in a mostly ready state, so it's a good time to pick them up if you're considering contributing. Please ping me on Zulip or in any PR with the offload label if you are interested!
It seems that figuring out which functions are noreturn is at a level too low for rustc. Function signatures are not sufficient and there are cases where rustc doesn't know whether to emit noreturn. It is something we should ask the LLVM to give us that information.
Alice Ryhl opened a new issue to introduce the -Zsanitizer=kernel-hwaddress sanitizer for aarch64 targets: https://github.com/rust-lang/compiler-team/issues/975
The corresponding RFC has been discussed by the Lang team on 2026-03-11. The overall vibe was positive and TC is going to read through it and hopefully check a box on the proposed FCP.
Ding's arbitrary_self_types: Split the Autoderef chain rust#146095 is waiting on reviews. It updates the method resolution to essentially: deref_chain(T).flat_map(|U| receiver_chain(U)).
The perf run was a wash and a carter has completed yesterday. Analysis pending.
We've discovered the #[feature(arbitrary_self_types_pointer)] feature gate. As the Lang consensus is to not support the Receiver trait on raw pointer types we're probably going to remove it (but this needs further discussion). This was a remnant from the original proposal, but the Lang has changed direction since.
Ding is writing a post to describe all the open proposals including Alice's new one that she brouhght up during the LPC 2025. He'll merge it in the Beyond References wiki.
Macros, attributes, derives, etc.
Josh brought up his work on adding more capable declarative macros for writing attributes and derives. He's asked the Rust for Linux team for what they need to stop using proc macros.
Miguel noted they've just added dependency on syn, but they would like to remove it some day if their could.
Benno provided a few cases of large macros that he thought were unlikely to be replaceable by declarative-style ones. Josh suggested there may be a way and suggested an asynchronous discussion.
The team discussed the impact of this. These hints are used in C but not yet in Rust. cold_path would be sufficient, but likely/unlikely would still be more convenient in cases where there isn't an else branch. Tyler Mandry mentioned that these can be implemented in terms of cold_path.
Niche optimizations
We discussed the feasibility of embedding data in lower bits of a pointer -- something the kernel is doing in C. This could also enable setting the top bit in the integers (which is otherwise never set) and make it represent an error in that case (and a regular pointer otherwise).
Ideally, this would be done in safe Rust, as the idea is to improve the safety of the C code in question.
Extending the niches is something Rust wants to see, but it's waiting on pattern types. There are short/medium-term options by using unsafe and wrapping it in a safe macro, but the long-term hope is to have this supported in the language.
Vendoring zerocopy
The project has interest in vendoring zerocopy. We had its maintainers Jack Wrenn and Joshua Liebow-Feeser join us to discuss this and answer our questions. The main question was about whether to vendor at all, how often should we (or will have to) upgrade, and how much of it is expected to end up in the standard library.
The project follows semver with the extended promise to not break minor versions even before 1.0.0. We could vendor the current 0.8 and we should be upgrade on our own terms (e.g. when we bring in new features) rather than being forced to.
Right now, the project is able to experiment with various approaches and capabilities. Any stdlib integration a long way away, but there is interest in integrating these to the language and libraries where appropriate.
New trait solver
There's been a long-term effort to finish the new trait solver, which will unblock a lot of things. Niko Matsakis asked about things it's blocking for Rust for Linux.
This is the list: unmovable types, guaranteed destructors, Type Alias Impl Trait (TAIT), Return Type Notation (RTN), const traits, const generics (over integer types), extern type.
2026 Project goals
This year brings in the concept of roadmaps. We now have a Rust for Linux and a few more granular Goals. We'll be adding more goals over time, but the one merged cover what we've been focusing on for now.
We spent most of the meeting going over the open Project goals, the Rust for Linux roadmap and other things we'd like to see that aren't the right shape for a goal.
Miguel Ojeda brought up the upcoming Debian 14 release (coming out probably somewhere around Q2 of 2027) and we went over each item and decided whether it's something we need to make sure is in that release or not.
Debian stable is an important milestone and the Rust version in it serves as a baseline for Rust for Linux development.
The dma_read! / dma_write! macros switched over to it. This also fixes a soundness issue 1.
Note: this is done entirely via macros and doesn't use any Field projections language features. The Field projection syntax and traits should make this more ergonomic and integrate the borrow checker so we can accept more code.
We're planning to have a design meeting with the Lang team in the last week of March.
rustfmt imports formatting and trailing slashes
We talked about the rustfmt formatting of the use statements again. While the trailing empty comment // workaround (see this update) is acceptable as a temporary measure, we need to find a long-term solution where you can configure rustfmt to accept this style.
We don't have a issue for this specific formatting yet, though it was discussed in #3361.
The next step are to create such an issue. We were hesitant to add burden to a team that's already at limit, but having the issue would let us track it from the Rust for Linux side.
Boxy asked the team for features that are most important under the const generics umbrella. This might help with prioritisation and just understanding of practical uses.
Ability to do arithmetic on const generic types: e.g. the kernel has a type Bounded which has a value and a maximum size (in bits). Both the bit width and value are const values. They want to be able to do arithmetics on these types (starting with bit shifts) that will guarantee the the result will fit within the specified size at compile time.
Argument-position const generics: right now, the const generic types must be specified in the type bound section (within the angle brackets). So for example you have to write: Bounded::<u8, 4>::new::<7>() instead of the more natural Bounded::<u8, 4>::new(7). This gets more complicated when there's const-time calculation happening rather than just a numerical constant -- in which case this also needs to be wrapped in curly brackets: { ... }.
Being generic over types other than numbers: pointers would be useful for asm_const_ptr. String literals too -- even if they're just passed through without being processed / operated on. And if going from a passthrough string makes it possible to pass through any type, that would help the team replace some typestate patterns they're using with an enum.
statx
Alice Ryhlproposed being able to create std::fs::Metadata from Linux statx syscall.
This was discussed in the Libs-API meeting and they had questions about possible evolutions of the statx ABI -- if/how it can grow in the future and how they could handle that if they wanted some of the new data available. So we discussed it in the Rust for Linux meeting.
In the end, it seems prudent to be reasonably defensive rather than relying on the syscall pre-filling default values.
Alice Ryhlproposed an opaque statx struct that would give the stdlib a way to decide on the struct's size, pre-filled contents and mask.
Miguel Ojeda suggested contacting Christian Brauner and Alexander Viro (i.e. the VFS maintainers); Josh Triplett agreed that it would be good if we can get a thread with the right people in linux-fsdevel.
zerocopy uses two traits that are both polyfills for unstable traits : KnownLayout (for ptr_metadata) and Immutable (for Freeze). It would help maintenance of zerocopy (which Rust for Linux plans to start using) if these were stabilised.
ptr_metadata is something the team wants in the kernel independently. It's possibly blocked on (or at least might have interactions with) the Sized Hierarchy work.
We also discussed the dependence/independence of the Deref and Receiver implementations, in particular whether it ever makes sense to implement Deref but notReceiver. Josh Triplett suggested gathering examples for cases like that (where you can't use the type as a Self type in the function declaration, but allow calling methods on it).
The current plan for the experiment is to have these traits separate, but have the compiler enforce that if they implement the same type, their targets are identical. This will let us open the door for any future possibilities (a supertrait / subtrait relation, or having diverging targets in the future).
We want to experiment to see where and how these traits and their possible evolution might be helpful.
null-ptr-deref
The team would like to have a (an optional) compiler guarantee, that the compiler never removes null checks on raw pointers. What can currently happen in C is that if you deref a null pointer, the compiler can do optimisations including removing any subsequent checks whether that pointer is null, because dereferencing a null pointer is undefined behaviour.
But the null check can still help prevent further bugs and in C, the kernel now disables the optimisation that would remove it.
The RFC has just been published. It has been significantly reworked since the last draft.
Notable changes:
Removed the concept of activation/de-activation. Now the semantics don't need to deal with partially allocated locals. This is less powerful optimization-wise but should still cover most cases.
Added byref/byval to call arguments to clarify how they are passed.
Added a separate section for the surface language changes to separate it from the MIR changes.
Added more details on the MIR optimization which eliminates moves.
Changed the MIR operand evaluation order to be left-to-right, except for destination places which are always evaluated last.
Added StorageLive back: we need it to mark the location where llvm.lifetime.start should be inserted, which is not the same as the location where a local is initialized. In the opsem, StorageLive doesn't actually allocate the local, that's still done when it is initialized by a write.
The prototype of this project goal is basically complete.
Current state
This project goal introduces build analysis support in Cargo, with the aim of making build behavior understandable across multiple invocations, not just a single run.
At a high level, the prototype:
Records build metadata over time, including:
rebuild reasons
timing information
relevant invocation context
Stores this data locally in a structured log format suitable for later analysis
Exposes the data via unstable cargo report subcommands, such as:
cargo report sessions - list session IDs
cargo report timings - HTML timing report
cargo report rebuilds - Why things rebuilt
See the Reference for a more thorough usage documentation
Path towards stabilization
Before this feature can be stabilized, the following unresolved questions must be answered. They might not block stabilization, but need to be evaluated if it is fine to leave for future.
cargo report commands
This is a stabilization blocker.
Currently all three report commands (sessions, rebuilds, timings)
implicitly inspect global log files when if not in a workspace.
Should this be explicit with a flag?
Should this be an error if not in a workspace?
Bikeshed on command names
Currently we have all nouns
For sessions
runs simple but ambiguous
Just log like git log
history user-friendly (docker history, shell history, though not alike)
For timings:
Not controversial, as we have --timings flag already
There is ongoing work for Adts and function pointers, both of which will land as MVPs and will need some work to make them respect semver or generally become useful in practice
Removing the 'static bound from try_as_dyn turned out to have many warts, so I'm limiting it to a much smaller subset and will have borrowck emit the 'static requirement if the other rules do not apply (instead of having an unconditional 'static requirement)
There are some known issues we'd like to address before doing a formal call for testing. Notably, improving blocking messages, fixing potential thread starvation in Cargo's job queue when locks block, and investigate increasing rlimits to reduce risk of hitting max file descriptors for large projects.
I am hopeful that these issues will be resolved over the coming month and we can do a call for testing to start gathering feedback from the community on whether the new locking strategy improves workflows.
After the initial PR from the last update was merged, we shifted our focus to resolving some of the known issues. Notably, locking blocks the Cargo job queue slowly causing thread starvation if many build units are held by another Cargo instance.
We investigated adding the ability for Cargo to "suspend" a job internally while waiting for a lock, but we felt this change was a bit invasive and did not fit well with how the job queue was designed. Instead we plan to change our design to acquire all build unit locks prior to running the job queue (see #16657).
At the same time, we have continued to refine the new build-dir to prepare it for a call for testing and eventual stabilization. (#16542, #16502, #16515, #16514)
Finally we decided to split .cargo-lock into 2 locks to allow cargo check and cargo build to run in parallel when artifact-dir == build-dir (and -Zfine-grain-locking is enabled)
I suspect this may be the last update on this goal, as the 2026 slate of goals is coming up. While I did not renew this goal for 2026, I do plan to continue work on this and eventually stabilize this within this year.
Both the MCP and the PR for the AddressSanitizer target have been merged. Next up I should prepare the MCP for the Memory- and ThreadSanitizer targets, hopefully sending out soon.
rust-lang/rust#143924 has been merged, enabling scalable vector types to be defined on nightly, and I'm working on a patch to introduce unstable intrinsics/scalable vector types to std::arch
Progress has been slow since the last update because I've been busy, but I've been working on a rebase of rust-lang/stdarch#1509, which has bitrot quite a bit. Rémy Rakic is joining me to work on the Sized Hierarchy parts of the goal.
On the scalable vector half of the goal, I've got a branch with rust-lang/stdarch#1509 rebased, though without the intrinsic-test tool having been updated - that ended up being tricky and we've agreed to do it as a follow-up. We've opened rust-lang/rust#153286 with the compiler fixes that the stdarch patch requires, which should land soon (rust-lang/rust#153653 was opened and landed in the interim).
On the sized hierarchy half of the goal, Rémy Rakic has been updating our RFC such that we can discuss it in design meetings with the language team on the 18th and 25th - we'll update rust-lang/rfcs#3729 later today. We've split out the const Sized parts as a future possibility (though one we are committed to pursuing) as that has more open design questions, and we've discussed the proposed syntax and approach to migration - which are what we intend to focus on in the design meetings. He's also been working out how we can start implementing our migration strategy and help resolve blockers in other areas.
For the sized hierarchy half of the goal, Rémy Rakic and I had two design meetings with the language team (2026/03/18 and 2026/03/25) discussing the syntax/naming and migration strategy respectively.
On syntax, the language team preferred introducing an "only bounds" syntax to control opting-out of default bounds and opting-in to alternative bounds in a family of traits (described in an alternative in the RFC), but there was an open question of whether that syntax should apply to an individual bound or all of the bounds - Niko Matsakis is investigating that.
On naming, the language team also preferred the name SizeOfVal over MetaSized, and didn't like Pointee but had no better alternatives. Rémy Rakic prepared rust-lang/rust#154374 to do that renaming and started a discussion with the library team to confirm they were happy with the name, because changing it involves an amount of churn. The library team wanted to know what other traits in the hierarchy might later be introduced, as that would help inform the naming of the currently proposed traits, so Rémy Rakicwrote up a document with that information. We're holding off on doing any name changes until we find some consensus between libs and lang - who is responsible for these traits' names is a bit unclear.
On migration, the language team were largely happy with our proposed approach, and we realised that the approach proposed by lcnr for associated types might also work for our other migrations. Rémy Rakic has had meetings with lcnr to better understand that approach and to work out the next steps for implementing it.
In the context of concerns around young people’s interactions with digital technologies, the UK’s Department for Science, Innovation and Technology is consulting on additional measures to prepare young people for growing up in a digital world. Before the backdrop of users circumventing age assurance systems mandated under the UK’s Online Safety Act, the consultation considers age-gating virtual private networks (VPNs).
Mozilla’s mission is grounded in the belief that the internet must remain open and accessible to all, and that privacy and security online are fundamental human rights. We recognize that the protection of young people online is one of the most pressing and challenging questions of our time, and we are committed to supporting policy proposals that address the root causes of online harms. We are concerned, however, that blunt interventions like mandatory age assurance and restricting access to tools like VPNs are not effective in improving the protection afforded to young people online, while undermining the fundamental rights of all users.
VPNs serve as critical privacy and security tools for users across all ages. By hiding users’ IP addresses, VPNs help protect users’ location, reduce tracking and avoid IP-based profiling. People use VPNs for lots of different reasons: to connect to their school’s or employer’s network remotely, to avoid censorship or to simply protect their privacy and security online. While being able to access VPNs is especially important for vulnerable groups like activists, dissidents or journalists, VPNs improve everyone’s baseline protection online.
Young people are particularly vulnerable to online tracking, targeted advertising, and the risks that flow from personal data being collected and processed for commercial purposes without adequate consent or transparency. In a world in which young people are interacting with digital technologies as part of their realities from young ages onward, restricting young people’s access to privacy-protecting technologies is in tension with the goal of equipping them to navigate the internet safely and competently. In order to be able to develop agency and responsible habits in engaging with digital technologies, it is crucial for young people to be introduced to best practices and key safety and privacy tools as they engage with the online world.
Rather than age-gating technologies like VPNs, we believe that regulators should address the root causes of online harm by holding platforms to account, encouraging the responsible use of parental controls and investing in digital skills and a whole of society approach to digital wellbeing.
Read our full submission to the Department for Science, Innovation and Technology.
At Mozilla, we’ve long believed in giving people choice and agency over their experiences online. As power in digital markets has concentrated in a small number of large companies, there have been efforts in the US, Japan, UK, India, Korea, Brazil and elsewhere to restore competition and put choice back in people’s hands.
These efforts are at various stages, but first among them was the EU’s Digital Markets Act. Over two years since obligations came into effect, the DMA is delivering for people in some key areas.
Not everywhere. Not perfectly. And not without enforcement. But browser choice is the clearest example.
Every 10 seconds, someone picks Firefox through a DMA choice screen
Operating systems like iOS, Android, Windows, and MacOS lean on pre-installed browsers, tricky default settings, and deceptive design to make it hard for people to exercise choice and to keep independent browsers from competing on a level playing field. But where the DMA has created opportunities for genuine browser choice, people are taking it.
New Mozilla data is clear: since the rules took effect, Firefox is selected through a DMA browser choice screen every 10 seconds. That adds up to more than six million Firefox selections. And people are sticking with us: retention is five times higher when people choose Firefox through a choice screen.
Academic analysis points the same way. Independent researchers compared Firefox daily active users in the EU with 43 non-EU countries. Comparing the 15 months before and after browser choice screens rolled out on iOS, they found that Firefox daily active users (DAU) were 113% higher in the EU than it would have been without the DMA. On Android, it was 12% higher. The smaller Android effect is due to the fact that Firefox usage there started from a much higher base, and the Android rollout has been more uneven than on iOS. The research also shows that the DMA’s effect is growing over time.
Browser choice on mobile is moving, but desktop is left behind
The DMA’s work isn’t done. There remains room for improvement on mobile (including making it easier to import your data to a new browser and switch with one click). However, desktop remains largely untouched – leaving roughly 310 million desktops and laptops in the EU without equivalent browser choice. For example, Windows users are subject to deceptive design tactics and are not given an active choice. Even where choice screens exist, they are not a silver bullet; ecosystem lock-in and interoperability barriers still hold back competition and innovation.
Still, the signal is clear: when people get real browser choice, they take it and select alternatives. It’s easy for gatekeepers to dismiss this as a couple of competitors benefiting. This ignores the range of challenger browsers also reporting huge growth in the EU. What’s more, it ignores the benefit to people. DMA browser choice screens are reaching different audiences. Mozilla analysis shows that women make up a significantly higher share of Firefox selections on iOS via a choice screen than organic downloads, suggesting that choice screens may successfully reach a demographic that reports lower confidence in manually changing browser defaults. The DMA’s effects are only starting to be felt and understood.
The road ahead
Effective enforcement of the obligations is the way forward. Gatekeepers continue to test and, in many instances, openly push back against the intent of the DMA provisions. This can take the form of implementation choices that limit real user uptake, delays in rolling out effective solutions, or sustained efforts to reinterpret, weaken, or roll back key provisions.
Most evidently, privacy and security arguments are often elevated in ways that risk diverting attention from whether compliance is delivering genuine choice and competition in practice. In reality, privacy, security, and effective competition can and should be designed to work hand-in-hand. They do not always have to be traded off.
Policymakers and enforcers should remain focused on outcomes: ensuring that the DMA delivers real-world competition and user choice, and resisting efforts to dilute its impact through partial compliance or narrative reframing.
Browser choice is just the start
Mozilla’s hope is that real browser choice will become the rule, rather than the exception. And that the lessons of browser choice screens will be applied to other areas of the DMA, including data portability and interoperability. Only with full compliance – including applying the existing DMA text to AI – can the full benefits of competition and innovation be brought to people in the EU.
If you have ever used Thunderbird in Bulgarian, the subject of this month’s office hours is one of the contributors who made that possible! Office Hours hosts Heather and Monica have been lucky enough to chat with long-time localizer Bogamil Shopov at conferences like FOSDEM. Now, they’re sitting down to talk to him about how his contributor story started, and to hear the advice he has for anyone curious about being part of Thunderbird.
We’ll be back next time, checking in on Thunderbird Pro! It’s been almost a year since we sat down with members of our team making this possible. As we’ve slowly started opening up the service to our Early Birds from the waitlist, it seemed a great opportunity to learn what users can expect, now and in the future!
A Contributor Origin Story
Bogomil has been a contributor to Thunderbird from the start! Even if he didn’t like the UI in the early days, he loved our commitment to software freedom. He wanted people to have the software in their own language, and so he started localizing Thunderbird into Bulgarian. This was in the days before Pontoon, Mozilla’s localization platform, and so this wasn’t easy work! Another hurdle, which still happens, is that small language locales tend to have smaller numbers of contributors doing localizing work.
From Mentee to Mentor
Thankfully, Bogomil had unofficial mentors to help them find their way. On the localization side, he had a Bulgarian mentor who he, in turn, introduced to Mozilla and other open source projects. More experienced Mozilla contributors answered his questions as he expressed his interest in getting more involved. Bogomil points out that this need for both good onboarding docs and genuine human connection is still something all open source projects needs – and something we can keep improving!
Now Bogomil is the experienced mentor, and he’s had some key steps to helping grow the Thunderbird localizer community. He sends thank you notes to new translators and sends resources for specific computer and email terminology to new Bulgarian volunteers. He gives his mentees specific tasks to help focus their energy and excitement, and maybe even more importantly, he gives them encouragement.
This Speaker goes to 11
While Bogomil had given several public talks in Bulgarian before COVID, after 2020 he decided to try giving conference talks in English. His first talk was at Halfstack, sponsored by Mozilla, in Vienna, on what made him happy as a developer and IT person in general. He even brought a violin player on stage with him! His talk got a warm reception, and it encouraged him to keep talking about what brought him joy, whether it was using heavy metal to help him focus or his involvement with Thunderbird and open source. If you’ve ever considered giving a talk, especially about one of your passions, and hesitated, Bogomil would tell you to do it! People are more welcoming than you might think.
Tools and Advice
Bogomil still uses Pontoon for Thunderbird desktop translations, in addition to Weblate, where Thunderbird for Android and many other open source projects live. In addition to this localization platforms, he uses CoEdIt along with web-based tools that allow him to see how certain words were previously translated. And of course, he has three release channels of Thunderbird on his computer at all times, something most of the Thunderbird team understands!
From newer contributors, Bogomil has learned how language is changing and how to keep terms, like the Bulgarian word for “browser,” up to date, in addition to other feedback. His advice to new and potential volunteers is to be open to critique. This is especially true joining a project with a long history like Thunderbird, especially before wanting to change something. And he says don’t be afraid to do things and experiment, even if things go wrong.
Collected here are the most recent blog posts from all over the Mozilla community.
The content here is unfiltered and uncensored, and represents the views of individual community members.
Individual posts are owned by their authors -- see original source for licensing information.
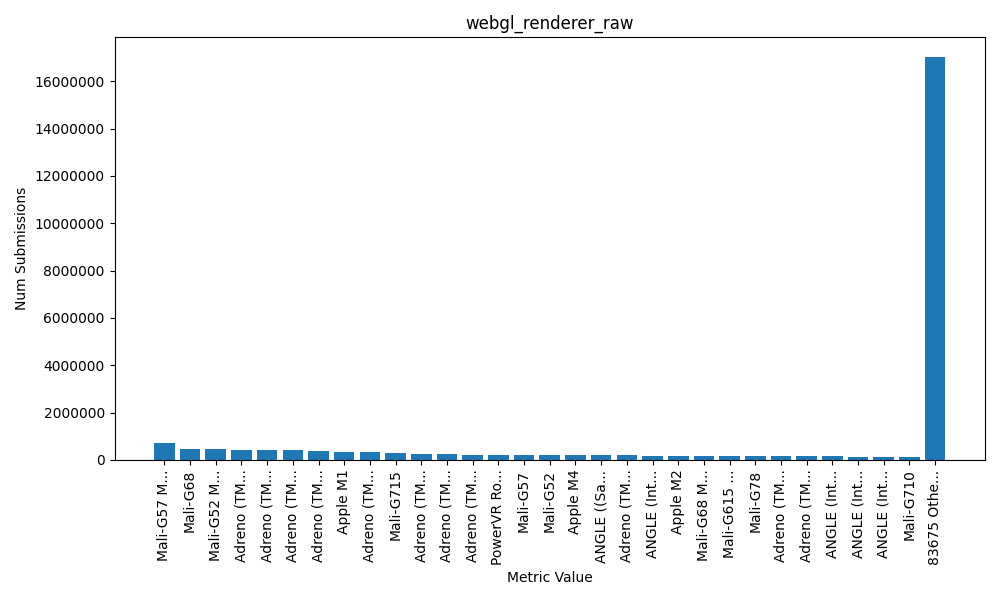
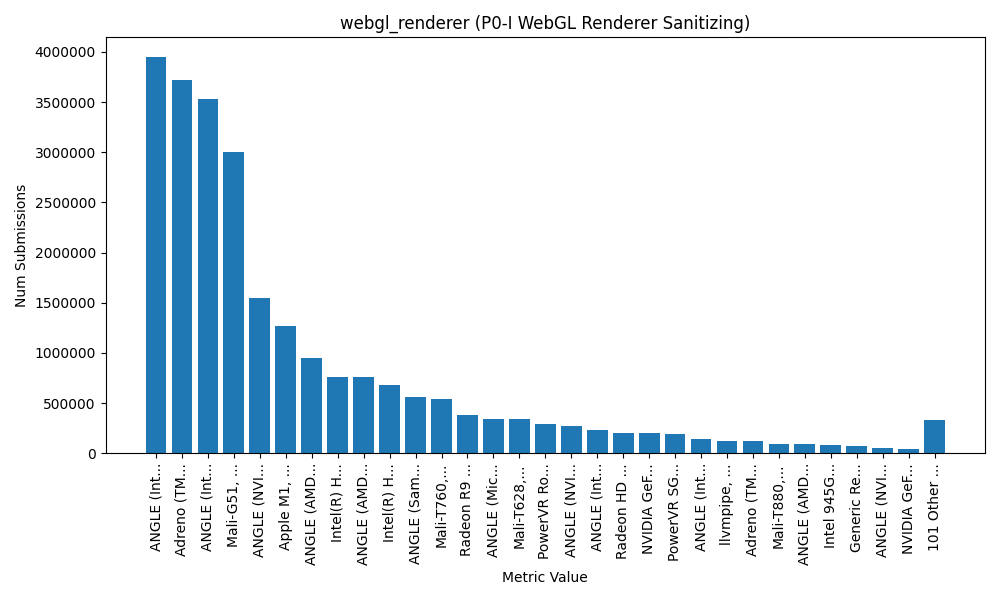
{kind=link}
{kind=link}
{kind=link}
{kind=link}
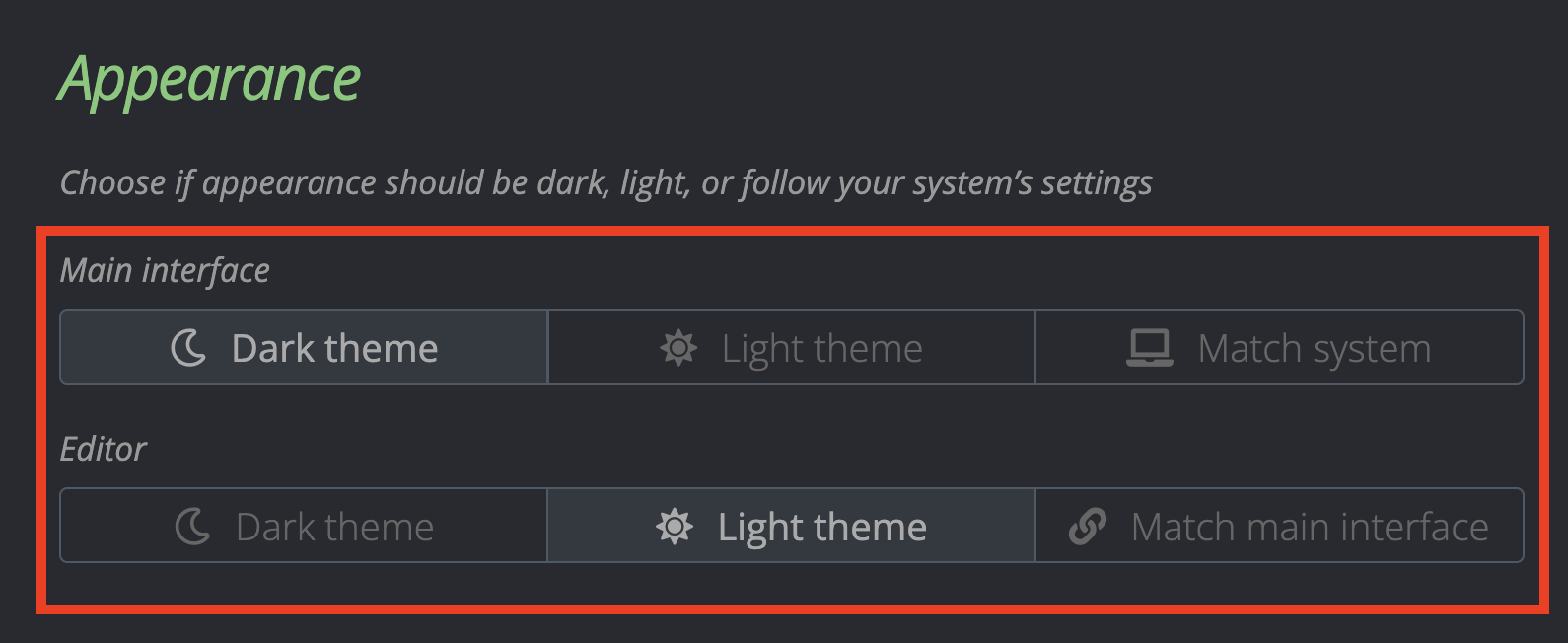{kind=link}
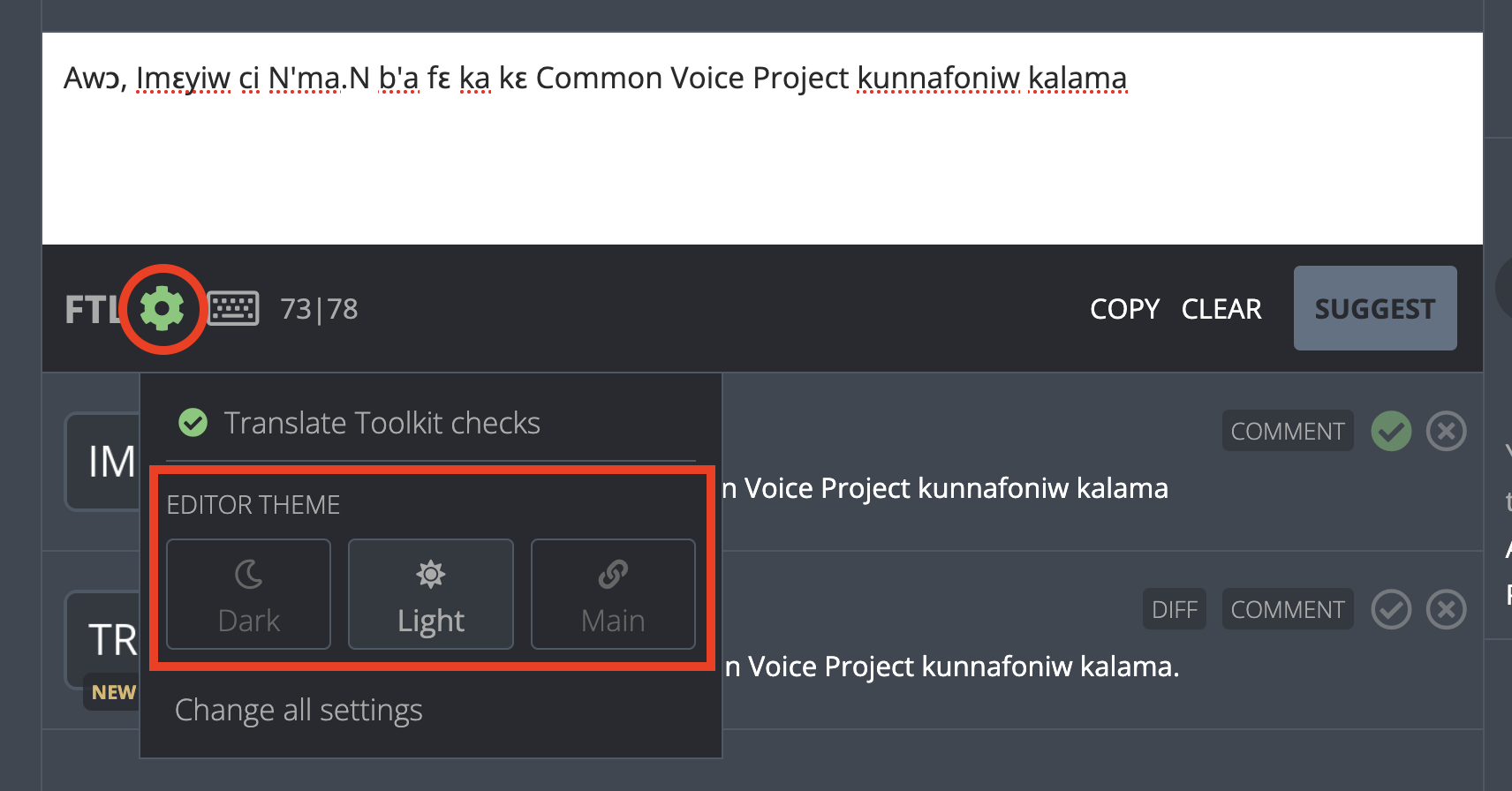{kind=link}
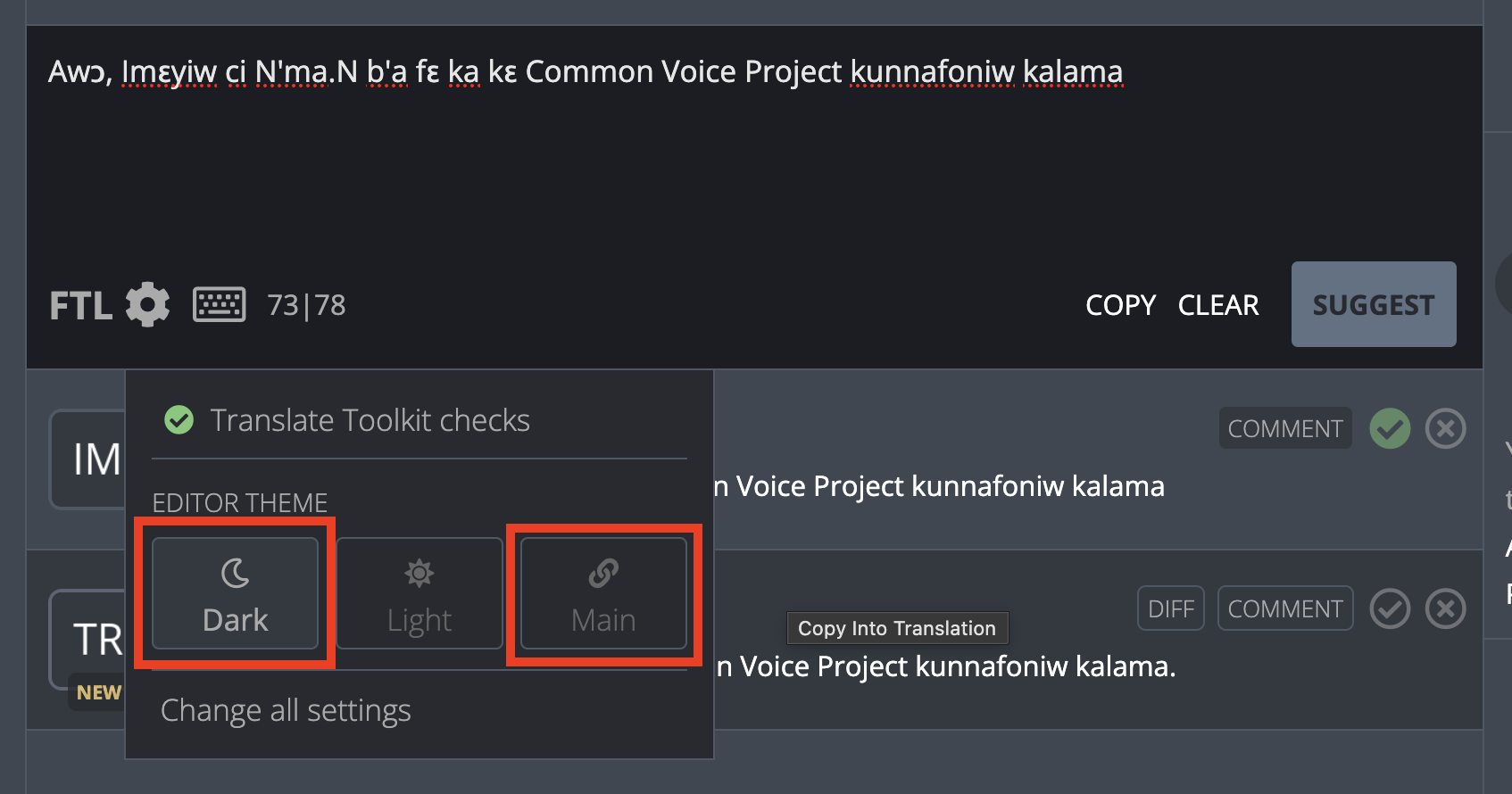{kind=link}
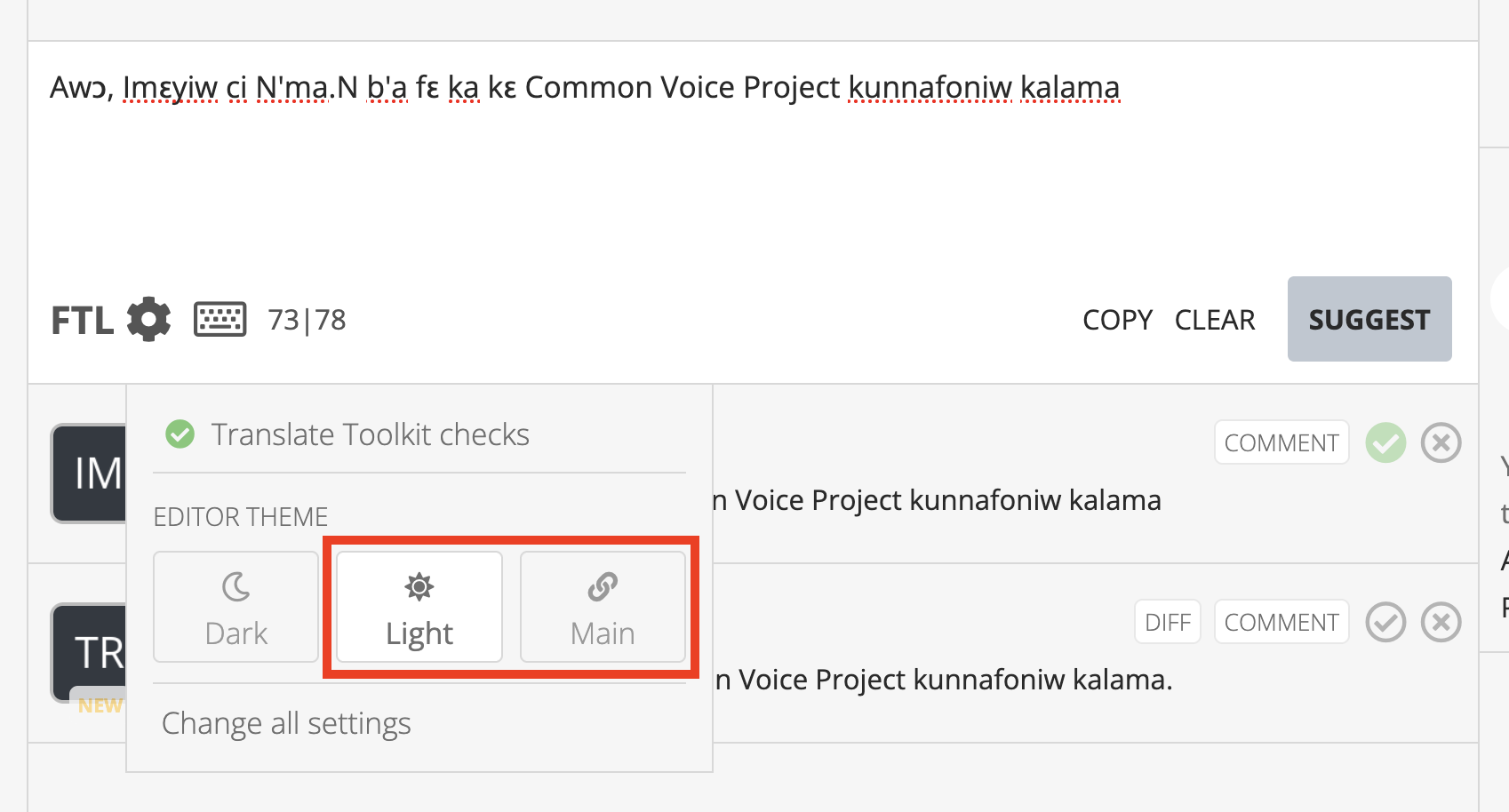{kind=link}
{kind=link}